LSE DS202W 2025: Week 5 - Lab Solutions
2024/25 Winter Term
This solution file follows the format of a Jupyter Notebook file .ipynb you had to fill in during the lab session.
⚙️ Setup
Downloading the student solutions
Click on the below button to download the student notebook.
Loading libraries and functions
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeRegressor, plot_tree
from sklearn.metrics import f1_score, root_mean_squared_error
from sklearn.ensemble import RandomForestRegressor
from xgboost import XGBRegressor
from lets_plot import *
LetsPlot.setup_html()Predicting who voted Brexit with k Nearest Neighbours (45 minutes)
Today, we are going to be demonstrating the utility of hyperparameter tuning using k-fold cross validation.
Exploring a feature space
We are going to take a look at data adapted from the European Social Survey, round 8 (ESS8)(European Social Survey European Research Infrastructure (ESS ERIC) 2023).
The ESS is a an academically-driven multi-country survey. Its stated aims are “firstly – to monitor and interpret changing public attitudes and values within Europe and to investigate how they interact with Europe’s changing institutions, secondly - to advance and consolidate improved methods of cross-national survey measurement in Europe and beyond, and thirdly - to develop a series of European social indicators, including attitudinal indicators”.
Aside from questions common to all countries, for this round of the survey, the data providers had asked participants from the UK questions around the recently-completed Brexit referendum and more specifically whether they had voted “Leave” (i.e “Brexit”) or “Remain” in the Brexit.
We will expand an example given for k nearest neighbours in Garibay Rubio et al. (2024), using two predictors. The full (adapted) data set consists of:
vtleave: Whether or not a participant voted “Brexit” or “Remain”atchctr: 0-10 attachment rating to the United Kingdomatcherp: 0-10 attachment rating to Europe
brexit = pd.read_csv("data/brexit-ess.csv")💡Tip: Don’t worry too much about the below code. All we are doing is creating a grid of potential values for illustration purposes. We somewhat adapted the code for this from here!
unique_categories = [
brexit['atchctr'].unique(),
brexit['atcherp'].unique()
]
names = ["atchctr", "atcherp"]
multiindex = pd.MultiIndex.from_product(
unique_categories,
names=names
)
brexit_grid = brexit.groupby(["atchctr","atcherp"]).mean().reset_index()
brexit_grid = (
brexit_grid
.set_index(names)
.reindex(multiindex, fill_value = np.nan)
.reset_index()
)Let’s use ggplot to explore this feature space.
(
ggplot(brexit_grid, aes("atchctr", "atcherp", colour = "vtleave")) +
geom_point(size = 5) +
scale_x_continuous(breaks = np.arange(0,11,1)) +
scale_y_continuous(breaks = np.arange(0,11,1)) +
theme(panel_grid=element_blank(),
legend_position="bottom") +
labs(x = "Attachment to the United Kingdom", y = "Attachment to Europe",
colour = "Proportion of grid that voted Brexit")
)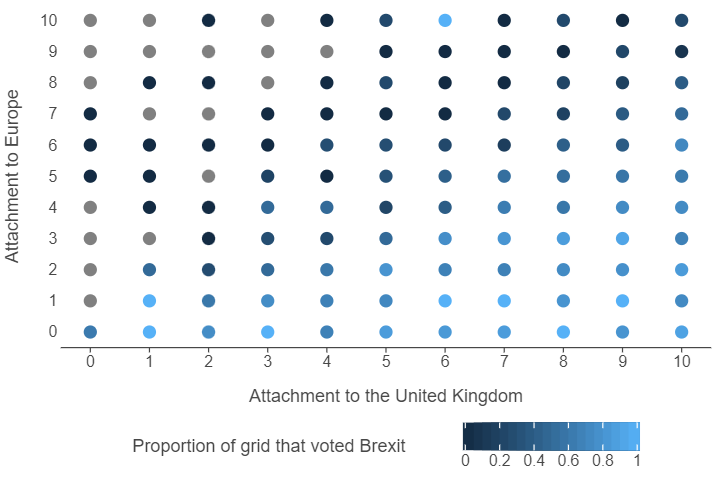
👉 NOTE: The actual data set has many features that can be used. We are only using 2 features as it is hard to visualise a feature space that has more than two dimensions.
🗣️ CLASSROOM DISCUSSION: What does this graph show? How can we identify individuals who voted Brexit? What boundaries can we draw between the two classes?
👨🏻🏫 TEACHING MOMENT: All machine learning algorithms can draw boundaries.
Introducing k Nearest Neighbours
An algorithm that can be used to classify data points is k Nearest Neighbours (kNN for short). This algorithm works by taking the neighbours of an observation and having them “vote” on whether or not the observation in question belongs to a specific class.
👉 NOTE: The “neighbours” decide the fate of a data point based on them calculating their proximity to it in relation to other data points that do not belong to their neighbourhood.
The question is, how many neighbours get to vote in the decision? This is the key hyperparameter of nearest neighbours and something that we need to experiment with. The most widely acknowledged way to experiment with hyperparameters is via k-fold cross-validation.
k-fold Cross-validation
Let’s split our sample into training and testing sets.
Pre-processing
We are going to use a simple function to pre-process the data. All that is happening is that both features are normalised, meaning we subtract the mean from each feature and divide by their standard deviation.
⚠️ WARNING: Any algorithm that uses distance metrics must use this preprocessing step as features with higher variances will play a disproportionately high amount of influence. So, when you hear “this algorithm utilizes distance measures”, think “standardise features!”
Note that you could use scikit-learn’s StandardScaler method or scipy.stats’s zscore method to standardise data instead of your own custom function (see here for details).
# Create a function that normalises variables
def normalise(var):
return (var-var.mean())/var.std()
# Drop the target from the features
X = brexit.drop("vtleave", axis = 1)
# Normalise features
X = X.apply(lambda x: normalise(x), axis=0)
# Convert features into a numpy array
X = X.to_numpy()
# Isolate the target
y = brexit["vtleave"]
# Create a train / test split
X_train, X_test, y_train, y_test = train_test_split(X,y,stratify=y,random_state=123)The below code instantiates a kNN classifier.
knn_model = KNeighborsClassifier()Creating a nearest neighbours grid
We then need to specify a hyperparameter grid.
👉 NOTE: This task often involves a lot of experimentation so do not take these values to be gospel for any future kNN models you build.
grid_knn = {"n_neighbors":[5, 25, 100, 250]}🗣️ CLASSROOM DISCUSSION:
Which number in the grid would represent the most “complex” model?
👨🏻🏫 TEACHING MOMENT:
Your teacher will present some output to see what happens when we vary k.
# Create a function that varies k in k-NN models
def vary_neighbours(n_neighbours, features, target):
knn_model = KNeighborsClassifier(n_neighbors=n_neighbours)
return knn_model.fit(features, target)
# Suggest a k grid
neigh_list = [5, 25, 100, 250]
# Loop model function of k grid
knn_models = [vary_neighbours(neighs, X, y) for neighs in neigh_list]
# Create a feature grid
brexit_feature_grid = brexit_grid.drop("vtleave",axis=1).to_numpy()
brexit_feature_grid = normalise(brexit_feature_grid)
# Apply predictions to grid
knn_grid_preds = [model.predict(brexit_feature_grid) for model in knn_models]
# Create a list of data frames of predictions
knn_grid_df = [pd.DataFrame({"preds": pred.astype(bool)}) for pred in knn_grid_preds]
# Append original feature values to list of predictions
knn_grid_df = [pd.concat([brexit_grid, pred], axis = 1) for pred in knn_grid_df]
# Concatenate to a single data frame
knn_grid_df = pd.concat(knn_grid_df, keys = neigh_list, names = ["k","n"])
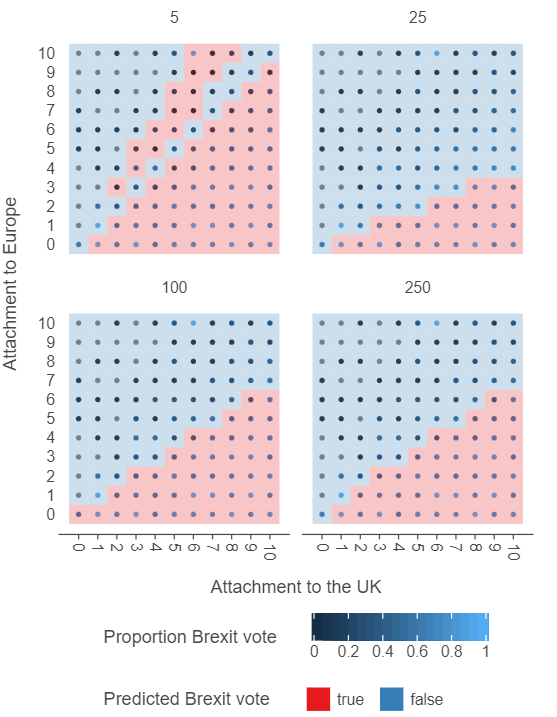
knn_grid_df = knn_grid_df.reset_index().drop("n", axis = 1)# Plot the output
(
ggplot(knn_grid_df, aes("atchctr", "atcherp", colour = "vtleave")) +
facet_wrap(facets = "k") +
geom_point(size = 2) +
geom_tile(aes("atchctr", "atcherp", fill = "preds"), alpha = 0.25) +
scale_x_continuous(breaks = np.arange(0,11,1)) +
scale_y_continuous(breaks = np.arange(0,11,1)) +
theme(panel_grid=element_blank(),
legend_position="bottom") +
labs(x = "Attachment to the UK", y = "Attachment to Europe",
colour = "Proportion Brexit vote",
fill = "Predicted Brexit vote")
)
Estimating a cross-validated model
We now have all the information we need to estimate a cross-validated model. We have
- A k-NN model instantiation (
knn_model) - A grid of hyperparameter options, expressed as a dictionary (
grid_knn)
We can now add these as the first and second arguments of GridSearchCV, and specify the number of cross-validation folds, which we will set to 10. This will result in 40 different models being run (10-folds \(\times\) 4 hyperparameter combinations). As a final step, we will ask GridSearchCV to return the f1-score to evaluate the different hyperparameter values.
knn_cv = GridSearchCV(knn_model, grid_knn, cv = 10, scoring="f1")
_ = knn_cv.fit(X_train, y_train)👉 NOTE: You may be wondering why we used _. In this context, _ is a throw-away variable that can be used to supress model messages that appear underneath code chunks.
Plot hyperparameters
After knn_cv compiles, locate the cv_results_ attribute of the model object. Try plotting the mean f1-score of for each k using a plot of your choice.
💡HINT: If you are unsure as to how to get the data into the correct format, check out the pandas introduction in the week 1 lab.
knn_output = pd.DataFrame(knn_cv.cv_results_)
(
ggplot(knn_output, aes("param_n_neighbors", "mean_test_score")) +
geom_line(linetype = "dashed") +
geom_point() +
labs(x = "Number of neighbours", y = "Mean f1 score")
)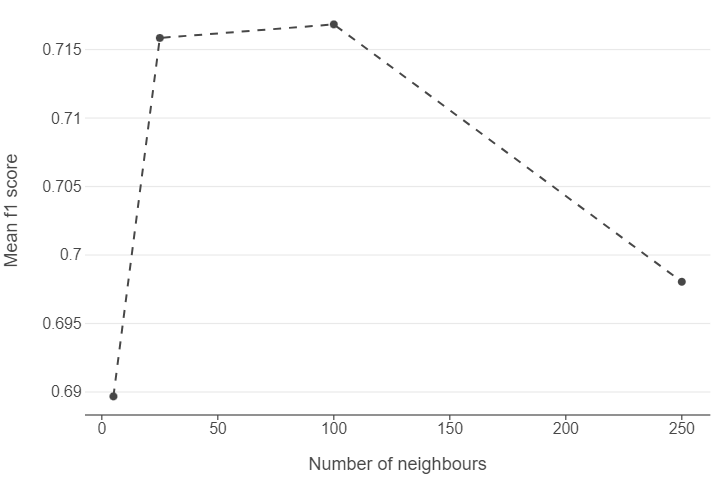
🗣️ CLASSROOM DISCUSSION: Which k is best?
Fit the best model to the full training set
We can then build a final model using the best hyperparameter combination.
# Select the best model
knn_final = KNeighborsClassifier(n_neighbors=knn_cv.best_estimator_.n_neighbors)
# Use the best parameter combination and fit on the entire training data
_ = knn_final.fit(X_train, y_train)Evaluate the model on the test set
From there, all we need to do is follow the evaluation step that we have done for previous models.
# Create predictions from k-NN model for the test set
preds_knn = knn_final.predict(X_test)
# Calculate f1-score
knn_f1 = np.round(f1_score(y_test, preds_knn),2)
# Report the result
print(f"Our best k-NN model produces an f1-score of {knn_f1} on the test set!")
Our best k-NN model produces an f1-score of 0.71 on the test set!Predicting childcare costs in US counties with tree-based models (45 minutes)
We are going to implement a decision tree, Random Forest and an XGBoost.
Exploring the data set
childcare = pd.read_csv("data/childcare-costs.csv")Our target is mcsa, defined as “Weekly, full-time median price charged for Center-Based Care for those who are school age based on the results reported in the market rate survey report for the county or the rate zone/cluster to which the county is assigned.” Click here to see a full list of variables. Let’s explore the data with a few visualisations.
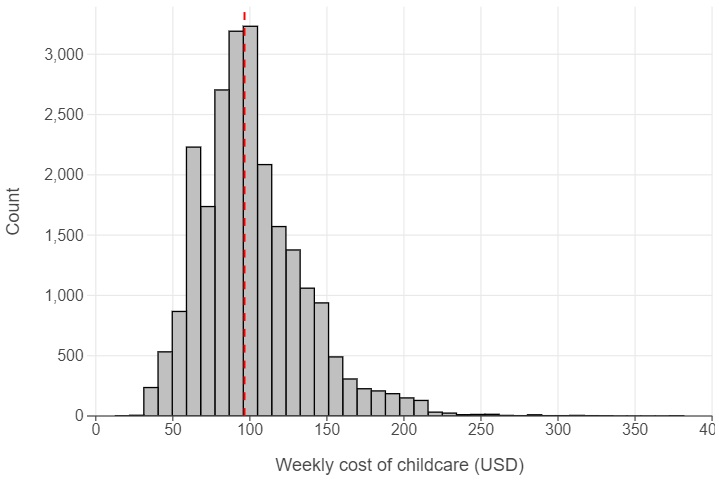
Median child care costs are ~ $96.53 a week per county
med_cost = np.median(childcare["mcsa"])
(
ggplot(childcare, aes("mcsa")) +
geom_histogram(bins = 40, fill = "lightgrey", colour = "black") +
geom_vline(xintercept = med_cost, linewidth = 3, linetype = "dashed", colour = "red") +
labs(x = "Weekly cost of childcare (USD)", y = "Count")
)
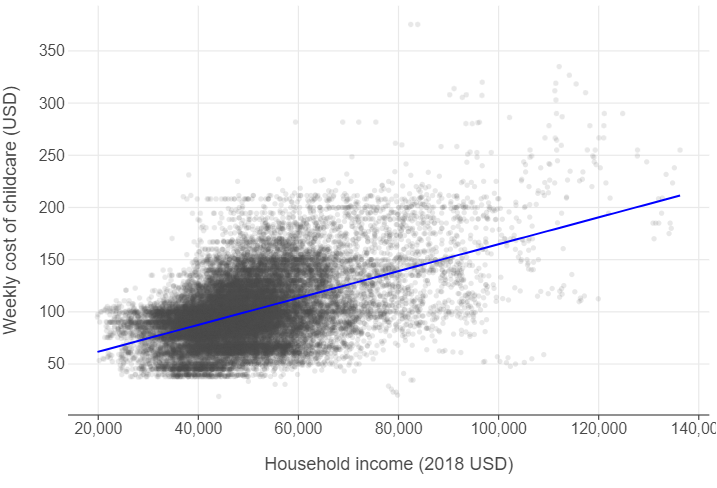
The costs of childcare increase in counties with higher median incomes
(
ggplot(childcare, aes("mhi_2018", "mcsa")) +
geom_point(alpha = 0.125, size = 2) +
geom_smooth(method = "lm", se = False, colour = "blue") +
labs(x = "Household income (2018 USD)",
y = "Weekly cost of childcare (USD)")
)
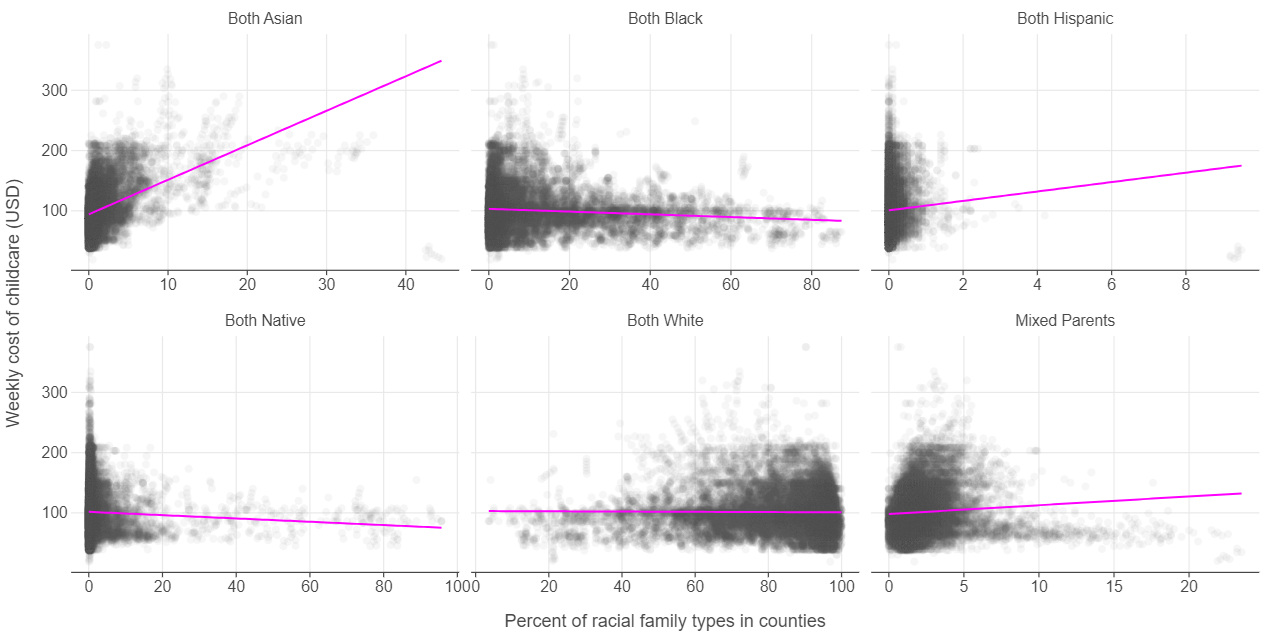
There is considerable variation in the costs of childcare based on the ethnic composition of the county
👉 NOTE: We adapted this graph from Julia Silge (click here for her analysis of the same data set using the tidymodels ecosystem in R).
selected_cols = childcare.columns.str.contains("mcsa|one_race_|two_races")
childcare_melted = pd.melt(childcare.loc[:,selected_cols],
id_vars="mcsa",
var_name="race",
value_name="perc")
def transform_category(race):
if race == "one_race_w":
return "Both White"
elif race == "one_race_b":
return "Both Black"
elif race == "one_race_i":
return "Both Native"
elif race == "one_race_a":
return "Both Asian"
elif race == "one_race_h":
return "Both Hispanic"
elif race == "two_races":
return "Mixed Parents"
childcare_melted["race"] = childcare_melted["race"].map(lambda x: transform_category(x))
(
ggplot(childcare_melted, aes("perc", "mcsa")) +
facet_wrap(facets="race", scales = "free_x") +
geom_point(alpha = 0.05) +
geom_smooth(method = "lm", se = False) +
labs(x = "Percent of racial family types in counties",
y = "Weekly cost of childcare (USD)")
)
Since Python 3.10, in addition to if...elif...else statements (see Python documentation), you also have match...case statements so you could rewrite the transform_category function as:
def transform_category(race):
match race:
case "one_race_w":
return "Both White"
case "one_race_b":
return "Both Black"
case "one_race_i":
return "Both Native"
case "one_race_a":
return "Both Asian"
case "one_race_h":
return "Both Hispanic"
case "two_races":
return "Mixed Parents"
case _:
return "Unknown Category" # Optional default case to handle unexpected inputs gracefullyCreate a grouped train / test split
If you have inspected childcare, you will see that it tracks 1,786 counties from 2008 to 2018.
📝Task: Create a train / test split using all years up to 2018 to train the model and 2018 to test the model.
# Create a list of all variables with "county" or "state" as a prefix using a logical condition
feats_to_drop = childcare.columns[childcare.columns.str.contains("county|state")]
# Use the above list to drop these variables from the data set
childcare_cleaned = childcare.drop(feats_to_drop, axis=1)
childcare_cleaned
# Use 2018 to test and all other years to train
train, test = childcare_cleaned.query("study_year < 2018"), childcare_cleaned.query("study_year == 2018")
# Split the data set into features / target
X_train, y_train = train.drop("mcsa", axis=1), train["mcsa"]
X_test, y_test = test.drop("mcsa", axis=1), test["mcsa"]Decision trees
Fit a decision tree that has a maximum depth of three levels using the appropriate function (see the first code chunk). Next, use the plot_tree function on the model, setting the feature names to the column names.
# Instantiate a decision tree for regression
dt_model = DecisionTreeRegressor(max_depth=3)
# Fit the model to the training data
dt_model.fit(X_train, y_train)
# Plot the output
_ = plot_tree(dt_model,
feature_names=X_train.columns,
fontsize=5,
precision=1,
impurity=False,
proportion=False)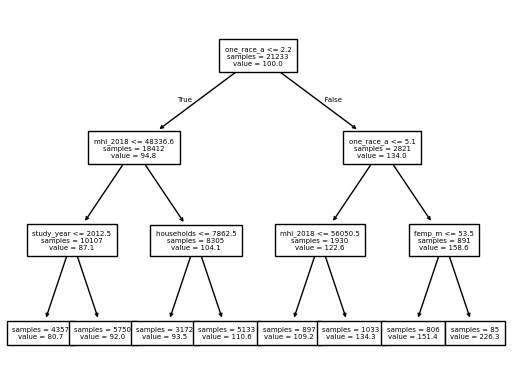
🗣️ CLASSROOM DISCUSSION: Which feature has the algorithm deemed most important for splitting the data? Can you explain what the tree is doing?
The decision tree takes a “top-down” and “greedy” approach, meaning it looks at the variable that can make the best split in the data, performs the split based on the best threshold of that variable, and then repeats the process for each split until the required depth is reached.
Evaluate the model on the test set
Let’s see how well our simple decision tree does. Here’s a function that takes five parameters:
modeltakes ascikit-learnmodel objecttest_featurestakes apandasdata frame or anumpyarray of test featurestrue_valuestakes apandasdata frame or anumpyarray of test outcomesmodel_nametakes a user-created string that specifies the model usedindextakes an integer value
The output is a 1-row data frame which shows the name of the model and it’s associated RMSE on the test set.
def metric_to_df(model, test_features, true_values, model_name, index):
preds = model.predict(test_features)
rmse = np.round(root_mean_squared_error(true_values,preds), 0)
return pd.DataFrame({"model":model_name, "rmse":rmse}, index=[index])Try using this function on the model we have built above.
dt_output = metric_to_df(dt_model,X_test,y_test,"Decision Tree",0)
print(dt_output)
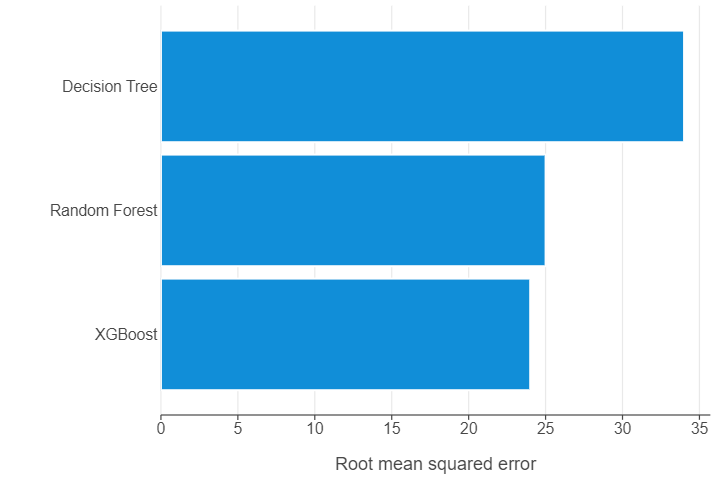
model rmse
0 Decision Tree 34.0Instantiate a random forest model
- Take a look at the library code chunk at the beginning of the notebook and instantiate the relevant model.
- Set
max_features = "sqrt" - Set
n_estimators = 1000
- Set
🗣️ CLASSROOM DISCUSSION: Why do we do this? What happens if we set max_features equal to sqrt?
By limiting the choice of variables for each decision tree to the square root of the total number of features, we ensure that different variables are randomnly selected when building our “forest.”
- Fit the model to the training data.
- Evaluate the model on the test set.
# Instantiate a random forest with the required hyperparameters
rf_model = RandomForestRegressor(max_features="sqrt", n_estimators=1000)
# Fit the model to the training data
_ = rf_model.fit(X_train, y_train)# Evaluate on the test data
rf_output = metric_to_df(rf_model,X_test,y_test,"Random Forest",1)
print(rf_output)
model rmse
1 Random Forest 25.0🗣️ CLASSROOM DISCUSSION: Do we see an improvement?
Yes, and quite a dramatic one! Test RMSE is reduced from $34 to $25.
Instantiate an XGBoost model
- Take a look at the library code chunk at the beginning of the notebook and instantiate the relevant model.
- Set
n_estimators = 1000 - Set
colsample_bytree = 0.135 - Set
learning_rate = 0.1
- Set
xgb_model = XGBRegressor(n_estimators = 1000, learning_rate = 0.1, colsample_bytree = 0.135)
_ = xgb_model.fit(X_train, y_train)# Evaluate on the test data
xgb_output = metric_to_df(xgb_model,X_test,y_test,"XGBoost",2)
xgb_output
model rmse
2 XGBoost 24.0🗣️ CLASSROOM DISCUSSION: Do we see an improvement?
Yes, but only modestly if we compare to the random forest. Test RMSE is only reduced from $25 to $24!
Which model is best?
Create a summary of your findings using either a table or a graph.
all_output = pd.concat([dt_output,rf_output,xgb_output],axis=0)
all_output = all_output.sort_values(by="rmse")(
ggplot(all_output, aes("rmse","model")) +
geom_bar(stat="identity") +
theme(panel_grid_major_y=element_blank()) +
labs(x="Root mean squared error", y="")
)