
✅ A model solution for the W07 formative
What follows is a possible solution for the W07 formative. If you want to render the .qmd that was used to generate this page for yourselves, use the download button below:
⚙️ Setup
We start, as usual, by loading libraries. Make sure, just like in the previous formative, that students load all libraries at the beginning of the file for cleaner formatting (and coding).
import pandas as pd
import numpy as np
import re
from sklearn.model_selection import train_test_split
from sklearn.metrics import balanced_accuracy_score, confusion_matrix, roc_auc_score, f1_score, precision_score, recall_score, average_precision_score
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.model_selection import GridSearchCV
from lets_plot import *
LetsPlot.setup_html()
from lets_plot.plot import gggrid
from pytablewriter import MarkdownTableWriter
import matplotlib.pyplot as plt
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from catboost import CatBoostClassifier
from sklearn.feature_selection import SelectKBest, mutual_info_classif
from imblearn.over_sampling import SMOTE
from sklearn.utils.class_weight import compute_sample_weight
import missingno as msno
import sweetviz as sv
from sklearn.impute import KNNImputer
import warnings
warnings.filterwarnings("ignore")Question 1
We first load the data
df = pd.read_csv('../../data/corruption_dataset.csv')A quick look at the columns shows some cleaning is needed:
- we’ll remove parentheses and
: - we’ll replace
%withPct,$withUSDand spaces and other special characters (e.g/) with underscores - we’ll also make sure there are no duplicate underscores in our column names
df.columnsIndex(['Country', 'Inflation, consumer prices (annual %)', 'Urbanization (%)',
'FDI (% of GDP)', 'GDP per capita, PPP (current international $)',
'Unemployment, total (% of total labor force) (modeled ILO estimate)',
'Tax revenue (% of GDP)',
'Individuals using the Internet (% of population)',
'Trade Openness (% of GDP)', 'Rule of Law Score',
'Government Effectiveness', 'Regulatory Quality',
'Real GDP Growth (% Change)', 'Voice and Accountability: Estimate',
'Political Stability and Absence of Violence/Terrorism: Estimate',
'Central government debt, total (% of GDP)',
'External debt stocks (% of GNI)',
'Public and publicly guaranteed debt service (% of exports)',
'RSF_PressFreedomIndex', 'RSF_PressFreedomIndex_PoliticalScore',
'RSF_PressFreedomIndex_EconomicScore',
'RSF_PressFreedomIndex_LegalScore', 'RSF_PressFreedomIndex_SocialScore',
'RSF_PressFreedomIndex_SafetyScore', 'ECI', 'CPI score 2022',
'LiteracyRate_TotalPopulation_Pct', 'Gini_Index',
'Domestic credit to private sector (% of GDP)'],
dtype='object')def clean_columns(name):
name = re.sub(r'%','Pct',name)
name = re.sub(r'\$','USD',name)
name = re.sub(r'\)','',name)
name = re.sub(r'[^a-zA-Z0-9]+', '_', name) # Replace non-alphanumeric sequences (incl. spaces, dashes) with _
name = re.sub(r'_+', '_', name)
return name
# Print before renaming
print("Before renaming:", df.columns.tolist())
# Apply function to all column names
df.rename(columns=lambda col: clean_columns(col), inplace=True)
# Print after renaming
print("After renaming:", df.columns.tolist())
Before renaming: ['Country', 'Inflation, consumer prices (annual %)', 'Urbanization (%)', 'FDI (% of GDP)', 'GDP per capita, PPP (current international $)', 'Unemployment, total (% of total labor force) (modeled ILO estimate)', 'Tax revenue (% of GDP)', 'Individuals using the Internet (% of population)', 'Trade Openness (% of GDP)', 'Rule of Law Score', 'Government Effectiveness', 'Regulatory Quality', 'Real GDP Growth (% Change)', 'Voice and Accountability: Estimate', 'Political Stability and Absence of Violence/Terrorism: Estimate', 'Central government debt, total (% of GDP)', 'External debt stocks (% of GNI)', 'Public and publicly guaranteed debt service (% of exports)', 'RSF_PressFreedomIndex', 'RSF_PressFreedomIndex_PoliticalScore', 'RSF_PressFreedomIndex_EconomicScore', 'RSF_PressFreedomIndex_LegalScore', 'RSF_PressFreedomIndex_SocialScore', 'RSF_PressFreedomIndex_SafetyScore', 'ECI', 'CPI score 2022', 'LiteracyRate_TotalPopulation_Pct', 'Gini_Index', 'Domestic credit to private sector (% of GDP)']
After renaming: ['Country', 'Inflation_consumer_prices_annual_Pct', 'Urbanization_Pct', 'FDI_Pct_of_GDP', 'GDP_per_capita_PPP_current_international_USD', 'Unemployment_total_Pct_of_total_labor_force_modeled_ILO_estimate', 'Tax_revenue_Pct_of_GDP', 'Individuals_using_the_Internet_Pct_of_population', 'Trade_Openness_Pct_of_GDP', 'Rule_of_Law_Score', 'Government_Effectiveness', 'Regulatory_Quality', 'Real_GDP_Growth_Pct_Change', 'Voice_and_Accountability_Estimate', 'Political_Stability_and_Absence_of_Violence_Terrorism_Estimate', 'Central_government_debt_total_Pct_of_GDP', 'External_debt_stocks_Pct_of_GNI', 'Public_and_publicly_guaranteed_debt_service_Pct_of_exports', 'RSF_PressFreedomIndex', 'RSF_PressFreedomIndex_PoliticalScore', 'RSF_PressFreedomIndex_EconomicScore', 'RSF_PressFreedomIndex_LegalScore', 'RSF_PressFreedomIndex_SocialScore', 'RSF_PressFreedomIndex_SafetyScore', 'ECI', 'CPI_score_2022', 'LiteracyRate_TotalPopulation_Pct', 'Gini_Index', 'Domestic_credit_to_private_sector_Pct_of_GDP']report = sv.analyze(df)
report.show_notebook()msno.matrix(df)
Most variables with missing values i.e Inflation_consumer_prices_annual_Pct, FDI_Pct_of_GDP, Unemployment_total_Pct_of_total_labor_force_modeled_ILO_estimate, Individuals_using_the_Internet_Pct_of_population, and Trade_Openness_Pct_of_GDP have a missing value percentage in the single digits.
A few other variables have missing values percentages below 40%:
Domestic_credit_to_private_sector_Pct_of_GDP(16%)External_debt_stocks_Pct_of_GNI(36%)Public_and_publicly_guaranteed_debt_service_Pct_of_exports(37%)Tax_revenue_Pct_of_GDP(31%)
The variable with the most missing values is Central_government_debt_total_Pct_of_GDP with 66% missing values.
The missingness patterns of External_debt_stocks_Pct_of_GNI and Public_and_publicly_guaranteed_debt_service_Pct_of_exports appear to be correlated as do the patterns of Inflation_consumer_prices_annual_Pct and FDI_Pct_of_GDP. Tax_revenue_Pct_of_GDP and Domestic_credit_to_private_sector_Pct_of_GDP also seem to be correlated. The missingness mechanism is likely to be missing at random (MAR).
So, unless we don’t use the features with missing values in our analysis, it looks highly likely we’ll have to perform imputation prior to our modeling and since most of the features (except Country, which we won’t be using in our analysis) are numeric, we could use KNN imputation or multiple imputation.
Question 2
Let’s create the target variable and check the frequency of its two values
df["corruption"] = np.where(df["CPI_score_2022"] >= 50, 0, 1) # 0 = NotCorrupt, 1 = Corrupt
# Check class distribution
value_counts = df["corruption"].value_counts()
percentages = (value_counts / len(df)) * 100
writer = MarkdownTableWriter()
writer.table_name = "Class Distribution"
writer.headers = ["Corruption", "Count", "Percentage"]
writer.value_matrix = [[label, count, f"{percentages[label]:.2f}%"] for label, count in value_counts.items()]
# Print Markdown table
writerClass Distribution
| Corruption | Count | Percentage |
|---|---|---|
| 1 | 69 | 67.65% |
| 0 | 33 | 32.35% |
# Visualizing corruption classification
p = (ggplot(df, aes(x="corruption"))
+ geom_bar(fill="orange")
+ ggtitle("Distribution of Corruption Classes")
+ scale_x_continuous(breaks=[0, 1]) # Only show graduations at 0 and 1
)
p.show()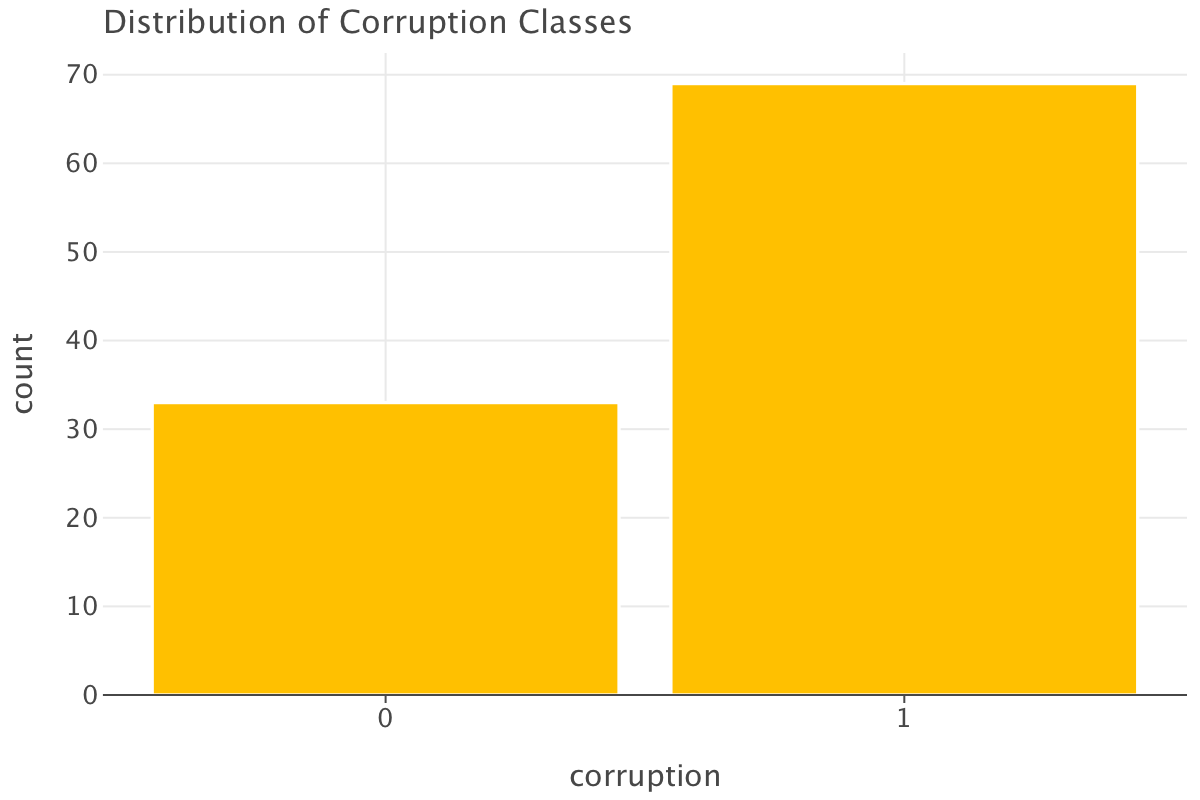
As you can see, the classes in our data are heavily imbalanced with “corrupt” countries overrepresented in the dataset (is that a surprise?😅). We’ll have to be mindful of that when training our models and/or when evaluating them.
Question 3
For the purpose of this question, we’ll use all features to do our classification except for CPI_score_2022 (it was used to define our target variable corruption) and Country (we don’t our model to be too specific to this variable).
# Select features and target variable
features = df.drop(columns=["Country", "CPI_score_2022", "corruption"]) # Remove non-predictive columns
target = df["corruption"]features.dtypesInflation_consumer_prices_annual_Pct float64
Urbanization_Pct float64
FDI_Pct_of_GDP float64
GDP_per_capita_PPP_current_international_USD float64
Unemployment_total_Pct_of_total_labor_force_modeled_ILO_estimate float64
Tax_revenue_Pct_of_GDP float64
Individuals_using_the_Internet_Pct_of_population float64
Trade_Openness_Pct_of_GDP float64
Rule_of_Law_Score float64
Government_Effectiveness float64
Regulatory_Quality float64
Real_GDP_Growth_Pct_Change float64
Voice_and_Accountability_Estimate float64
Political_Stability_and_Absence_of_Violence_Terrorism_Estimate float64
Central_government_debt_total_Pct_of_GDP float64
External_debt_stocks_Pct_of_GNI float64
Public_and_publicly_guaranteed_debt_service_Pct_of_exports float64
RSF_PressFreedomIndex object
RSF_PressFreedomIndex_PoliticalScore object
RSF_PressFreedomIndex_EconomicScore object
RSF_PressFreedomIndex_LegalScore object
RSF_PressFreedomIndex_SocialScore object
RSF_PressFreedomIndex_SafetyScore object
ECI float64
LiteracyRate_TotalPopulation_Pct float64
Gini_Index float64
Domestic_credit_to_private_sector_Pct_of_GDP float64
dtype: objectdf.RSF_PressFreedomIndex0 38,27
1 56,41
2 57,17
3 77,28
4 68,97
...
97 72,74
98 72,03
99 26,11
100 55,4
101 44,94
Name: RSF_PressFreedomIndex, Length: 102, dtype: objectAll columns linked to the Press Freedom Index are of type object. Furthermore, the numbers in those columns have decimals represented with commas instead of dots (French convention).
Before we proceed further (i.e training/test split, imputation and modelling), we need one extra step: we need to ensure our feature columns are all of the right type i.e no string columns camouflaging as numeric columns! In particular, we’ll need to convert those columns linked to the Press Freedom Index to the right format.
def convert_object_columns_to_numeric(data):
#Convert all object columns with numbers stored as '39,45' into numeric format.
#takes a dataframe as a parameter
obj_cols = data.select_dtypes(include=["object"]).columns # extracts the columns of type "object" in the dataframe
data[obj_cols] = data[obj_cols].replace(",", ".", regex=True).astype(float) #replace commas by dots in the values of the columns before making those values of type "float"
return data
features = convert_object_columns_to_numeric(features)
features.head()| Inflation_consumer_prices_annual_Pct | Urbanization_Pct | FDI_Pct_of_GDP | GDP_per_capita_PPP_current_international_USD | Unemployment_total_Pct_of_total_labor_force_modeled_ILO_estimate | Tax_revenue_Pct_of_GDP | Individuals_using_the_Internet_Pct_of_population | Trade_Openness_Pct_of_GDP | Rule_of_Law_Score | Government_Effectiveness | … | RSF_PressFreedomIndex | RSF_PressFreedomIndex_PoliticalScore | RSF_PressFreedomIndex_EconomicScore | RSF_PressFreedomIndex_LegalScore | RSF_PressFreedomIndex_SocialScore | RSF_PressFreedomIndex_SafetyScore | ECI | LiteracyRate_TotalPopulation_Pct | Gini_Index | Domestic_credit_to_private_sector_Pct_of_GDP | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NaN | 26.616 | NaN | 2122.995815 | 14.100 | NaN | NaN | 72.885470 | -1.659846 | -1.880035 | … | 38.27 | 44.65 | 43.88 | 42.54 | 43.33 | 16.96 | -1.199298 | 37.3 | 31.00 | NaN |
| 1 | 6.725203 | 63.799 | 7.579342 | 19429.921317 | 10.137 | NaN | 82.6137 | 84.698064 | -0.165585 | 0.064541 | … | 56.41 | 50.55 | 29.39 | 68.77 | 66.60 | 66.75 | -0.258308 | 99.0 | 29.42 | 33.791246 |
| 2 | 21.355290 | 68.081 | -6.320564 | 7924.888806 | 14.602 | NaN | 39.2935 | 69.691071 | -1.022036 | -1.026034 | … | 57.17 | 52.83 | 35.03 | 61.11 | 73.00 | 63.87 | -0.468852 | 72.0 | 51.27 | 8.628867 |
| 3 | NaN | 92.347 | 2.402155 | 29597.693843 | 6.805 | 11.122869 | 88.3754 | 31.547708 | -0.482352 | -0.283490 | … | 77.28 | 76.36 | 51.53 | 90.68 | 85.75 | 82.06 | -0.300466 | 99.0 | 37.80 | NaN |
| 4 | 8.640911 | 63.573 | 4.999916 | 19161.370051 | 13.379 | 21.827155 | 77.0277 | 101.410778 | -0.169516 | -0.314792 | … | 68.97 | 66.26 | 44.44 | 77.88 | 76.33 | 79.91 | 0.183791 | 99.8 | 27.94 | 52.553843 |
5 rows × 27 columns
After splitting our data into training/test set (while being careful to stratify our split by target variable to preserve the proportions of classes between training and test sets since we have class imbalance), we’ll perform imputation using KNN imputation (we do the imputation on training and test set separately to avoid data leakage).
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(features, target, test_size=0.2, random_state=42, stratify=target)
imputer = KNNImputer(n_neighbors= 3)
X_train_imp = imputer.fit_transform(X_train)
X_train_imp = pd.DataFrame(X_train_imp, columns=X_train.columns) # by default, KNNImputer returns an array, so you have to convert back to a Dataframe with the right column labeling
X_test_imp = imputer.transform(X_test)
X_test_imp = pd.DataFrame(X_test_imp, columns=X_test.columns)We’ll build a decision tree as a baseline model:
- it’s an interpretable model that doesn’t require pre-processing (e.g scaling) before being used
- we’re also not making any assumption about linearity here
Note that we could also have used a logistic regression (also interpretable, might have worked a bit better with scaling but assumes linearity implicitly).
# Baseline Model: Decision Tree Classifier
baseline_model = DecisionTreeClassifier(random_state=42)
baseline_model.fit(X_train_imp, y_train)
# Predictions
y_pred = baseline_model.predict(X_test_imp)
y_pred_train = baseline_model.predict(X_train_imp)
# Performance evaluation
print("Baseline Model Performance:")
bal_accuracy_test=round(balanced_accuracy_score(y_test, y_pred),2)
bal_accuracy_train=round(balanced_accuracy_score(y_train, y_pred_train),2)
f1_test=round(f1_score(y_test, y_pred),2)
f1_train=round(f1_score(y_train, y_pred_train),2)
precision_test=round(precision_score(y_test, y_pred),2)
precision_train=round(precision_score(y_train, y_pred_train),2)
recall_test=round(recall_score(y_test, y_pred),2)
recall_train=round(recall_score(y_train, y_pred_train),2)
auc_test=round(roc_auc_score(y_test, y_pred),2)
auc_train=round(roc_auc_score(y_train, y_pred_train),2)
auc_pr_test=round(average_precision_score(y_test, y_pred),2)
auc_pr_train=round(average_precision_score(y_train, y_pred_train),2)
writer = MarkdownTableWriter()
writer.table_name = "Baseline Model Performance"
writer.headers = ["Metric", "Training set", "Test set","Drop between training and test set"]
writer.value_matrix = [["Balanced accuracy", f"{bal_accuracy_train:.2f}", f"{bal_accuracy_test:.2f}",f"{(bal_accuracy_train-bal_accuracy_test)*100:.0f}%"],
["F1 score", f"{f1_train:.2f}", f"{f1_test:.2f}",f"{(f1_train-f1_test)*100:.0f}%"],
["Precision", f"{precision_train:.2f}", f"{precision_test:.2f}",f"{(precision_train-precision_test)*100:.0f}%"],
["Recall", f"{recall_train:.2f}", f"{recall_test:.2f}",f"{(recall_train-recall_test)*100:.0f}%"],
["AUC", f"{auc_train:.2f}", f"{auc_test:.2f}",f"{(auc_train-auc_test)*100:.0f}%"],
["AUC-PR", f"{auc_pr_train:.2f}", f"{auc_pr_test:.2f}",f"{(auc_pr_train-auc_pr_test)*100:.0f}%"]]
writerBaseline Model Performance:Baseline Model Performance
| Metric | Training set | Test set | Drop between training and test set |
|---|---|---|---|
| Balanced accuracy | 1 | 0.89 | 11% |
| F1 score | 1 | 0.93 | 7% |
| Precision | 1 | 0.93 | 7% |
| Recall | 1 | 0.93 | 7% |
| AUC | 1 | 0.89 | 11% |
| AUC-PR | 1 | 0.91 | 9% |
# Define a helper function to create the confusion matrix in long format
def confusion_matrix_long(y_true, y_pred, dataset_name):
# Compute confusion matrix and convert to a DataFrame
conf_matrix = confusion_matrix(y_true, y_pred)
conf_matrix_df = pd.DataFrame(
conf_matrix,
columns=["Predicted 0", "Predicted 1"],
index=["Actual 0", "Actual 1"]
)
# Melt the DataFrame to long format
conf_matrix_long = conf_matrix_df.reset_index().melt(
id_vars="index", value_vars=["Predicted 0", "Predicted 1"]
)
conf_matrix_long.columns = ["Actual", "Predicted", "Count"]
# Add a column to label the dataset
conf_matrix_long['Dataset'] = dataset_name
# Define the mapping of coordinates to labels
label_map = {
("Actual 0", "Predicted 0"): "TN",
("Actual 0", "Predicted 1"): "FP",
("Actual 1", "Predicted 0"): "FN",
("Actual 1", "Predicted 1"): "TP",
}
# Create an annotation column combining the label and the count
conf_matrix_long['Annotation'] = conf_matrix_long.apply(
lambda row: f"{label_map[(row['Actual'], row['Predicted'])]}: {row['Count']}", axis=1
)
return conf_matrix_long
# Create long-format data for both training and test sets
conf_matrix_long_train = confusion_matrix_long(y_train, y_pred_train, "Train")
conf_matrix_long_test = confusion_matrix_long(y_test, y_pred, "Test")
# Create the confusion matrix plot with facetting for Train and Test
conf_matrix_plot = (
ggplot(conf_matrix_long_train, aes(x='Predicted', y='Actual', fill='Count'))
+ geom_tile()
+ geom_text(aes(label='Annotation'), size=10, color='black', vjust=0.5, hjust=0.5)
+ scale_fill_gradient(low='#ffeee0', high='#00A693') # High end is PersianGreen
+ ggtitle('Confusion Matrix (Training set)')
+ xlab('Predicted')
+ ylab('Actual')
+ coord_fixed(ratio=1)
+ theme_minimal()
+ theme(
legend_position='right',
plot_margin=0 # you had this to help with spacing
)
)
conf_matrix_plot_test = (
ggplot(conf_matrix_long_test, aes(x='Predicted', y='Actual', fill='Count'))
+ geom_tile()
+ geom_text(aes(label='Annotation'), size=10, color='black', vjust=0.5, hjust=0.5)
+ scale_fill_gradient(low='#ffeee0', high='#00A693') # High end is PersianGreen
+ ggtitle('Confusion Matrix (Test set)')
+ xlab('Predicted')
+ ylab('Actual')
+ coord_fixed(ratio=1)
+ theme_minimal()
+ theme(
legend_position='right',
plot_margin=0 # you had this to help with spacing
)
)
gggrid([conf_matrix_plot, conf_matrix_plot_test], ncol=2)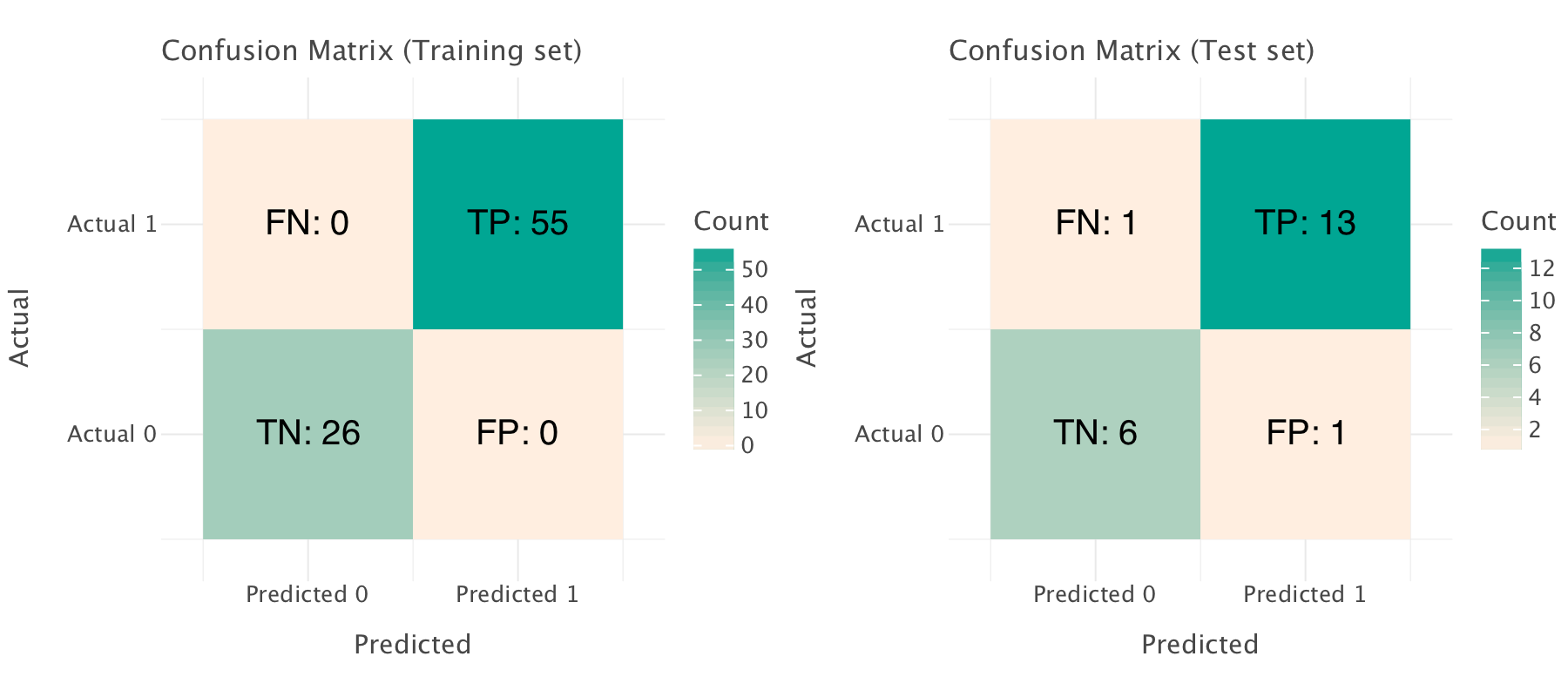
Let’s step back a bit:
- a true positive is a country which is “corrupt” and that is classified as “corrupt” by the model
- a true negative is a country which is “not corrupt” classified as “not corrupt” by the model
- a false negative is a “corrupt” country classified as “not corrupt” (the consequence potential misappropriation of resources)
- a false positive is a country which is “not corrupt” which classified as “corrupt” by the model (the consequence loss of reputation and higher cost of transactions/higher barriers for contracts)
Which is most damageable false positives or false negatives? In this case, both might be equally damageable…
Given that there are more positive instances in our dataset, our model performs a bit worse on negative instances than on positive instances (based on the test set): that is due to class imbalance.
The model seems to perform perfectly on the training set on the basis on both metrics and confusion matrix. However, it is more likely that the model memorized the training set perfectly and that that there is a pattern of overfitting. The drop of performance across all metrics between training and test set (albeit moderate) confirms the probable overfitting: the model generalizes relatively well but still overfits to some degree. We trained our model on a small dataset with too many features (81 observations in the training set and a total of 27 features) so it is likely that the model may have found patterns that are too dataset-specific rather than general.
plt.figure(figsize=(15, 10))
plot_tree(baseline_model, feature_names=X_train_imp.columns.tolist(),
class_names=["0", "1"], filled=True, rounded=True)
plt.show()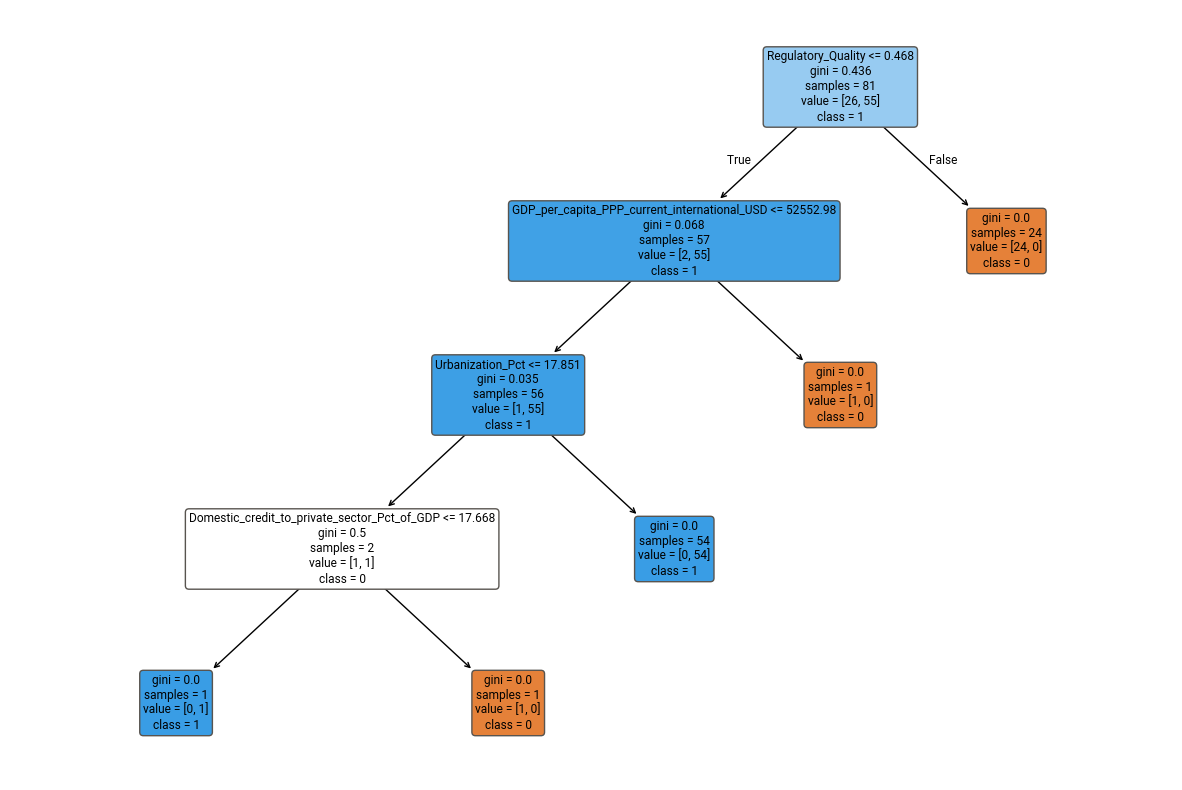
What does this tree mean?
This decision tree is a graphical representation of our baseline model and shows how it classifies our observations (i.e countries) into our two classes of interest (class 0 i.e not corrupt and class 1 i.e corrupt) based on the economic and governance-related indicators we have at hand. The model starts by evaluating Regulatory Quality, which is the most influential factor.
If Regulatory_Quality is high (above 0.468), the model directly classifies the observation (i.e country) as class 0 (i.e not corrupt) with full certainty (Gini = 0, pure split). If Regulatory_Quality is low (≤ 0.468), the next decision is based on GDP per capita (PPP):
- If GDP per capita is high (above $52,552.98), the model directly classifies the observation (i.e country) as class 1 (i.e corrupt) with complete certainty.
- If GDP per capita is lower, the model further refines the decision using Urbanization % and, in rare cases, Domestic credit to the private sector (% of GDP).
This tree suggests that countries with lower regulatory quality and lower GDP per capita may be more heterogeneous, requiring further feature splits for classification.
Some splits result in pure leaves (Gini = 0), meaning the model may be too certain about classifications, which is a sign of overfitting. The tree may have memorized training patterns instead of generalizing well.
However, the tree is not excessively deep, and it pruned itself early, meaning it may still generalize to some degree.
# Get feature importances
importances = baseline_model.feature_importances_
feature_names = X_train_imp.columns
# Convert to DataFrame and sort
feat_imp_df = pd.DataFrame({'Feature': feature_names, 'Importance': importances})
feat_imp_df = feat_imp_df.sort_values(by='Importance', ascending=True)
# Optional: Remove very small importance values for clarity
feat_imp_df = feat_imp_df[feat_imp_df['Importance'] > 0.001]
# Create horizontal bar plot with better spacing
p = (ggplot(feat_imp_df, aes(x="Feature", y="Importance")) +
geom_bar(stat='identity', fill="orange") +
coord_flip() + # Flip bars horizontally
ggtitle("Feature Importance in Decision Tree") +
theme(axis_text_y=element_text(size=12), # Reduce y-axis label size
axis_text_x=element_text(size=12))) # Increase x-axis label size
# Set figure size
p += ggsize(1000, 600) # Width=1000px, Height=600px
p.show()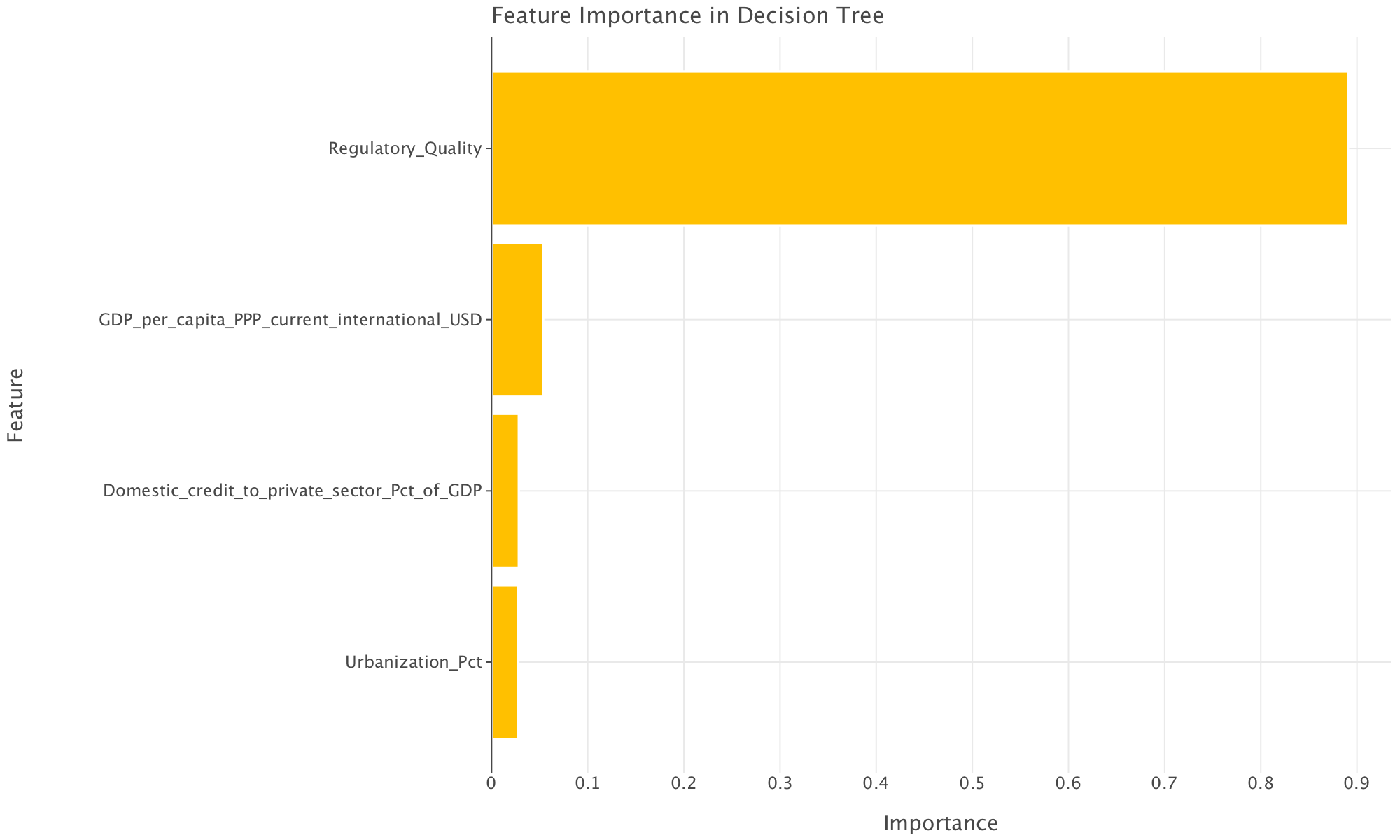
A further look at feature importance importance suggests (just like the decision tree above) that the tree only really used 4 features for classification: regulatory quality, GDP per capita, domestic credit to private sector and percentage of urbanization. All these features (except perhaps the percentage of urbanization) seem to point to the fact that a thriving private sector (and a thriving economy) are hallmarks of a country with low levels of corruption (which intuitively makes sense).
To reduce overfitting, we could without loss reduce the features we are using since many appear not to be contributing to the model. We could also use ensemble methods (e.g XGBoost, LightGBM or CatBoost or RandomForest). We could also consider tuning the hyperparameters of the tree (e.g max depth, minimum samples per leaf or cost complexity) to prune the tree further, though this likely would have a limited effect since the tree
Question 4
Note that, in this question, you were obviously allowed to use RandomForest models (or Decision Tree models -if they weren’t used in question 3) as examples of tree models. And you could also choose KNN models, variations of SVMs and LogisticRegression (as long as it differed from your baseline from question 3). I am just writing a solution with XGBoost, LightGBM and CatBoost to show other possible models especially since boosted tree models don’t require much pre-processing (i.e no need for scaling and are generally tolerant to missing values), retain some interpretability (they provide feature importance), overfit less than decision trees and Random Forest and tend to perform very well in general (when tuned correctly).
In question 3, we observed that most of the features in our model didn’t appear to contribute to our decision tree model. Furthermore, the number of initial features we chose (27) was very large compared to the number of observations in our training set (81). We already observed some possible overfitting in decision tree because of this.
If we try out other models, this might lead to:
- Overfitting once again: The model might learn noise rather than patterns, reducing generalization.
- Higher computational cost: More features would mean more complex calculations.
- Multicollinearity: Redundant or highly correlated features could negatively impact model performance.
So, before we try out other models, we need to reduce the number of features we will use. We could go back to the literature and weed out features.
Another (simple) method we’ll attempt here is to use mutual information (MI) to select our features1. Mutual Information measures how much information a feature shares with the target. It is a measure of dependency between a feature and the target variable. It captures non-linear relationships that traditional correlation metrics (like Pearson’s correlation) might miss. Features with higher MI scores contribute more information to predicting the target variable.
We’ll use the SelectKBest method to automate feature selection. The SelectKBest method works by:
- Calculating the mutual information score for each feature in relation to the target.
- Ranking the features based on their MI scores.
- Retaining the top K features (in this case, we’ll go for
k=9) that provide the most predictive value.
# Define the number of features to keep
n_features_to_keep = 9
# Apply SelectKBest with mutual information
selector = SelectKBest(score_func=mutual_info_classif, k=n_features_to_keep)
X_train_selected = selector.fit_transform(X_train_imp, y_train)
X_test_selected = selector.transform(X_test_imp)
# Get the selected feature names
selected_features = X_train_imp.columns[selector.get_support()]
print("Selected features:", selected_features)Selected features: Index(['GDP_per_capita_PPP_current_international_USD',
'Individuals_using_the_Internet_Pct_of_population', 'Rule_of_Law_Score',
'Government_Effectiveness', 'Regulatory_Quality',
'Voice_and_Accountability_Estimate',
'Political_Stability_and_Absence_of_Violence_Terrorism_Estimate',
'Central_government_debt_total_Pct_of_GDP',
'External_debt_stocks_Pct_of_GNI'],
dtype='object')Once again, Regulatory Quality and GDP per capita look like important features but the rest are different from the features previously important in our decision tree.
A quick explanation of the code block below before we interpret its results
- Model Definition (
models¶m_griddictionaries)
models: This dictionary contains the names of the models we’ll train as keys (“XGBoost”, “LightGBM”, “CatBoost”) and the corresponding classifier instances as values. These classifiers are the models (i.e the Python methods) we intend to train and evaluate.param_grid: This dictionary holds the hyperparameter grids for each model, which will be used during grid search to tune themodels. Each model has its own set of hyperparameters, with lists of values to search over.
- Metrics Dictionary (
metrics)
metrics: This dictionary defines the performance metrics we use to evaluate our models. The names of the metrics appear as keys of the dictionary: “Balanced Accuracy”, “F1 Score”, “Precision”, “Recall”, “AUC”, and “AUC-PR”. Each metric is mapped to the corresponding method fromsklearn.metrics.
Helper functions
calculate_metricsThis function calculates the evaluation metrics for both the training and test setsInput:
y_trainandy_pred_trainfor the training set (i.e the actual value of the target variable for the training set and the value of target variable predicted by the model for the training set)y_testandy_pred_testfor the test set (i.e the actual value of the target variable for the test set and the value of target variable predicted by the model for the test set)metrics: a dictionary of metric names and corresponding functions.Output:
Two dictionaries:
train_metricsandtest_metrics, containing metric names as keys and the metric values for the training and test sets (respectively) as values.create_confusion_matricesThis function generates confusion matrices for both the training and test datasets using the
confusion_matrix_longfunction, which formats the confusion matrix into a long format suitable for plotting (see Question 3 for the definition of this function).Input:
model_name: Name of the model (e.g., “XGBoost”).y_train,y_pred_train: True and predicted values for the training set.y_test,y_pred_test: True and predicted values for the test set.Output:
A list of two plots: one for the confusion matrix on the training set, and one for the test set.
evaluate_single_modelThis function:
Performs grid search to tune the hyperparameters of the model.
Trains the model on the selected training data.
Makes predictions on both the training and test sets.
Calculates and stores performance metrics for both the training and test sets using the
calculate_metricsfunction.Generates confusion matrix plots for the model’s predictions.
Input:
model_name: Name of the model being evaluated.model: The model instance to be evaluated (e.g.,XGBClassifier).X_train_selected,X_test_selected: The feature sets for the training and test sets.y_train,y_test: The labels for the training and test sets.metrics: The dictionary of metrics to evaluate.Output:
A tuple containing:
- The model name.
- The
train_metricsandtest_metrics. - The confusion matrix plots for the training and test sets.
evaluate_models
This function:
- Uses the
mapfunction to apply theevaluate_single_modelfunction to each model in themodelsdictionary.
The
mapfunction processes each model, gets the evaluation results (metrics and confusion matrices), and collects them in a list.After evaluating all models, it unpacks the results into two outputs:
- A dictionary (
model_performance) containing the performance metrics (both training and test). - A list of confusion matrix plots.
- A dictionary (
Input:
models: The dictionary of models to evaluate.X_train_selected,X_test_selected: The feature sets for the training and test sets.y_train,y_test: The labels for the training and test sets.metrics: The dictionary of metrics to evaluate.
Output:
- A dictionary of model performance metrics.
- A list of confusion matrix plots.
create_markdown_table
This function generates a Markdown table to display the performance of each model.
Input:
model_performance: The dictionary containing the model performance metrics for both the training and test sets.models: The dictionary of models.
Output:
A
MarkdownTableWriterobject containing the table formatted with the model names as columns and metrics as rows.Main Execution Block
In the main block, here’s what we’re doing:
- we define the models we’ll be training and tuning and the hyperparameters we’ll be tuning for each model.
- we specify our evaluation metrics.
- we the
evaluate_modelsto evaluate all the models we want to train and we collect the results of model training/hyperparameter tuning, including confusion matrices and specified performance metrics. - we create (and display) a Markdown table that summarizes model performance for all the models we trained using the
create_markdown_table. - we then plot the confusion matrices for the models we trained and display them side-by-side using
gggrid.
Our overall goal here was to perform hyperparameter tuning for multiple models and evaluate the performance of these models while making the code as modular and as reusable as possible and avoiding unnecessary for loops.
# Helper function to calculate any set of metrics (flexible)
def calculate_metrics(y_train, y_pred_train, y_test, y_pred_test, metrics):
# Calculate and return the metrics for both train and test
train_metrics = {
f"{metric} (Train)": round(func(y_train, y_pred_train), 2)
for metric, func in metrics.items()
}
test_metrics = {
f"{metric} (Test)": round(func(y_test, y_pred_test), 2)
for metric, func in metrics.items()
}
return train_metrics, test_metrics
#plot confusion matrix
def plot_confusion_matrix(data, title):
return (ggplot(data, aes(x='Predicted', y='Actual', fill='Count'))
+ geom_tile()
+ geom_text(aes(label='Annotation'), size=10, color='black')
+ scale_fill_gradient(low='#ffeee0', high='#00A693')
+ ggtitle(title)
+ theme_minimal())
# Helper function to create confusion matrix plots
def create_confusion_matrices(model_name, y_train, y_pred_train, y_test, y_pred_test):
# Get confusion matrices for train and test
conf_matrix_train = confusion_matrix_long(y_train, y_pred_train, "Train")
conf_matrix_test = confusion_matrix_long(y_test, y_pred_test, "Test")
return [
plot_confusion_matrix(conf_matrix_train, f'{model_name} - Train'),
plot_confusion_matrix(conf_matrix_test, f'{model_name} - Test')
]
# Function to evaluate a single model and collect performance metrics and confusion matrices
def evaluate_single_model(model_name, model, X_train_selected, X_test_selected, y_train, y_test, metrics):
grid_search = GridSearchCV(
model, param_grid[model_name], cv=5, scoring="average_precision",
n_jobs=-1, error_score="raise"
)
grid_search.fit(X_train_selected, y_train)
best_model = grid_search.best_estimator_
y_pred_train, y_pred_test = best_model.predict(X_train_selected), best_model.predict(X_test_selected)
train_metrics, test_metrics = calculate_metrics(y_train, y_pred_train, y_test, y_pred_test, metrics)
confusion_matrices = create_confusion_matrices(model_name, y_train, y_pred_train, y_test, y_pred_test)
return model_name, train_metrics, test_metrics, confusion_matrices, best_model
# Function to evaluate multiple models
def evaluate_models(models, X_train_selected, X_test_selected, y_train, y_test, metrics):
results = [
evaluate_single_model(model_name, model, X_train_selected, X_test_selected, y_train, y_test, metrics)
for model_name, model in models.items()
]
return (
{model_name: {**train_metrics, **test_metrics} for model_name, train_metrics, test_metrics, _, _ in results},
[conf_matrix for _, _, _, confusion_matrices, _ in results for conf_matrix in confusion_matrices],
{model_name: best_model for model_name, _, _, _, best_model in results}
)
# Function to create the Markdown table for model performance
def create_markdown_table(model_performance, models):
rows = list(next(iter(model_performance.values())).keys()) # Get all the metrics (train/test)
# Create the table values using list comprehensions
table_values = [
[row] +
[model_performance[model_name].get(f"{row}", "N/A") for model_name in models] # Match the exact key with (Train) or (Test)
for row in rows
]
# Create Markdown table writer
writer = MarkdownTableWriter()
writer.table_name = "Model Performance"
writer.headers = ["Metric"] + list(models.keys()) # Models as columns
writer.value_matrix = table_values
return writer
# Main block to execute everything
models = {
"XGBoost": XGBClassifier(eval_metric="logloss"),
"LightGBM": LGBMClassifier(verbose=-1),
"CatBoost": CatBoostClassifier(verbose=0)
}
param_grid = {
"XGBoost": {
"n_estimators": [50, 100],
"max_depth": [3, 6],
"reg_alpha": [0, 0.1],
"reg_lambda": [0.1, 1]
},
"LightGBM": {
"n_estimators": [50, 100],
"num_leaves": [20, 40],
"min_child_samples": [10, 20]
},
"CatBoost": {
"iterations": [50, 100],
"depth": [3, 6],
"l2_leaf_reg": [1, 3]
}
}
# Define metrics you want to evaluate (flexible)
metrics = {
"Balanced Accuracy": balanced_accuracy_score,
"F1 Score": f1_score,
"Precision": precision_score,
"Recall": recall_score,
"AUC": roc_auc_score,
"AUC-PR": average_precision_score
}
# Call the evaluate_models function to get model performance and confusion matrices
model_performance, all_confusion_matrices, best_models = evaluate_models(
models, X_train_selected, X_test_selected, y_train, y_test, metrics
)
# Create Markdown table for model performance
writer = create_markdown_table(model_performance, models)
# Display the table
writer/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(Model Performance
| Metric | XGBoost | LightGBM | CatBoost |
|---|---|---|---|
| Balanced Accuracy (Train) | 0.98 | 1.00 | 0.98 |
| F1 Score (Train) | 0.99 | 1.00 | 0.99 |
| Precision (Train) | 0.98 | 1.00 | 0.98 |
| Recall (Train) | 1.00 | 1.00 | 1.00 |
| AUC (Train) | 0.98 | 1.00 | 0.98 |
| AUC-PR (Train) | 0.98 | 1.00 | 0.98 |
| Balanced Accuracy (Test) | 0.96 | 0.89 | 0.96 |
| F1 Score (Test) | 0.96 | 0.93 | 0.96 |
| Precision (Test) | 1.00 | 0.93 | 1.00 |
| Recall (Test) | 0.93 | 0.93 | 0.93 |
| AUC (Test) | 0.96 | 0.89 | 0.96 |
| AUC-PR (Test) | 0.98 | 0.91 | 0.98 |
# Display confusion matrices in grid
gggrid(all_confusion_matrices, ncol=2)+ ggsize(1000, 1000)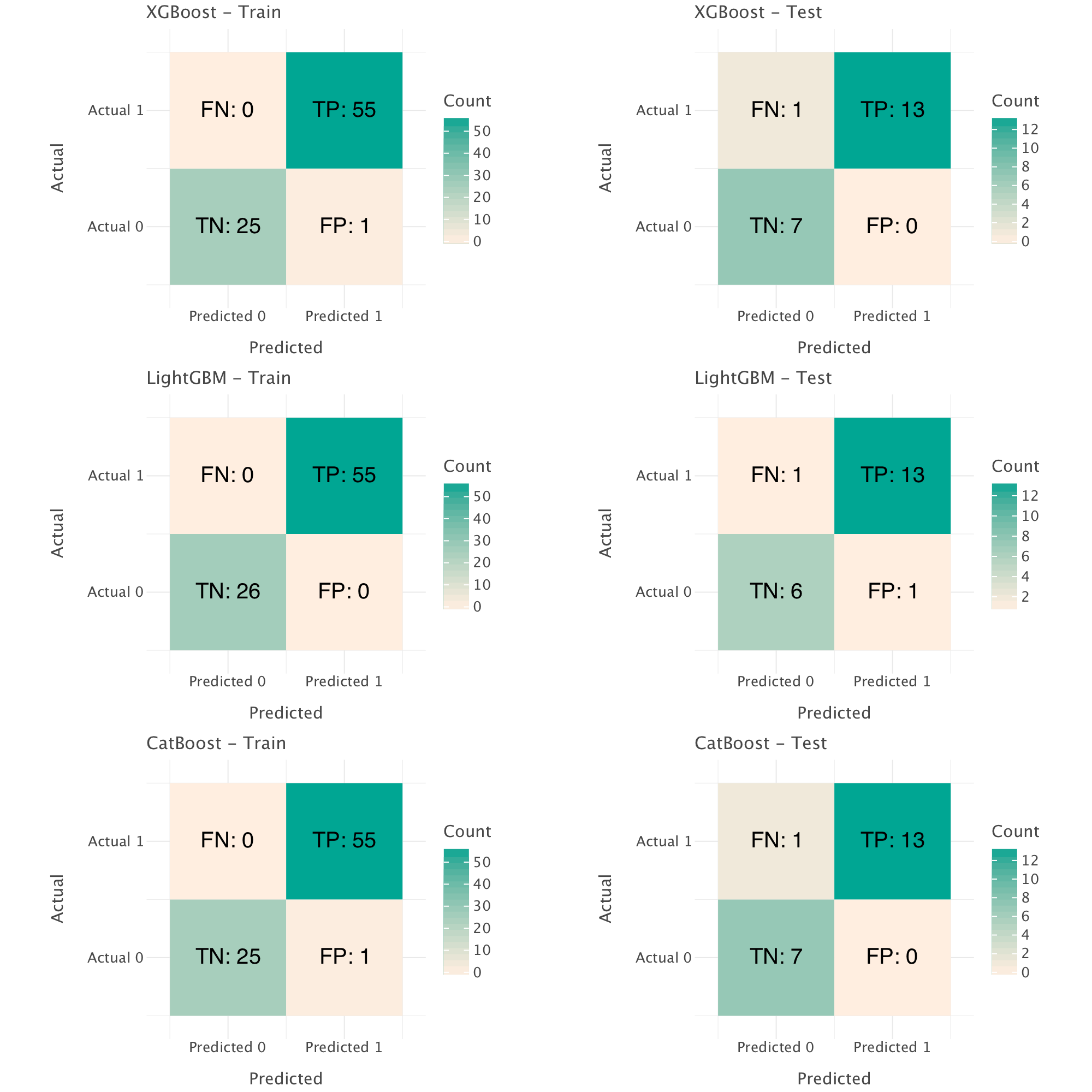
XGBoost performs best overall. There is a significant drop in performance on the test set compared to the training set, which, indicates, here again, a likely pattern of overfitting (which we could have suspected already from the perfect metrics in the training set!). In all models, the performance on the test set (as seen through the confusion matrix and recall) shows that the models perform worse on the negative class, which is not wholly unexpected due to the class imbalance in the dataset. To improve the performance of our models, we would need to mitigate the imbalance, e.g through oversampling (i.e creating synthetic samples of the minority class to even out the proportion of both classes in our data)2 and/or penalizing misclassifications of the minority class during model training by assigning larger class weights to samples of the minority class and smaller ones to samples of the majority one (see here for details for example).
Our feature selection procedure may have removed too much information as it looks as if our current models generalize less well than our simple baseline decision tree model from earlier.
def create_feature_importance_plot(df, title):
return (ggplot(df, aes(x="Feature", y="Importance"))
+ geom_bar(stat='identity', fill="orange")
+ coord_flip()
+ ggtitle(title)
+ theme(axis_text_y=element_text(size=11),
axis_text_x=element_text(size=9)))
# Feature importance plots
def get_feature_importance(best_models, selected_features):
return [
create_feature_importance_plot(
pd.DataFrame({'Feature': selected_features, 'Importance': best_models[model].feature_importances_})
.sort_values(by='Importance', ascending=True)
.query('Importance > 0.001'),
f"Feature Importance\n in {model}"
)
for model in best_models
]
# Generate feature importance plots
feature_importance_plots = get_feature_importance(best_models, selected_features)
# Display all feature importance plots
gggrid(feature_importance_plots, ncol=1, align=True)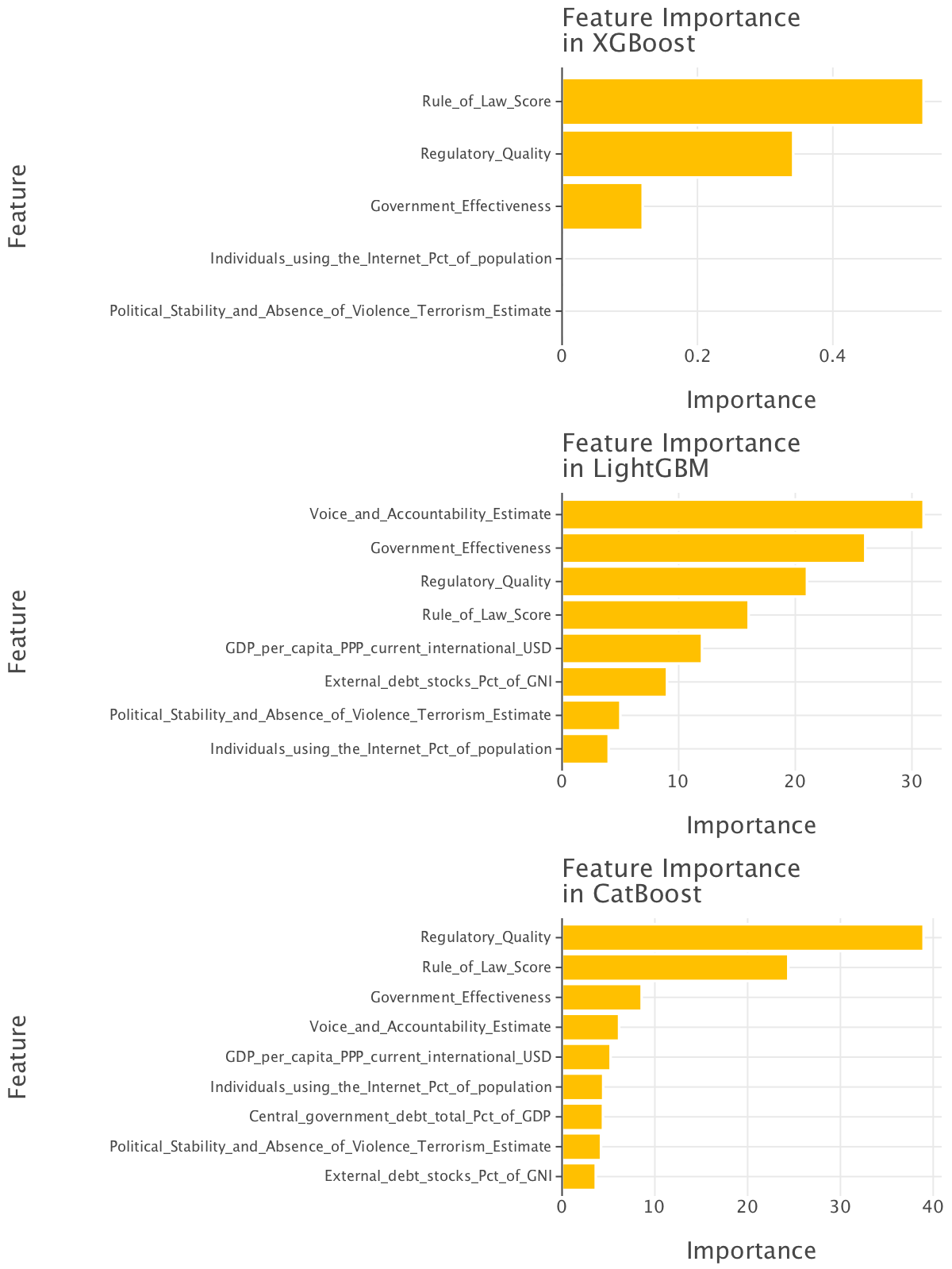
The most important features based XGBoost look quite different to the ones picked up as most important by the decision tree: the rule of law score and government effectiveness come on top. Both features highlight the need for government to work well for their citizens as a whole for them not to be corrupt rather than simply for the private sector (as picked up by the earlier decision tree).
(Bonus) Let’s see if the performance of the ensemble of trees models changes if we add tweaks in the training that take into account class imbalance i.e if we oversample our training set with SMOTE and apply class weights to our models during training too! There are two slight changes in the model training code: - we change the model specifications i.e the models dictionary (we add parameters to all three models to specify that we’ll be applying class weights during training) - we add two lines of code prior to model training to process the training set further and apply oversampling i.e SMOTE to it
Aside from that, the previous model training/hyperparameter tuning code remains sensibly similar.
models = {
"XGBoost": XGBClassifier(eval_metric="logloss", scale_pos_weight=1), # Apply class weights to XGBoost
"LightGBM": LGBMClassifier(class_weight='balanced',verbose=-1), # Apply class weights to LightGBM
"CatBoost": CatBoostClassifier(auto_class_weights='Balanced', verbose=0) # Apply class weights to CatBoost
}
# Apply SMOTE to the training set
smote = SMOTE(random_state=42)
X_train_selected_resampled, y_train_resampled = smote.fit_resample(X_train_selected, y_train)
# Call the evaluate_models function to get model performance and confusion matrices
model_performance, all_confusion_matrices , best_models = evaluate_models(
models, X_train_selected_resampled, X_test_selected, y_train_resampled, y_test, metrics
)
# Create Markdown table for model performance
writer = create_markdown_table(model_performance, models)
# Display the table
writer/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(
/opt/anaconda3/lib/python3.12/site-packages/sklearn/utils/validation.py:2739: UserWarning: X does not have valid feature names, but LGBMClassifier was fitted with feature names
warnings.warn(Model Performance
| Metric | XGBoost | LightGBM | CatBoost |
|---|---|---|---|
| Balanced Accuracy (Train) | 1.00 | 1.00 | 0.97 |
| F1 Score (Train) | 1.00 | 1.00 | 0.97 |
| Precision (Train) | 1.00 | 1.00 | 0.98 |
| Recall (Train) | 1.00 | 1.00 | 0.96 |
| AUC (Train) | 1.00 | 1.00 | 0.97 |
| AUC-PR (Train) | 1.00 | 1.00 | 0.96 |
| Balanced Accuracy (Test) | 0.96 | 0.96 | 0.96 |
| F1 Score (Test) | 0.96 | 0.96 | 0.96 |
| Precision (Test) | 1.00 | 1.00 | 1.00 |
| Recall (Test) | 0.93 | 0.93 | 0.93 |
| AUC (Test) | 0.96 | 0.96 | 0.96 |
| AUC-PR (Test) | 0.98 | 0.98 | 0.98 |
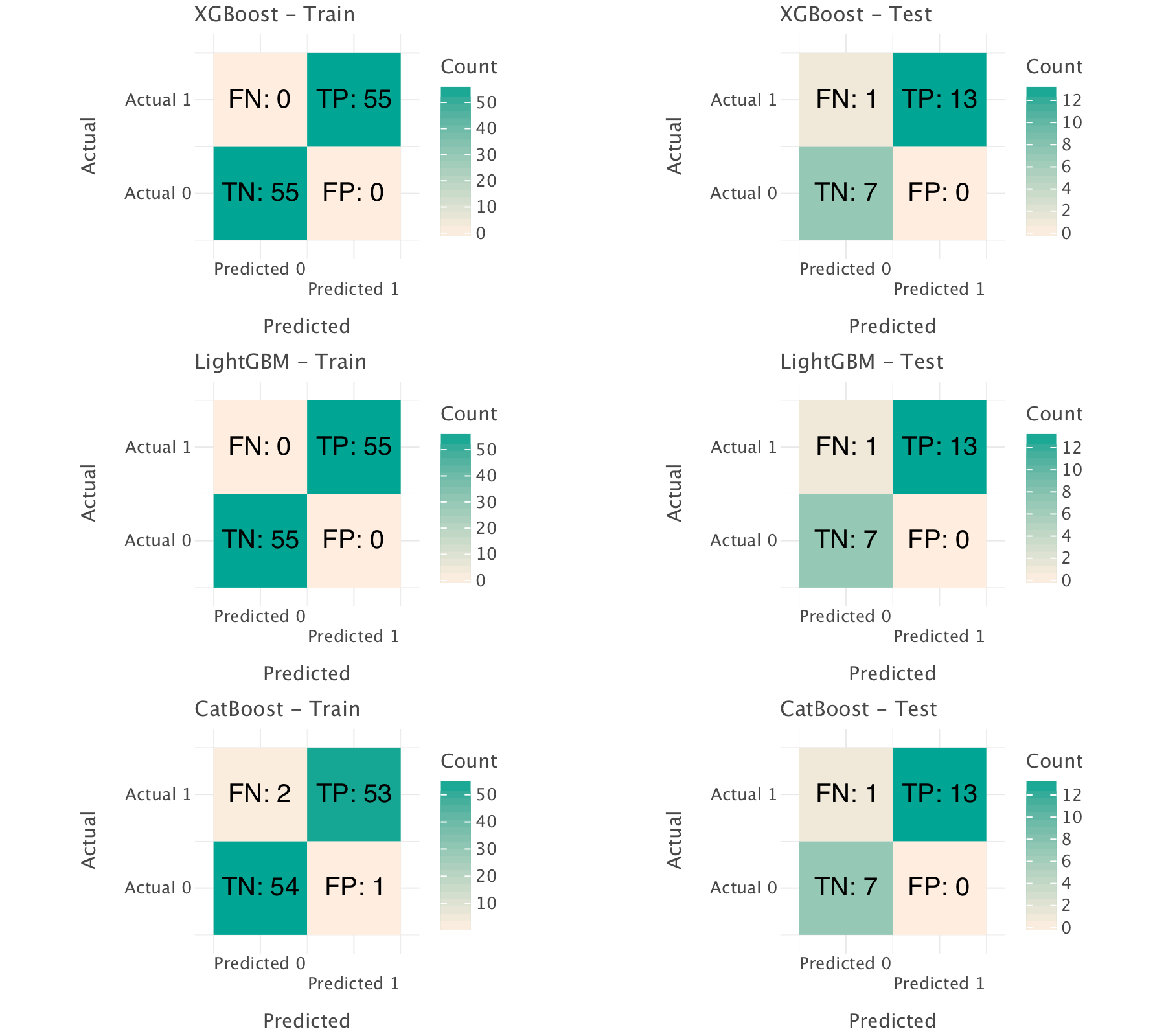
# Display confusion matrix plots
gggrid(all_confusion_matrices, ncol=2, align=True)Our metrics don’t exactly improve with SMOTE/class weights! Why is that? Our models were probably already adequately handling the slight class imbalance in our data, so SMOTE/class weights were unlikely to offer a significant boost. The models were likely already adjusting their decision boundaries to account for the imbalance, and the test set metrics indicate that the performance was already optimized.
References
Footnotes
other methods we could try would be recursive feature elimination or sequential feature selection↩︎
one such oversampling technique is SMOTE - see here for more details on SMOTE. See also (Chawla et al. 2002)↩︎