
✅ Reading Week Homework: Solutions
2025/26 Winter Term
Materials to download
This solution file follows the format of the Jupyter Notebook file .ipynb you had to fill in for your homework. If you want to render the document yourselves and play with the code, you can download the .ipynb version of this solution file by clicking on the button below:
⚙️ Setup
# Prefer conda-forge for dependency resolution; use pip only if unavailable.
#
# conda install -c conda-forge pandas scikit-learn matplotlib seaborn xgboost plotly shap
#
# pip fallback (only if needed):
# !pip install shapimport numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import seaborn as sns
import shap
from joblib import Parallel, delayed
from scipy.stats import loguniform
import plotly.graph_objects as go
from sklearn.model_selection import (
train_test_split, StratifiedKFold,
cross_validate, GridSearchCV, RandomizedSearchCV
)
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.metrics import f1_score, precision_score, recall_score, make_scorer
from xgboost import XGBClassifier
sns.set_theme(style='whitegrid', palette='muted')
RANDOM_STATE = 123🥅 Homework objectives
We have introduced a range of supervised learning algorithms in previous labs and lectures. Selecting the best model is rarely straightforward in practice. In this assignment, we guide you through that process using a real labour economics dataset.
- Compare the decision boundaries produced by four models trained to predict whether a US worker earns above the median wage.
- Apply 5-fold cross-validation to determine which model performs best overall.
- Fine-tune a Support Vector Machine and an XGBoost model.
- Use SHAP values to understand what drives predictions in the best model.
- Use multinomial logistic regression to predict wage tercile membership and interpret its coefficients in the context of the gender wage gap.
Loading the CPS-MORG 2019 dataset
We use the 2019 Current Population Survey Merged Outgoing Rotation Group (CPS-MORG), the benchmark dataset in the US labour economics literature on wage inequality and the gender pay gap (Blau & Kahn 2017 (Blau and Kahn 2017), among many others). Freely available from the NBER — US Government public domain data.
Each row is a full-time wage/salary worker aged 18–64 surveyed in 2019.
| Variable | Description |
|---|---|
hourly_wage |
Computed hourly wage (weekly earnings ÷ hours, or direct rate if paid hourly) |
above_median_wage |
Binary outcome: 1 if wage > sample median |
wage_tercile |
Three-class outcome: bottom, middle, top |
female |
1 = female, 0 = male |
educ_years |
Years of schooling (recoded from CPS categories) |
potential_exp |
age − educ_years − 6 (Mincer convention) |
age |
Age in years |
married |
1 = married with spouse present |
union_mem |
1 = union member or covered by contract |
public_sector |
1 = government industry |
occ_group |
management, professional, service, sales_office, blue_collar |
white, black, hispanic |
Race/ethnicity indicators |
📋 Data preparation note
The CSV was constructed from the NBER CPS MORG file (
morg19.dta) using the following steps:
- Sample restrictions: full-time workers (≥ 35 hours/week), age 18–64, with valid earnings.
- Hourly wage:
- If paid hourly, use
earnhre.
- Otherwise compute
earnwke ÷ uhourse.- Education:
educ_yearsrecoded fromgrade92to represent completed years of schooling.- Potential experience:
\[ \text{potential\_exp} = \text{age} - \text{educ\_years} - 6 \] This follows the Mincer (1974) earnings framework (Mincer 1974), which models wages as a function of schooling and labour market experience.- Union membership:
union_mem=unionmmeORunioncov.- Public sector indicator:
ind02∈ [8770, 9590].- Occupation group: derived from
occ2012.You are not required to reproduce these transformations, but you should understand what each constructed variable represents and why it may matter economically.
df = pd.read_csv('data/cps_morg_2019_wages.csv')
print(df.shape)
df.head()(113654, 14)| hourly_wage | above_median_wage | wage_tercile | female | educ_years | potential_exp | age | married | union_mem | public_sector | occ_group | white | black | hispanic | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 20.91325 | 0 | middle | 1 | 14.0 | 34.0 | 54 | 0 | 0 | 0 | sales_office | 0 | 1 | 0 |
| 1 | 28.84600 | 1 | middle | 1 | 16.0 | 35.0 | 57 | 0 | 0 | 1 | professional | 0 | 1 | 0 |
| 2 | 12.25000 | 0 | bottom | 1 | 14.0 | 3.0 | 23 | 0 | 0 | 0 | service | 0 | 1 | 0 |
| 3 | 200.00000 | 1 | top | 1 | 12.0 | 6.0 | 24 | 0 | 0 | 0 | service | 0 | 1 | 0 |
| 4 | 56.77400 | 1 | top | 0 | 16.0 | 15.0 | 37 | 1 | 0 | 0 | professional | 1 | 0 | 0 |
Before fitting any models, explore the data.
❓ Question 1: Compute the mean hourly wage for men and women separately. What is the raw (unadjusted) hourly wage gap? Does the size surprise you?
gap = df.groupby('female')['hourly_wage'].mean().rename({0: 'Male', 1: 'Female'})
print(gap)
print(f"\nRaw gap: ${gap['Male'] - gap['Female']:.2f}/hr "
f"({(gap['Male'] - gap['Female']) / gap['Male']:.1%} of male wage)")female
Male 29.629973
Female 26.657336
Name: hourly_wage, dtype: float64
Raw gap: $2.97/hr (10.0% of male wage)The raw gap among full-time workers is around $3/hr (~10%), meaning women earn roughly 90 cents for every dollar earned by men. This is narrower than the BLS headline (~82 cents) because we restrict to full-time workers — part-time employment, which is disproportionately female and lower-paid, is excluded. The gap is sensitive to sample composition before a single model has been fit.
Feature setup
occ_group is categorical and must be one-hot encoded before passing to scikit-learn.
NUMERIC_FEATURES = [
'female', 'educ_years', 'potential_exp', 'age',
'married', 'union_mem', 'public_sector',
'white', 'black', 'hispanic'
]
TARGET_BINARY = 'above_median_wage'
df_enc = pd.get_dummies(df, columns=['occ_group'], drop_first=True)
OCC_DUMMIES = [c for c in df_enc.columns if c.startswith('occ_group_')]
ALL_FEATURES = NUMERIC_FEATURES + OCC_DUMMIES
X = df_enc[ALL_FEATURES]
y = df_enc[TARGET_BINARY]
print(f'Features ({len(ALL_FEATURES)}): {ALL_FEATURES}')Features (14): ['female', 'educ_years', 'potential_exp', 'age', 'married', 'union_mem', 'public_sector', 'white', 'black', 'hispanic', 'occ_group_management', 'occ_group_professional', 'occ_group_sales_office', 'occ_group_service']Inspecting class balance (binary outcome)
Before splitting the data, inspect the distribution of the binary outcome.
❓ Are the two classes balanced? What might this imply for how you evaluate model performance?
### Answer
Because above_median_wage is defined using the sample median, the split is approximately 50/50 (up to ties at the median). In this setting, metrics like accuracy and ROC AUC are not mechanically distorted by severe imbalance. That said, it is still good practice to check class balance: if one class were rare, you would place more emphasis on class-sensitive metrics (e.g. precision/recall or PR AUC) and on how you choose a classification threshold.
counts = y.value_counts()
props = y.value_counts(normalize=True)
display(pd.DataFrame({'count': counts, 'share': props.round(3)}))| count | share | |
|---|---|---|
| above_median_wage | ||
| 0 | 56827 | 0.5 |
| 1 | 56827 | 0.5 |
Do not assume balance: verify it.
If one class were much rarer than the other, would all metrics still be informative?
Train / test split
Perform a stratified 75/25 split. Stratifying on y preserves class balance in both sets.
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, stratify=y, random_state=RANDOM_STATE
)
print(f'Train: {X_train.shape[0]:,} | Test: {X_test.shape[0]:,}')Train: 85,240 | Test: 28,414Stratified subsample for SVM steps
SVMs scale as O(n²)–O(n³) in training samples. We draw a 5,000-row stratified subsample — preserving class balance — which keeps wall time under a minute while producing stable cross-validated estimates at this feature dimensionality.
X_train_sub, _, y_train_sub, _ = train_test_split(
X_train, y_train,
train_size=5_000,
stratify=y_train,
random_state=RANDOM_STATE
)
print(f'Full training set : {len(X_train):,} rows (balance: {y_train.mean():.3f})')
print(f'SVM subsample : {len(X_train_sub):,} rows (balance: {y_train_sub.mean():.3f})')Full training set : 85,240 rows (balance: 0.500)
SVM subsample : 5,000 rows (balance: 0.500)The two balance figures should be nearly identical — confirmation that stratification worked.
5-fold cross-validation setup
We will evaluate models using 5-fold cross-validation.
This means:
- Split the training data into 5 equally sized folds.
- Train on 4 folds.
- Evaluate on the remaining fold.
- Repeat so each fold serves as validation once.
For classification problems, it is important that each fold preserves the class proportions of the outcome.
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=RANDOM_STATE)Evaluation metrics
We will evaluate models using multiple metrics.
Think about what each metric measures:
- Does it depend on a probability threshold?
- Does it treat false positives and false negatives symmetrically?
- Does it assume balanced classes?
You should construct a dictionary mapping metric names to scorer objects.
scoring = {
'precision': make_scorer(precision_score, zero_division=0),
'recall': make_scorer(recall_score),
'f1': make_scorer(f1_score),
}🗺️ Decision boundaries
Each model is trained on all features in ALL_FEATURES.
To visualise its behaviour, we take a 2D slice of the high-dimensional feature space:
- Vary
potential_exp(x-axis) - Vary
educ_years(y-axis) - Fix all other features at their training-set median
This produces a cross-section of a 14-dimensional decision surface.
We then:
- Generate a dense grid of points in this 2D plane.
- Ask the model to predict at each grid point.
- Plot the predicted class regions.
❓ Which models produce linear boundaries?
❓ Which allow nonlinear curvature?
❓ How does flexibility differ across models?
Initialise the five models
We compare five classifiers spanning a range of boundary shapes:
- Logistic regression — linear boundary, interpretable coefficients.
- Decision tree — axis-aligned rectangular regions, fully interpretable but prone to overfitting.
- Linear SVM — margin-maximising linear boundary.
- RBF SVM — radial basis function kernel; the most widely used SVM kernel in practice. Boundary shape is controlled by
C(margin width) andgamma(kernel bandwidth). - Polynomial SVM (degree 2) — quadratic boundary. Less common than RBF but useful to contrast: polynomial kernels expand the feature space explicitly, RBF kernels do so implicitly via an infinite-dimensional mapping.
models = {
'Logistic\nRegression': LogisticRegression(max_iter=1000, random_state=RANDOM_STATE),
'Decision\nTree': DecisionTreeClassifier(random_state=RANDOM_STATE),
'SVM\nLinear': Pipeline([
('scaler', StandardScaler()),
('svm', SVC(kernel='linear', random_state=RANDOM_STATE))
]),
'SVM\nRBF': Pipeline([
('scaler', StandardScaler()),
('svm', SVC(kernel='rbf', random_state=RANDOM_STATE))
]),
'SVM\nPolynomial': Pipeline([
('scaler', StandardScaler()),
('svm', SVC(kernel='poly', degree=2, random_state=RANDOM_STATE))
]),
}Pipeline?
Support Vector Machines are not scale-invariant.
- The SVM margin depends on distances in feature space.
- The RBF and polynomial kernels compute functions of inner products and Euclidean distances.
- If one feature has a much larger numerical range than others, it can dominate the geometry of the margin.
For this reason, each SVM is wrapped in a Pipeline with a StandardScaler, which: 1. Fits the scaler only on the training data (avoiding leakage), 2. Standardises all features to zero mean and unit variance, 3. Then fits the SVM on the scaled features.
Tree-based models (e.g. decision trees) do not require scaling: - They split on feature thresholds. - They are invariant to monotonic transformations of individual features.
Logistic regression is technically scale-sensitive, but: - Scaling is not strictly required for correctness, - It mainly affects optimisation speed and coefficient comparability, - Here we prioritise interpretability of raw-scale coefficients.
Using a Pipeline ensures preprocessing is consistently applied inside cross-validation and hyperparameter tuning.
Build the 2D visualisation grid
We want to visualise how predicted probabilities vary across two key features: - potential_exp (x-axis) - educ_years (y-axis)
We therefore construct two objects:
1️⃣ obs_grid
obs_grid summarises the observed data: - For each integer combination of (potential_exp, educ_years) - Compute the observed proportion of above-median earners
This will later be used to colour observed data points.
2️⃣ vis_grid
vis_grid is a dense prediction grid used for model visualisation.
Steps:
- Create evenly spaced sequences for
potential_expandeduc_yearsusingnp.linspace. - Use
np.meshgridto create all coordinate pairs. - Construct a DataFrame where:
- Every row corresponds to one grid point.
- All other features are fixed at their training-set median.
- Only
potential_expandeduc_yearsvary across rows.
❓ Why do we use continuous sequences rather than only observed values?
❓ What does fixing other features at their median imply about this visualisation?
obs_grid = (
df_enc
.assign(potential_exp=df_enc['potential_exp'].astype(int))
.groupby(['potential_exp', 'educ_years'])[TARGET_BINARY]
.mean().reset_index()
.rename(columns={TARGET_BINARY: 'prop_above_median'})
)
medians = X_train.median()
N_GRID = 80
exp_lin = np.linspace(df['potential_exp'].min(), df['potential_exp'].max(), N_GRID)
educ_lin = np.linspace(df['educ_years'].min(), df['educ_years'].max(), N_GRID)
exp_mesh, educ_mesh = np.meshgrid(exp_lin, educ_lin)
vis_grid = pd.DataFrame(
np.tile(medians.values, (exp_mesh.size, 1)),
columns=ALL_FEATURES
)
vis_grid['potential_exp'] = exp_mesh.ravel()
vis_grid['educ_years'] = educ_mesh.ravel()
print(f'Grid: {N_GRID}×{N_GRID} = {len(vis_grid):,} points')Grid: 80×80 = 6,400 pointsWe constructed two different objects, serving different purposes.
1️⃣ obs_grid — a summary of the observed data
- We convert
potential_expto integers so we can group by discrete experience levels. - For each (
potential_exp,educ_years) combination, we compute the observed proportion of above-median earners. - This is purely descriptive — it summarises the empirical data.
It tells us: in the actual sample, what fraction of workers in each cell earn above the median.
2️⃣ vis_grid — a synthetic prediction grid
This is not real data.
We:
- Take the median feature vector from the training data.
- Replicate it \(N \times N\) times.
- Overwrite only two columns (
potential_exp,educ_years) using a dense meshgrid.
This produces a smooth grid of points covering the 2D plane.
When we pass vis_grid to a model’s predict or predict_proba method, we obtain:
- A 2D cross-section of the model’s high-dimensional decision surface.
Why fix all other features at their median?
Because the models were trained in 14 dimensions.
To visualise them in 2D, we must hold the remaining 12 features constant.
Using the median gives a “typical worker” profile.
This means:
- The boundary you see is conditional on all other features being fixed.
- Changing those fixed values would shift the boundary.
This is a slice of the model — not the full decision surface.
Fit models and generate predictions
joblib.Parallel runs independent tasks concurrently across CPU cores. Since each model fit is independent of the others, we can parallelise across them. The pattern is always:
def my_task(arg): # define the work as a plain function
return do_something(arg)
results = Parallel(n_jobs=-1)( # n_jobs=-1 uses all available cores
delayed(my_task)(x) # delayed() wraps each call lazily
for x in my_list
)Write a fit_one helper that fits one model and returns (name, {y_pred, grid_pred, f1}), then dispatch it with Parallel.
def fit_one(name, model, X_tr, y_tr, X_te, y_te, X_grid):
model.fit(X_tr, y_tr)
y_pred = model.predict(X_te)
grid_pred = model.predict(X_grid)
f1 = f1_score(y_te, y_pred)
return name, {'y_pred': y_pred, 'grid_pred': grid_pred, 'f1': f1}
fitted = Parallel(n_jobs=-1)(
delayed(fit_one)(name, model,
X_train_sub, y_train_sub,
X_test, y_test,
vis_grid[ALL_FEATURES])
for name, model in models.items()
)
results = dict(fitted)
for name, res in results.items():
print(f"{name.replace(chr(10), ' '):<25} F1 = {res['f1']:.4f}")Logistic Regression F1 = 0.7154
Decision Tree F1 = 0.6225
SVM Linear F1 = 0.7093
SVM RBF F1 = 0.7176
SVM Polynomial F1 = 0.6713Visualising decision boundaries
We now compare how different classifiers partition the feature space.
Using two selected features:
- Fit each model on the training data.
- Generate predictions over a fine grid spanning the feature space.
- Plot the predicted class regions.
- Overlay the training observations.
❓ How do the boundaries differ across models?
❓ Which models produce linear separations? Which allow nonlinear structure?
fig, axes = plt.subplots(2, 3, figsize=(18, 11))
cmap_bg = plt.cm.colors.ListedColormap(['#d6eaf8', '#1a5276'])
cmap_pts = plt.cm.RdYlGn
for ax, (name, res) in zip(axes.flatten(), results.items()):
Z = res['grid_pred'].reshape(N_GRID, N_GRID).astype(float)
ax.pcolormesh(exp_lin, educ_lin, Z, cmap=cmap_bg, alpha=0.4, shading='auto')
sc = ax.scatter(
obs_grid['potential_exp'], obs_grid['educ_years'],
c=obs_grid['prop_above_median'], cmap=cmap_pts,
s=20, alpha=0.85, zorder=2, vmin=0, vmax=1
)
ax.set_xlabel('Potential experience (years)', fontsize=10)
ax.set_ylabel('Education (years)', fontsize=10)
ax.set_title(f"{name}\nF1 = {res['f1']:.3f}\n(other features at median)", fontsize=10)
ax.set_xlim(exp_lin[0], exp_lin[-1])
ax.set_ylim(educ_lin[0], educ_lin[-1])
# Hide the unused sixth panel
axes.flatten()[-1].set_visible(False)
cbar_ax = fig.add_axes([0.92, 0.15, 0.012, 0.7])
fig.colorbar(sc, cax=cbar_ax, label='Observed prop. above median wage')
p0 = mpatches.Patch(color='#d6eaf8', alpha=0.7, label='Predicted: below median')
p1 = mpatches.Patch(color='#1a5276', alpha=0.7, label='Predicted: above median')
fig.legend(handles=[p0, p1], loc='lower center', ncol=2,
bbox_to_anchor=(0.45, 0.01), fontsize=10)
fig.suptitle('Decision boundaries — above median wage (CPS-MORG 2019)', fontsize=13)
fig.subplots_adjust(right=0.90, hspace=0.45, wspace=0.3, bottom=0.08)
plt.show()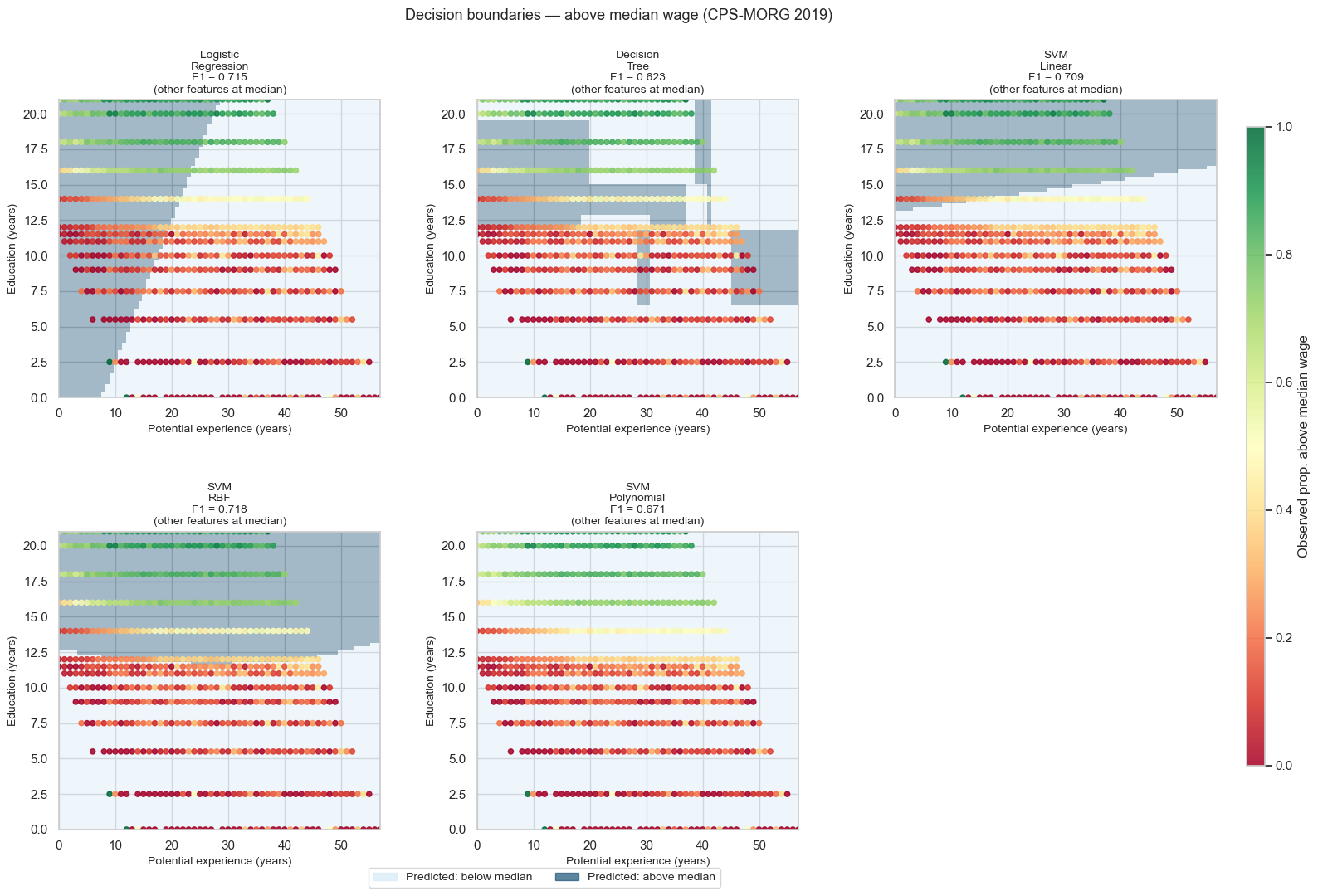
❓ Question 2: Which model achieves the highest F1? Which produces the most interpretable boundary shape, and why is that shape more or less useful for understanding this dataset?
The best-performing model by F1 is the RBF SVM (0.718), followed extremely closely by logistic regression (0.715) and the linear SVM (0.709). The differences among these three are small.
The decision tree performs substantially worse (0.623), reflecting its high variance and axis-aligned boundary structure.
The key insight is structural:
- The wage–education–experience relationship is approximately log-linear (the Mincer earnings framework).
- Linear models already capture most of the signal.
- The RBF SVM extracts a small additional gain by allowing mild nonlinearity.
- The polynomial SVM (degree 2) underperforms relative to linear models, suggesting no strong quadratic structure in this 2D slice.
Importantly, the performance gap between RBF and logistic regression is only ~0.002 — practically negligible. Model choice here is unlikely to materially change decisions.
📊 5-fold cross-validation
Apply the same Parallel pattern to run cross_validate for all four models. Set n_jobs=1 inside cross_validate — the outer Parallel already uses all cores, so allowing each worker to also spawn its own thread pool would over-subscribe the CPU.
def cv_one(name, model, X, y, cv, scoring):
return name, cross_validate(model, X, y, cv=cv, scoring=scoring, n_jobs=1)
cv_results = dict(
Parallel(n_jobs=-1)(
delayed(cv_one)(name, model, X_train_sub, y_train_sub, cv, scoring)
for name, model in models.items()
)
)Build a tidy long-format DataFrame and plot mean ± 95% CI with Plotly.
rows = [
{'model': mname.replace('\n', ' '), 'metric': metric,
'fold': i + 1, 'score': score}
for mname, res in cv_results.items()
for metric in ['precision', 'recall', 'f1']
for i, score in enumerate(res[f'test_{metric}'])
]
long_df = pd.DataFrame(rows)
summary = (long_df.groupby(['model', 'metric'])['score']
.agg(['mean', 'std']).reset_index())
summary['ci95'] = 1.96 * summary['std'] / np.sqrt(5)
rank_order = (summary[summary['metric'] == 'f1']
.sort_values('mean', ascending=False)['model'].tolist())
summary['rank'] = summary['model'].apply(lambda m: rank_order.index(m))
palette = {'f1': '#4c72b0', 'precision': '#dd8452', 'recall': '#55a868'}
metric_lab = {'f1': 'F1', 'precision': 'Precision', 'recall': 'Recall'}
offsets = {'f1': -0.15, 'precision': 0.0, 'recall': 0.15}
fig = go.Figure()
shown = set()
for metric in ['f1', 'precision', 'recall']:
sub = summary[summary['metric'] == metric].set_index('model').loc[rank_order].reset_index()
x_pos = [sub.iloc[j]['rank'] + offsets[metric] for j in range(len(sub))]
fig.add_trace(go.Scatter(
x=x_pos, y=sub['mean'],
error_y=dict(type='data', array=sub['ci95'].tolist(), visible=True,
color=palette[metric], thickness=1.5, width=6),
mode='markers',
marker=dict(size=13, color=palette[metric], line=dict(color='white', width=1)),
name=metric_lab[metric],
customdata=sub[['model', 'ci95']].values,
hovertemplate=('<b>%{customdata[0]}</b><br>'
f'{metric_lab[metric]}: %{{y:.4f}}<br>'
'95% CI: ±%{customdata[1]:.4f}<extra></extra>'),
showlegend=metric not in shown,
))
shown.add(metric)
fig.update_layout(
title='5-fold CV metrics — CPS-MORG 2019',
xaxis=dict(tickmode='array', tickvals=list(range(len(rank_order))),
ticktext=rank_order, title='Model (ranked by F1)'),
yaxis_title='Cross-validated score',
template='plotly_white', height=480, width=800,
legend=dict(title='Metric', orientation='h',
yanchor='bottom', y=-0.22, xanchor='center', x=0.5)
)
fig.show()❓ Question 3: How does the polynomial SVM compare on precision vs. recall? What does the overlap of confidence intervals across models tell you about model selection here?
The RBF SVM, logistic regression, and linear SVM are statistically indistinguishable:
- Their confidence intervals overlap substantially.
- The F1 differences are well below one standard deviation across folds.
The polynomial SVM shows lower recall and greater variability. The decision tree has the widest confidence intervals, reflecting sensitivity to fold composition.
Conclusion:
- Simpler, well-regularised linear models generalise extremely well on this dataset.
- Additional flexibility provides at most marginal gains.
- The performance ranking is stable across folds.
🔧 SVM hyperparameter tuning
We tune two SVM kernels separately, each with its own parameter space.
RBF SVM
Two continuous parameters:
C: controls the penalty for misclassification (margin width).gamma: controls the kernel bandwidth, determining how far the influence of a single training point extends.
We search a 5 × 5 log-spaced grid (25 combinations).
Polynomial SVM
Cdegree(integer controlling polynomial complexity)
We search a 5 × 3 grid (15 combinations).
Both use GridSearchCV with 5-fold cross-validation, optimising ROC-AUC.
If you use a Pipeline, remember that hyperparameters are referenced using:
stepname__parameter (e.g. svm__C).
C_vals = [0.000977, 0.0131, 0.177, 2.38, 32]
gamma_vals = [0.001, 0.01, 0.1, 1.0, 10.0]
# ── RBF SVM ──────────────────────────────────────────────────────────────────
rbf_pipe = Pipeline([('scaler', StandardScaler()),
('svm', SVC(kernel='rbf', random_state=RANDOM_STATE))])
rbf_gs = GridSearchCV(rbf_pipe,
{'svm__C': C_vals, 'svm__gamma': gamma_vals},
cv=cv, scoring='roc_auc', n_jobs=-1, refit=True)
rbf_gs.fit(X_train_sub, y_train_sub)
print('RBF — best params:', rbf_gs.best_params_)
print('RBF — best AUC: ', round(rbf_gs.best_score_, 4))
# ── Polynomial SVM ───────────────────────────────────────────────────────────
poly_pipe = Pipeline([('scaler', StandardScaler()),
('svm', SVC(kernel='poly', random_state=RANDOM_STATE))])
poly_gs = GridSearchCV(poly_pipe,
{'svm__C': C_vals, 'svm__degree': [1, 2, 3]},
cv=cv, scoring='roc_auc', n_jobs=-1, refit=True)
poly_gs.fit(X_train_sub, y_train_sub)
print('Poly — best params:', poly_gs.best_params_)
print('Poly — best AUC: ', round(poly_gs.best_score_, 4))RBF — best params: {'svm__C': 2.38, 'svm__gamma': 0.01}
RBF — best AUC: 0.8015
Poly — best params: {'svm__C': 32, 'svm__degree': 1}
Poly — best AUC: 0.7931
fig, axes = plt.subplots(1, 2, figsize=(16, 5))
# ── Left: RBF — mean CV AUC vs C (one line per gamma) ────────────────────────
rbf_df = pd.DataFrame(rbf_gs.cv_results_)
n_folds = cv.get_n_splits()
for gamma in gamma_vals:
sub = rbf_df[rbf_df['param_svm__gamma'] == gamma].copy()
sub['C'] = sub['param_svm__C'].astype(float)
sub = sub.sort_values('C')
axes[0].errorbar(
sub['C'], sub['mean_test_score'],
yerr=1.96 * sub['std_test_score'] / np.sqrt(n_folds),
fmt='o-', capsize=3, label=f'gamma={gamma}'
)
axes[0].set_xscale('log')
axes[0].set_xlabel('Cost (C)')
axes[0].set_ylabel('Mean CV AUC')
axes[0].set_title('RBF SVM — mean CV AUC vs C')
axes[0].legend(title='Gamma', bbox_to_anchor=(1.02, 1), loc='upper left')
# Star the best combination
best_c = float(rbf_gs.best_params_['svm__C'])
best_g = float(rbf_gs.best_params_['svm__gamma'])
best_row = rbf_df[
(rbf_df['param_svm__C'].astype(float) == best_c) &
(rbf_df['param_svm__gamma'].astype(float) == best_g)
].iloc[0]
axes[0].scatter([best_c], [best_row['mean_test_score']], s=250,
color='black', marker='*', zorder=5)
# ── Right: Polynomial — mean CV AUC vs C (one line per degree) ───────────────
poly_df = pd.DataFrame(poly_gs.cv_results_)
for degree in [1, 2, 3]:
sub = poly_df[poly_df['param_svm__degree'] == degree].copy()
sub['C'] = sub['param_svm__C'].astype(float)
sub = sub.sort_values('C')
axes[1].errorbar(
sub['C'], sub['mean_test_score'],
yerr=1.96 * sub['std_test_score'] / np.sqrt(n_folds),
fmt='o-', capsize=3, label=f'degree={degree}'
)
axes[1].set_xscale('log')
axes[1].set_xlabel('Cost (C)')
axes[1].set_ylabel('Mean CV AUC')
axes[1].set_title('Polynomial SVM — mean CV AUC vs C')
axes[1].legend(title='Degree', bbox_to_anchor=(1.02, 1), loc='upper left')
# Star the best combination
best_c_p = float(poly_gs.best_params_['svm__C'])
best_d_p = int(poly_gs.best_params_['svm__degree'])
best_row_p = poly_df[
(poly_df['param_svm__C'].astype(float) == best_c_p) &
(poly_df['param_svm__degree'].astype(int) == best_d_p)
].iloc[0]
axes[1].scatter([best_c_p], [best_row_p['mean_test_score']], s=250,
color='black', marker='*', zorder=5)
fig.subplots_adjust(wspace=0.7, right=0.82)
plt.show()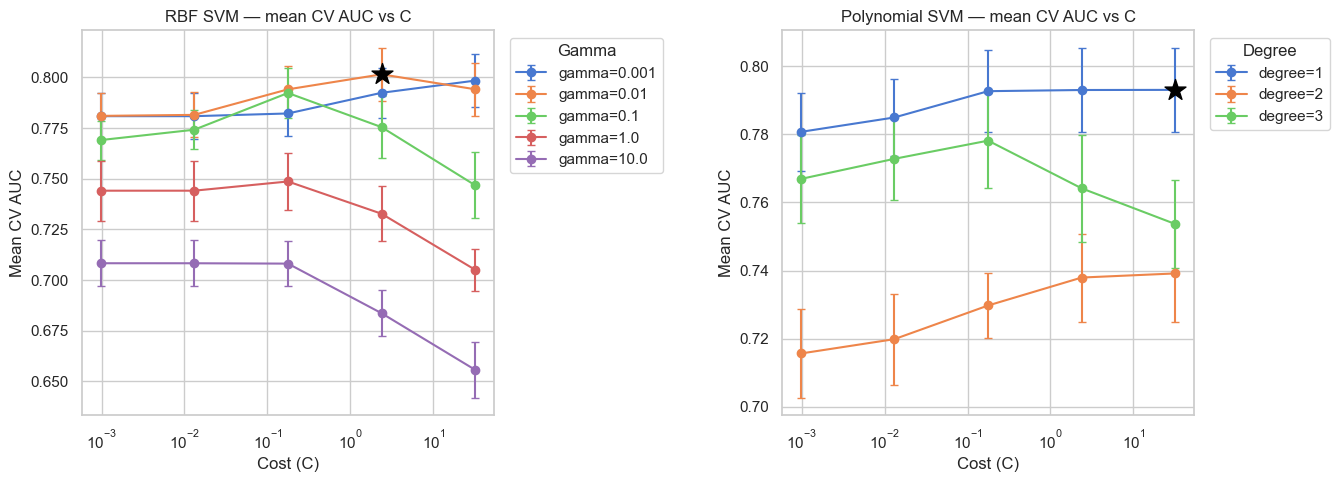
❓ Question 4: Compare the two tuning plots. For the RBF kernel, which region of the C × gamma space performs best, and what does that tell you about the decision boundary? For the polynomial kernel, which degree wins and why?
RBF kernel
The best AUC occurs at moderate-to-large C and moderate gamma.
Interpretation:
- Very small gamma → kernel becomes very wide → RBF behaves almost linearly.
- Very large gamma → kernel becomes extremely local → high-variance boundary (overfitting).
- Very small C → strong regularisation → underfitting.
- Very large C → weak regularisation → risk of overfitting.
The optimal region balances margin flexibility (C) and locality (gamma), matching the scale of real structure in the data.
The smooth, monotonic behaviour across C for moderate gamma values reinforces that the underlying signal is mostly linear with mild curvature.
Polynomial kernel
The best-performing configuration is degree = 1 at large C, which is mathematically equivalent to a linear SVM.
This aligns with earlier results showing that linear decision boundaries capture most of the predictive structure.
Higher-degree kernels (degree 2 or 3) introduce curvature that does not correspond to genuine nonlinear structure in the wage process. On 5k samples, this additional flexibility increases variance without improving bias.
Conclusion: The wage–education–experience relationship in this cross-section is close to linear; additional polynomial complexity is unnecessary.
🌲 XGBoost tuning
Gradient boosting models contain several continuous hyperparameters that strongly influence model complexity.
Here we tune the learning rate, which controls how much each tree contributes to the ensemble.
Because learning rate spans several orders of magnitude, we use RandomizedSearchCV with a log-uniform prior rather than a fixed grid.
This allows us to: - Explore small and large values efficiently - Avoid over-concentrating on one region of the parameter space
📝 The boosting family
The same
RandomizedSearchCVpattern applies to:
lightgbm.LGBMClassifiercatboost.CatBoostClassifiersklearn.ensemble.RandomForestClassifierimblearn.ensemble.BalancedRandomForestClassifierAll follow the scikit-learn
fit/predictAPI.Some variants (e.g. BalancedRandomForest) explicitly address class imbalance during training.
xgb_param_dist = {'learning_rate': loguniform(1e-4, 1.0)}
xgb_model = XGBClassifier(n_estimators=100, eval_metric='logloss',
random_state=RANDOM_STATE, n_jobs=-1)
xgb_rs = RandomizedSearchCV(xgb_model, xgb_param_dist,
n_iter=20, cv=cv, scoring='roc_auc',
n_jobs=-1, random_state=RANDOM_STATE, refit=True)
xgb_rs.fit(X_train_sub, y_train_sub)
print('Best learning rate:', round(xgb_rs.best_params_['learning_rate'], 5))
print('Best AUC: ', round(xgb_rs.best_score_, 4))Best learning rate: 0.01604
Best AUC: 0.7926xgb_cv_df = (pd.DataFrame(xgb_rs.cv_results_)
.sort_values('param_learning_rate').reset_index(drop=True))
fig, ax = plt.subplots(figsize=(9, 4))
ax.scatter(xgb_cv_df['param_learning_rate'], xgb_cv_df['mean_test_score'],
color='steelblue', zorder=2)
ax.errorbar(xgb_cv_df['param_learning_rate'], xgb_cv_df['mean_test_score'],
yerr=1.96 * xgb_cv_df['std_test_score'] / np.sqrt(5),
fmt='none', color='steelblue', alpha=0.4)
ax.axvline(xgb_rs.best_params_['learning_rate'], color='black', linestyle=':')
ax.set_xscale('log')
ax.set_xlabel('Learning rate (log scale)'); ax.set_ylabel('Mean CV AUC')
ax.set_title('XGBoost — randomised learning rate search (CPS-MORG 2019)')
plt.tight_layout(); plt.show()
print(f'Best RBF SVM AUC : {rbf_gs.best_score_:.4f}')
print(f'Best Poly SVM AUC: {poly_gs.best_score_:.4f}')
print(f'Best XGBoost AUC : {xgb_rs.best_score_:.4f}')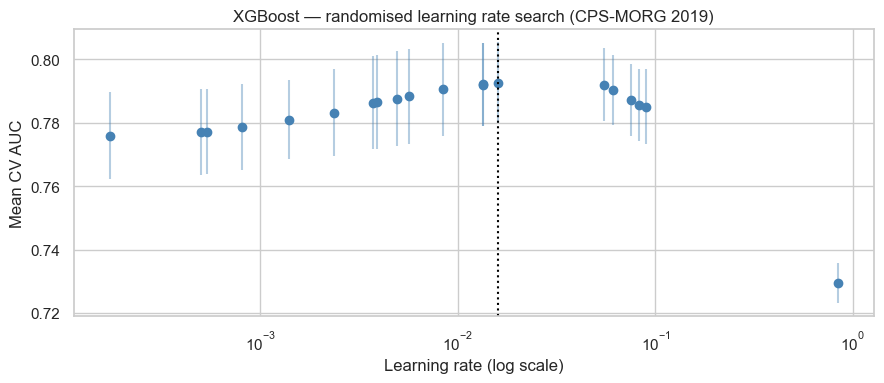
Best RBF SVM AUC : 0.8015
Best Poly SVM AUC: 0.7931
Best XGBoost AUC : 0.7926❓ Question 5: How do all three tuned models compare on AUC? What are the practical trade-offs between them for a large-scale deployment?
Metric reflection
You have evaluated models using ROC AUC.
- Is ROC AUC always the most appropriate metric?
- Under what circumstances might it be insufficient?
- Can you think of alternative evaluation metrics that may be more appropriate in some contexts?
For example, you may wish to explore:
- Precision–Recall AUC
- Class-specific recall or precision
- The \(F_\beta\) score (see (Van Rijsbergen 1979) or check this page)
Now consider the application more concretely:
- If the goal were to identify high-wage workers for targeted recruitment, would another metric be preferable?
- What if the goal were to identify low-wage workers for policy intervention?
Briefly justify your reasoning.
All tuned models (RBF SVM, polynomial SVM, XGBoost) achieve very similar ROC AUC (~0.79–0.80).
Because the outcome was defined via a median split, classes are approximately balanced. In this setting:
- ROC AUC is appropriate.
- Accuracy and F1 are also meaningful.
- PR AUC would not materially change the ranking.
Model choice is therefore driven by practical considerations:
RBF SVM - Strong performance. - Training complexity scales poorly with n (≈ O(n²)). - Less suitable for large datasets.
XGBoost - Comparable AUC. - Scales efficiently. - Handles nonlinearities automatically. - Strong default for production use.
LightGBM - Typically faster than XGBoost on large tabular datasets. - Particularly efficient with large feature sets.
CatBoost - Handles categorical variables natively. - Would allow us to avoid one-hot encoding occ_group. - Often strong on structured economic data.
Given similar predictive performance, gradient-boosted trees (XGBoost / LightGBM / CatBoost) are typically more scalable choices.
On metric choice
Because classes are balanced, ROC AUC is informative.
However:
- If the goal were targeted recruitment of high-wage workers, you might prioritise precision (or Fβ with β<1).
- If the goal were policy intervention for low-wage workers, you might prioritise recall (or Fβ with β>1).
\(F_β\) (Van Rijsbergen 1979) generalises F1 by weighting recall relative to precision (see the scikit-learn documentation).
Metric choice should reflect the decision context, not just statistical elegance.
🔍 Feature importance: SHAP values
A central challenge in applied machine learning is interpretability: understanding which features drive predictions and by how much.
- Logistic regression is interpretable by design — its coefficients are exact, additive feature attributions. No further tools are needed.
- XGBoost and SVMs are black-box or quasi-black-box models. SHAP (SHapley Additive exPlanations) adds a layer of interpretability grounded in cooperative game theory, decomposing each prediction into per-feature contributions that are consistent and locally accurate.
We show three panels side by side:
- Logistic regression coefficients: direct interpretation, no SHAP needed.
- XGBoost SHAP via
TreeExplainer: exact and fast for tree-based models. - RBF SVM SHAP via
KernelExplainer: model-agnostic: works on anypredictfunction by approximating Shapley values via weighted linear regression over a background sample. We use 100 background rows to keep it tractable; accuracy improves with more rows at the cost of runtime. This slowness is the price of model-agnosticism.
If all three agree on feature ranking and direction, we can be confident the patterns reflect the data. Disagreement points to genuine non-linearity that only the more flexible model captures.
# ── 1. Logistic regression — coefficients directly ───────────────────────────
lr_model = LogisticRegression(max_iter=1000, random_state=RANDOM_STATE)
lr_model.fit(X_train_sub, y_train_sub)
lr_coef = pd.Series(lr_model.coef_[0], index=ALL_FEATURES)
lr_coef = lr_coef.reindex(lr_coef.abs().sort_values().index)
# ── 2. XGBoost — TreeExplainer (exact, fast) ──────────────────────────────────
explainer_xgb = shap.TreeExplainer(xgb_rs.best_estimator_)
shap_vals_xgb = explainer_xgb.shap_values(X_train_sub)
# ── 3. RBF SVM — KernelExplainer (model-agnostic, slow) ─────────────────────
# KernelExplainer only needs a predict function — works on any sklearn model.
# Background sample: 50 rows keeps runtime tractable.
def svm_decision(X):
# Ensure input is DataFrame with correct feature names
if not isinstance(X, pd.DataFrame):
X = pd.DataFrame(X, columns=ALL_FEATURES)
return rbf_gs.best_estimator_.decision_function(X)
# Small background sample
background = shap.sample(X_train_sub, 50, random_state=RANDOM_STATE)
explainer_svm = shap.KernelExplainer(svm_decision, background)
# Explain only 50 observations
X_explain = X_train_sub.iloc[:50]
shap_vals_svm = explainer_svm.shap_values(
X_explain,
nsamples=100 # explicitly limit coalition samples
)
# ── Plot three panels ─────────────────────────────────────────────────────────
fig, axes = plt.subplots(1, 3, figsize=(22, 7))
lr_coef.plot(kind='barh', ax=axes[0],
color=['#d73027' if v < 0 else '#4575b4' for v in lr_coef])
axes[0].axvline(0, color='black', linewidth=0.8)
axes[0].set_xlabel('Coefficient value')
axes[0].set_title('Logistic Regression\ncoefficients (no SHAP needed)', fontsize=11)
plt.sca(axes[1])
shap.summary_plot(shap_vals_xgb, X_train_sub, feature_names=ALL_FEATURES,
show=False, plot_size=None)
axes[1].set_title('XGBoost\nSHAP values (TreeExplainer)', fontsize=11)
plt.sca(axes[2])
shap.summary_plot(shap_vals_svm, X_train_sub.iloc[:50], feature_names=ALL_FEATURES,
show=False, plot_size=None)
axes[2].set_title('RBF SVM\nSHAP values (KernelExplainer, 50 obs)', fontsize=11)
plt.tight_layout()
plt.show()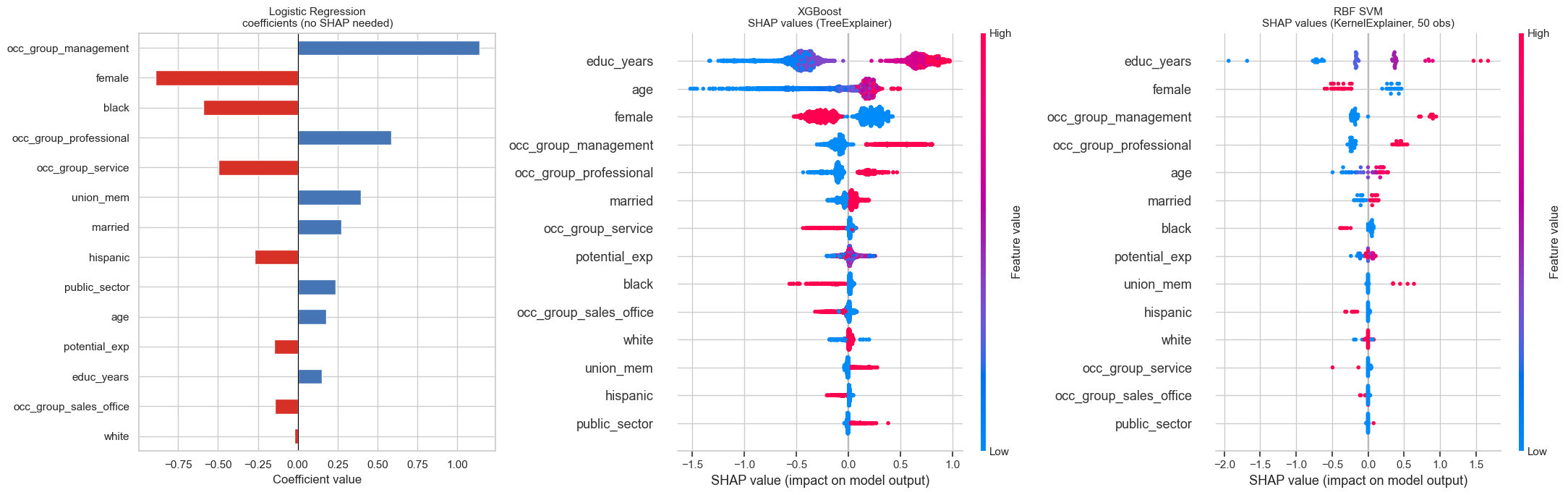
Each horizontal row corresponds to a feature.
Each dot represents one observation.
- The x-axis is the SHAP value:
- Positive → pushes the prediction toward the positive class.
- Negative → pushes the prediction away from it.
- Magnitude → strength of influence.
- The colour encodes the feature value:
- Red → high feature value
- Blue → low feature value
To interpret:
- Look at how wide the row spreads → overall importance.
- Look at colour patterns:
- If red dots cluster on the right, high values increase predicted probability.
- If red dots cluster on the left, high values decrease predicted probability.
- Look for asymmetry:
- Wide spread on one side suggests nonlinear or threshold effects.
- Compare spread across models:
- Linear models tend to produce symmetric spreads.
- Tree or kernel models often show uneven, clustered patterns reflecting interactions.
SHAP explains local contributions, but the beeswarm aggregates them into a global importance view.
❓ Question 6: Do all three representations agree on which features matter most? What does the comparison between logistic regression coefficients and the SHAP plots reveal about the added value of SHAP for the black-box models?
All three approaches broadly agree on the dominant drivers:
- Occupation dummies (especially management and professional roles)
femaleeduc_years- Age / experience variables
However, the way importance manifests differs by model.
Logistic regression
- Coefficients provide a global, linear effect.
- Ranking reflects marginal log-odds contributions.
- Effects are symmetric and additive by construction.
XGBoost (Tree SHAP)
- Shows wider SHAP dispersion.
- Captures nonlinear interactions and threshold effects.
- High education values (red) strongly push predictions upward, but low values (blue) have asymmetric negative impact.
RBF SVM (Kernel SHAP)
- Similar high-level ranking.
- Slightly different magnitudes.
- Greater variability reflects the kernel’s nonlinear geometry.
Key insight:
Where SHAP rankings diverge from logistic regression (especially among mid-ranked features), the likely explanation is nonlinear interaction structure that linear regression cannot represent.
Most importantly:
Even in flexible nonlinear models, female remains among the most influential predictors. The consistency of its importance across model classes strengthens the robustness of the adjusted gender gap finding.
Takeaway
Linear models explain via coefficients. Tree models explain via path-dependent splits. Kernel models explain via local similarity structure.
SHAP unifies these under a single additive attribution framework.
🧮 Multinomial logistic regression and the gender wage gap
We now move from a binary outcome to a three-class outcome:
bottom / middle / top
This allows us to ask:
- What predicts entry into the top of the wage distribution?
- Are effects symmetric across the distribution?
Multinomial logistic regression models the probability of each class simultaneously using a softmax function.
Prepare the multi-class outcome
y_mc = df_enc['wage_tercile']
X_mc_train, X_mc_test, y_mc_train, y_mc_test = train_test_split(
X, y_mc, test_size=0.25, stratify=y_mc, random_state=RANDOM_STATE
)
print(y_mc_train.value_counts())wage_tercile
bottom 29205
top 28413
middle 27622
Name: count, dtype: int64Inspecting class balance (multi-class outcome)
Before fitting a multinomial model, check whether the three wage classes are balanced.
Because wage_tercile is constructed using terciles, the three classes are designed to be roughly equal in size (again up to ties at cut points). That makes macro-averaged metrics (like macro F1) natural, because each class is treated symmetrically.
If one class were substantially rarer, would treating all classes symmetrically in evaluation/training still be appropriate?
Fit the multinomial logistic regression
Logistic regression is fast even on the full training set — no subsampling needed here.
multi_logit = LogisticRegression(solver='lbfgs', max_iter=2000,
random_state=RANDOM_STATE)
multi_logit.fit(X_mc_train, y_mc_train)
print('Classes:', multi_logit.classes_)Classes: ['bottom' 'middle' 'top']The multi_class parameter was removed in scikit-learn ≥ 1.5. With lbfgs and a multiclass target, softmax loss is selected automatically.
Docs: LogisticRegression
Extract and display coefficients
coef_ has shape (n_classes, n_features) — one row per wage class. Reshape into a tidy long DataFrame for plotting.
coef_df = (
pd.DataFrame(multi_logit.coef_,
index=multi_logit.classes_,
columns=ALL_FEATURES)
.stack().reset_index()
)
coef_df.columns = ['class', 'feature', 'log_odds']
coef_df['odds_ratio'] = np.exp(coef_df['log_odds'])
coef_df.sort_values(['class', 'log_odds'], ascending=[True, False])| class | feature | log_odds | odds_ratio | |
|---|---|---|---|---|
| 0 | bottom | female | 0.567733 | 1.764263 |
| 13 | bottom | occ_group_service | 0.469432 | 1.599085 |
| 2 | bottom | potential_exp | 0.329139 | 1.389771 |
| 8 | bottom | black | 0.301952 | 1.352497 |
| 9 | bottom | hispanic | 0.215816 | 1.240873 |
| 1 | bottom | educ_years | 0.125842 | 1.134103 |
| 12 | bottom | occ_group_sales_office | 0.030227 | 1.030688 |
| 7 | bottom | white | -0.056761 | 0.944820 |
| 6 | bottom | public_sector | -0.177406 | 0.837440 |
| 4 | bottom | married | -0.230779 | 0.793915 |
| 3 | bottom | age | -0.349274 | 0.705200 |
| 5 | bottom | union_mem | -0.397536 | 0.671974 |
| 11 | bottom | occ_group_professional | -0.405619 | 0.666564 |
| 10 | bottom | occ_group_management | -0.844736 | 0.429671 |
| 19 | middle | union_mem | 0.173333 | 1.189262 |
| 21 | middle | white | 0.141766 | 1.152307 |
| 22 | middle | black | 0.103459 | 1.109001 |
| 20 | middle | public_sector | 0.100876 | 1.106140 |
| 14 | middle | female | 0.050908 | 1.052226 |
| 17 | middle | age | 0.047177 | 1.048308 |
| 18 | middle | married | 0.034703 | 1.035312 |
| 23 | middle | hispanic | -0.023199 | 0.977068 |
| 16 | middle | potential_exp | -0.046642 | 0.954429 |
| 24 | middle | occ_group_management | -0.049288 | 0.951906 |
| 15 | middle | educ_years | -0.051377 | 0.949921 |
| 26 | middle | occ_group_sales_office | -0.073761 | 0.928893 |
| 25 | middle | occ_group_professional | -0.108074 | 0.897561 |
| 27 | middle | occ_group_service | -0.333691 | 0.716275 |
| 38 | top | occ_group_management | 0.894025 | 2.444950 |
| 39 | top | occ_group_professional | 0.513693 | 1.671452 |
| 31 | top | age | 0.302097 | 1.352692 |
| 33 | top | union_mem | 0.224203 | 1.251326 |
| 32 | top | married | 0.196076 | 1.216619 |
| 34 | top | public_sector | 0.076529 | 1.079534 |
| 40 | top | occ_group_sales_office | 0.043535 | 1.044496 |
| 29 | top | educ_years | -0.074466 | 0.928239 |
| 35 | top | white | -0.085005 | 0.918507 |
| 41 | top | occ_group_service | -0.135740 | 0.873069 |
| 37 | top | hispanic | -0.192616 | 0.824798 |
| 30 | top | potential_exp | -0.282497 | 0.753899 |
| 36 | top | black | -0.405412 | 0.666702 |
| 28 | top | female | -0.618641 | 0.538676 |
Interpreting the coefficients
In multinomial (softmax) logistic regression:
- There is one coefficient vector \(\boldsymbol{\beta}_k\) for each class \(k\).
- \(\mathbf{x}_i\) denotes the feature vector for worker \(i\).
- \(\beta_{k,j}\) is the coefficient on feature \(j\) for class \(k\).
The predicted probability of class \(k\) is:
\[ P(y_i = k \mid \mathbf{x}_i) = \frac{\exp(\boldsymbol{\beta}_k^\top \mathbf{x}_i)} {\sum_{m} \exp(\boldsymbol{\beta}_m^\top \mathbf{x}_i)} \]
This is the softmax function.
Interpretation:
- A one-unit increase in feature \(j\) changes the log-odds of class \(k\) relative to the model’s overall normalisation.
- \(\exp(\beta_{k,j})\) gives the multiplicative change in relative odds for class \(k\), holding other features constant.
Unlike binary logistic regression, there is no single explicit reference category in this parameterisation — probabilities are normalised across all classes.
Coefficients from this model (selected features):
| Feature | β_bottom | β_middle | β_top | Interpretation |
|---|---|---|---|---|
female |
+0.57 | +0.05 | −0.62 | Being female → odds ratio 0.54 for top tercile — a 46% reduction in relative odds, conditional on all other controls |
educ_years |
+0.13 | −0.05 | −0.07 | Weakly positive for bottom, near-zero elsewhere — explained by softmax normalisation (see below) |
potential_exp |
+0.33 | −0.05 | −0.28 | More experience → higher odds of bottom and lower odds of top, conditional on age and occupation |
occ_group_management |
−0.84 | −0.05 | +0.89 | Management occupation → odds ratio 2.44 for top tercile |
union_mem |
−0.40 | +0.17 | +0.22 | Union membership compresses wages upward — reduces bottom odds, raises both middle and top |
On the educ_years sign: The negative coefficient for top may seem surprising — more education reducing top-tercile odds. This is a softmax artefact: the model already controls for age, potential_exp, and occ_group, which are themselves strong positive correlates of both education and wages. Once those are held constant, the marginal education signal shrinks and can even flip sign due to the softmax normalisation. This is not a causal claim — it reflects multicollinearity in the softmax parameterisation.
On potential_exp: The negative sign for top reflects that highly experienced workers (conditional on age, education, and occupation) are not disproportionately concentrated in the top tercile — they cluster in the middle. Early-career workers with high education and management roles drive the top, not tenure per se.
We now plot log-odds and odds ratios for the five focus features.
FOCUS = ['female', 'educ_years', 'potential_exp', 'union_mem', 'public_sector']
plot_df = coef_df[coef_df['feature'].isin(FOCUS)].copy()
order = ['bottom', 'middle', 'top']
colors = ['#2196F3', '#9E9E9E', '#F44336']
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
for ax, metric, zero_line, label in [
(axes[0], 'log_odds', 0, 'Log-odds coefficient (β)'),
(axes[1], 'odds_ratio', 1, 'Odds ratio (exp(β))'),
]:
pivot = plot_df.pivot(index='feature', columns='class', values=metric)[order]
pivot.plot(kind='bar', ax=ax, color=colors, edgecolor='white', width=0.7)
ax.axhline(zero_line, color='black', linewidth=0.8, linestyle='--')
ax.set_title(label, fontsize=12); ax.set_xlabel('')
ax.set_xticklabels([f.replace('_', '\n') for f in pivot.index], rotation=0, fontsize=9)
ax.legend(title='Wage tercile', fontsize=9)
fig.suptitle('Multinomial logit — selected coefficients (CPS-MORG 2019)', fontsize=13)
plt.tight_layout()
plt.show()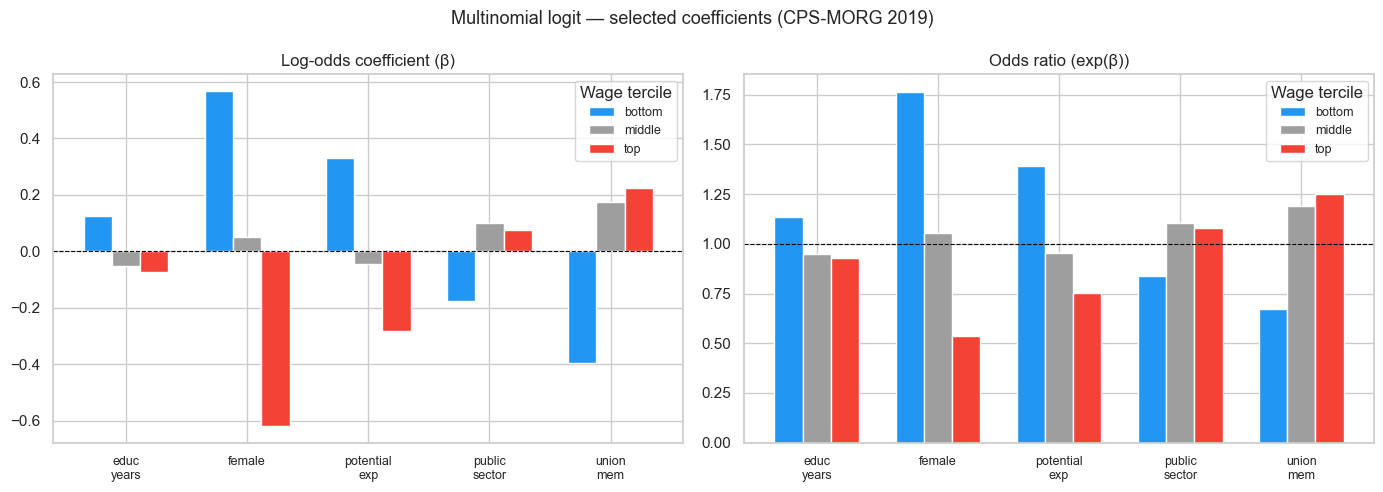
Reading the plot carefully:
female(top class)
β = −0.62 → odds ratio = 0.54.
Holding education, experience, occupation, race, union status, and marital status constant, women have 46% lower relative odds of belonging to the top wage tercile.female(bottom class)
β = +0.57 → odds ratio = 1.76.
Conditional on the same controls, women have substantially higher relative odds of being in the bottom tercile.occ_group_management(top)
Odds ratio = 2.44.
Management occupation more than doubles the relative odds of top-tercile membership.union_mem
Reduces bottom odds (0.67) and increases middle/top odds (>1).
This is consistent with unions compressing wages upward.educ_years
Small or slightly negative coefficients once occupation and experience are controlled.
This reflects multicollinearity within the softmax parameterisation — not evidence that education reduces top wages.
Key conceptual point:
In a softmax model, coefficients are relative contributions to the probability normalisation across all classes. They are not directly comparable to binary logistic regression coefficients.
Cross-validated macro F1
wage_tercile has string labels — use average='macro' with f1_score.
mc_cv = cross_validate(
multi_logit, X, y_mc, cv=cv,
scoring={'f1_macro': 'f1_macro'}
)
scores = mc_cv['test_f1_macro']
print(f'Macro F1: {scores.mean():.4f} ± {scores.std():.4f}')Macro F1: 0.5374 ± 0.0028Note on macro F1:
Macro F1 = 0.537 ± 0.003.
This reflects:
- Balanced class sizes (terciles),
- Equal weighting of bottom, middle, and top,
- Averaging of per-class F1 scores.
A macro F1 around 0.53–0.55 is not low in this setting. For comparison, random guessing across three balanced classes would yield macro F1 ≈ 0.33. Thus, 0.54 represents a substantial improvement over baseline.
Why?
Tercile classification is intrinsically difficult:
- Observations near the 33rd and 66th percentiles lie close to decision boundaries.
- Adjacent-class errors (bottom vs middle, middle vs top) are structurally unavoidable.
- Wage distributions are continuous; terciles impose artificial cutoffs.
The very small standard deviation (±0.003) indicates that performance is stable across folds.
Interpretation:
The model captures systematic structure in the wage distribution, but the problem itself contains inherent boundary noise.
Decision boundaries by gender
We now visualise how the predicted wage-tercile regions differ by gender.
Using the same 2D grid as before:
- Fix all features at their median.
- Set
female = 0in one panel. - Set
female = 1in the other.
Plot the predicted class regions side by side.
class_colors = {'bottom': '#2196F3', 'middle': '#9E9E9E', 'top': '#F44336'}
fig, axes = plt.subplots(1, 2, figsize=(14, 6), sharey=True)
for ax, female_val, title in [
(axes[0], 0, 'Men (female = 0)'),
(axes[1], 1, 'Women (female = 1)'),
]:
g = pd.DataFrame(np.tile(medians.values, (exp_mesh.size, 1)), columns=ALL_FEATURES)
g['potential_exp'] = exp_mesh.ravel()
g['educ_years'] = educ_mesh.ravel()
g['female'] = female_val
preds = multi_logit.predict(g)
for cls, color in class_colors.items():
mask = preds == cls
ax.scatter(g.loc[mask, 'potential_exp'], g.loc[mask, 'educ_years'],
c=color, s=60, marker='s', alpha=0.3, label=cls)
ax.set_xlabel('Potential experience (years)', fontsize=11)
ax.set_title(title, fontsize=12); ax.grid(False)
axes[0].set_ylabel('Education (years)', fontsize=11)
handles = [mpatches.Patch(color=c, label=k.capitalize()) for k, c in class_colors.items()]
fig.legend(handles=handles, title='Predicted wage tercile',
loc='lower center', ncol=3, bbox_to_anchor=(0.5, -0.05))
fig.suptitle('Multinomial logit decision boundaries\n(all other features at median, CPS-MORG 2019)',
fontsize=13)
plt.tight_layout()
plt.show()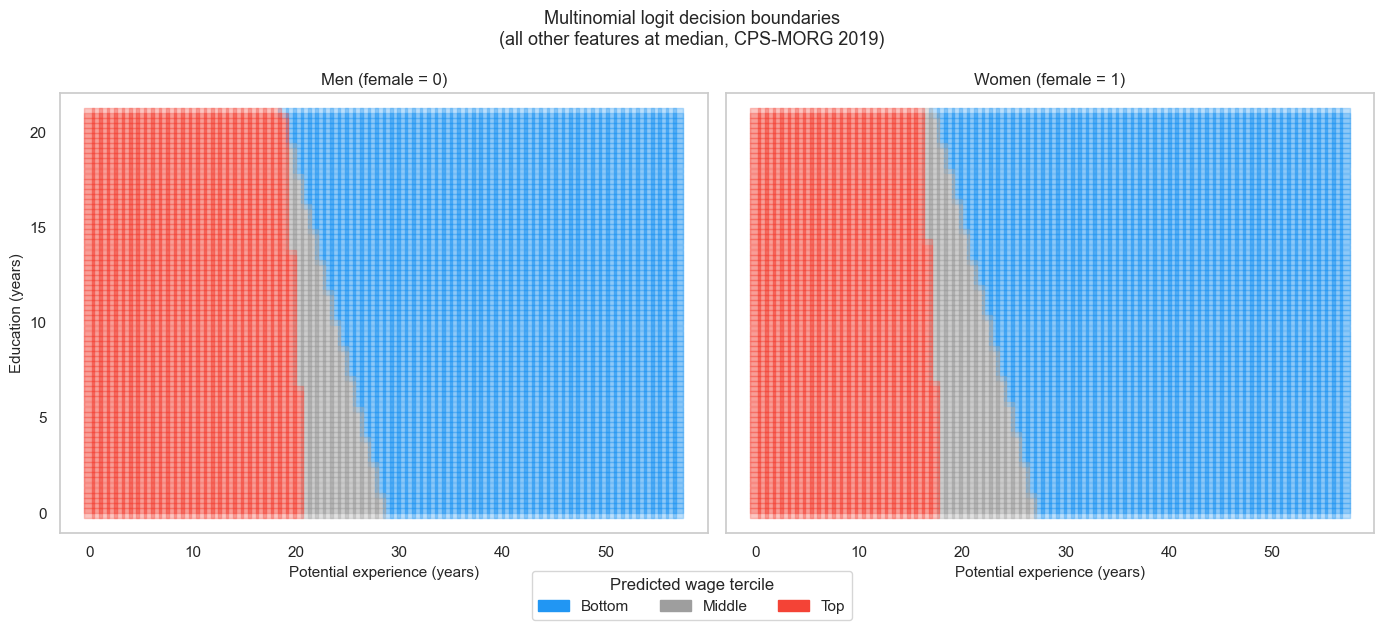
❓ Question 7: Look at the female log-odds for the top class (−0.62, odds ratio 0.54). What does this imply about the adjusted gender wage gap at the top of the distribution? How is this visible in the side-by-side boundary plot?
An odds ratio of 0.54 for female in the top class means that, conditional on observed characteristics, women have 46% lower relative odds of top-tercile membership than comparable men.
In the boundary plot:
- The red (top) region shifts rightward for women.
- Women require more education or experience to enter the top region.
This visual shift represents an adjusted glass-ceiling effect within this model.
❓ Question 8: In scikit-learn’s softmax model, how does the female coefficient for top differ from what you would get in a reference-category model (e.g. statsmodels.MNLogit with bottom as base)? When would each parameterisation be preferable?
In scikit-learn’s softmax model:
- Each class has its own coefficient vector.
- Effects are identified jointly through L2 regularisation.
- Coefficients reflect contributions relative to the global softmax normalisation.
In a reference-category model (e.g. MNLogit with bottom as base):
- Coefficients are explicit log-odds contrasts relative to the base class.
- Interpretation is direct: log-odds(top vs bottom).
Predicted probabilities are equivalent, but coefficients differ numerically.
Use softmax (scikit-learn) for prediction tasks. Use reference-category models (statsmodels) when inference and hypothesis testing with standard errors are central.
❓ Question 9: The model controls for occ_group. Does this mean occupation is fully ‘accounted for’ in the gender gap estimate? What is the debate about whether to include it?
Controlling for occupation isolates the within-occupation gender gap.
However, occupation may lie on the causal pathway from gender to wages (occupational segregation).
If occupation is:
- A confounder → controlling is appropriate.
- A mediator → controlling absorbs part of the gender effect.
Thus:
- Including occupation estimates the conditional gap.
- Excluding occupation estimates the total gap.
Both are defensible depending on the causal question.