
Introduction
In this tutorial we will learn how to scrape data from websites using traditional methods and hidden APIs. QS World University Rankings will be our target website, please familiarise yourself with the website before proceeding. Let’s assume we would like to scrape the following data from the website:
- University name
- Ranking in 2024
- Overall score
- All scores for the different categories
- City, country and region
These data could be used to analyse a multitude of research questions such as:
- How does the ranking of universities change over time?
- What differences are there between universities in different countries?
- What differences are there between universities in different regions?
- How does the ranking correspond to other metrics such as the number of students, the number of faculty members, the number of international students, etc.?
Different methods of scraping
Traditional methods
Traditional methods of scraping involve using the requests library to send HTTP requests to the website and then parsing the HTML response using the BeautifulSoup library. This method is very simple and can be used to scrape most websites given there are no restrictions placed on your IP address. However, this method is not very robust and can break easily if the website changes its HTML structure.
We will be using the requests library for our example, but do also give the httpx library a try—it supports asynchronous requests and is generally faster than requests, but has the same syntax. You can install httpx using pip install httpx.
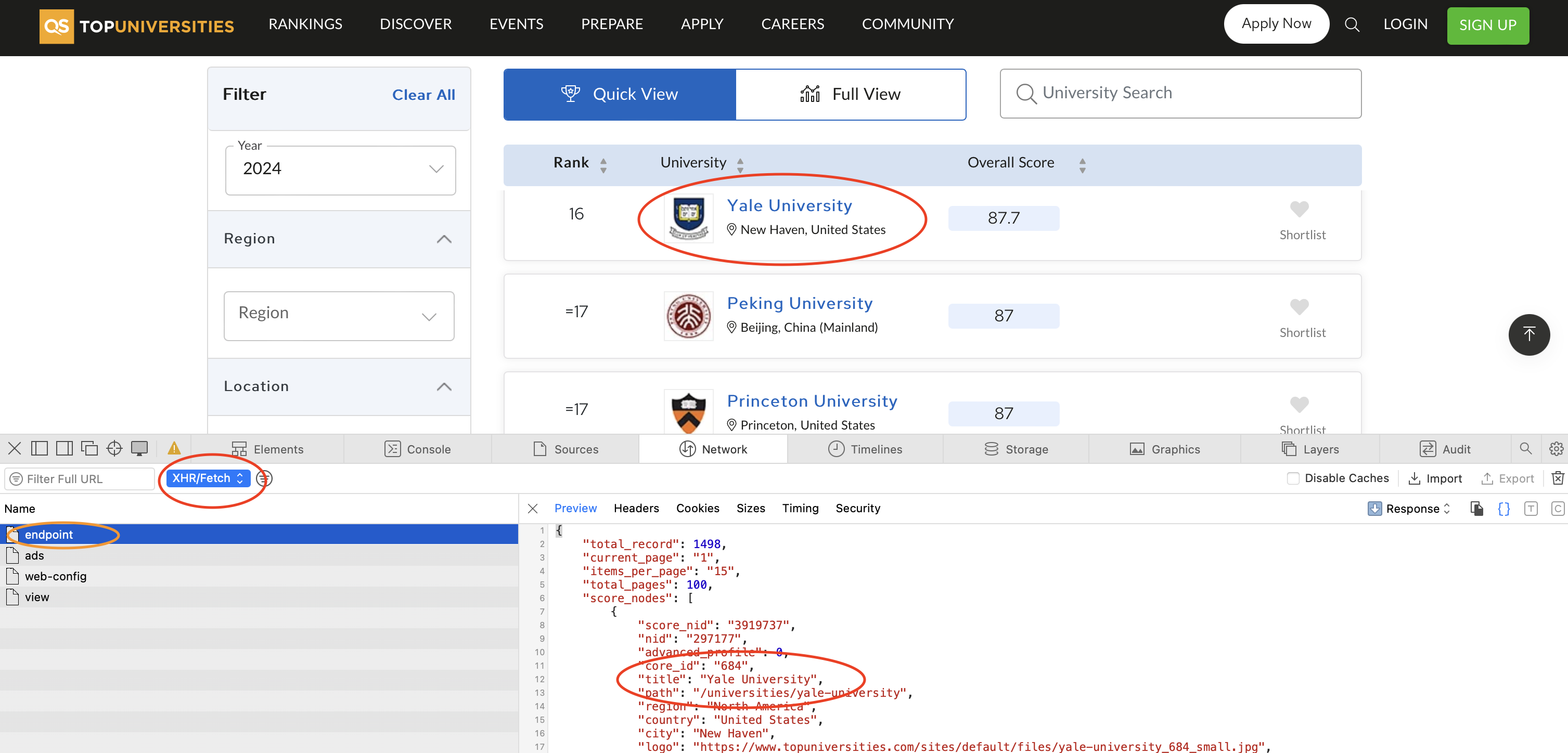
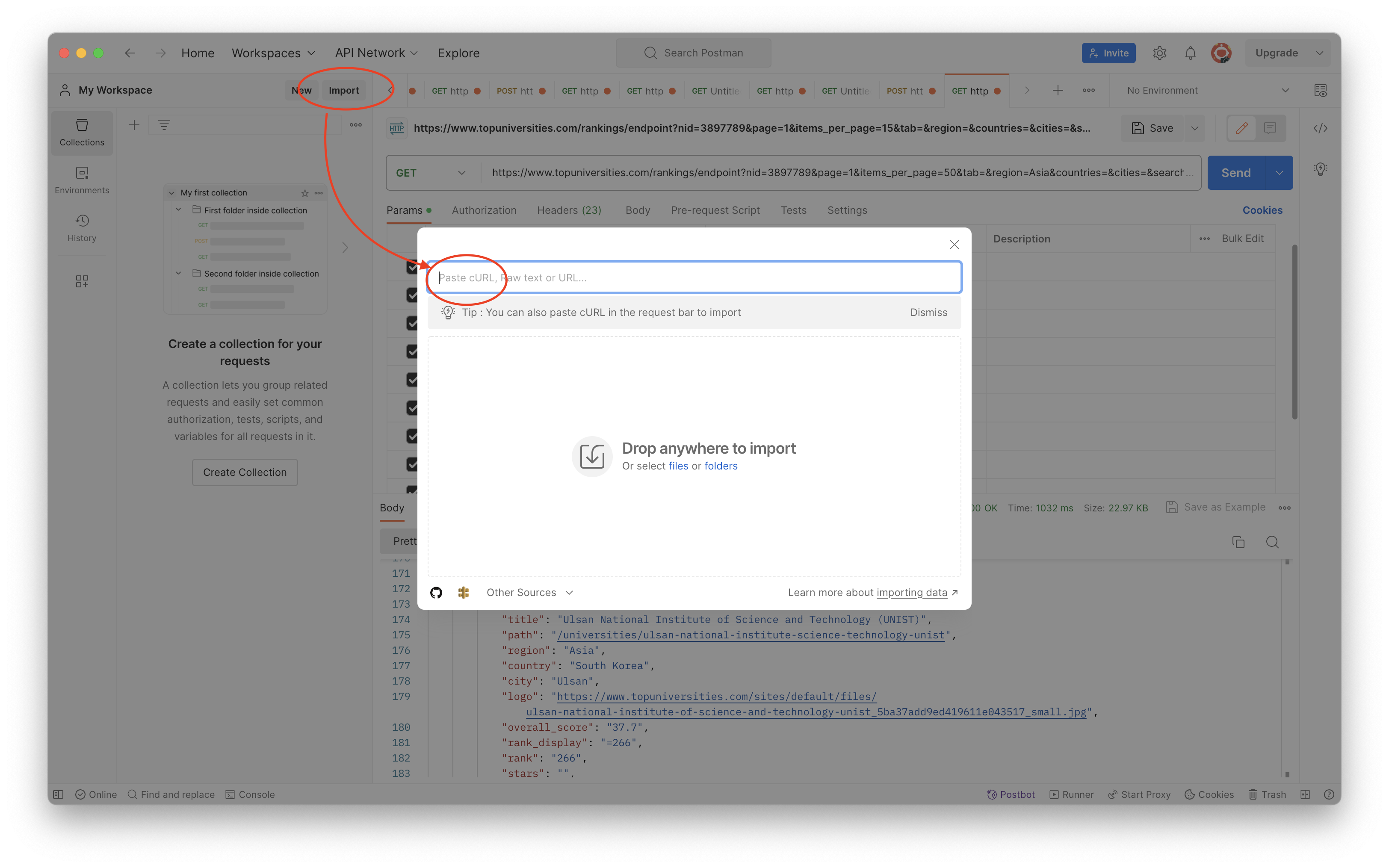
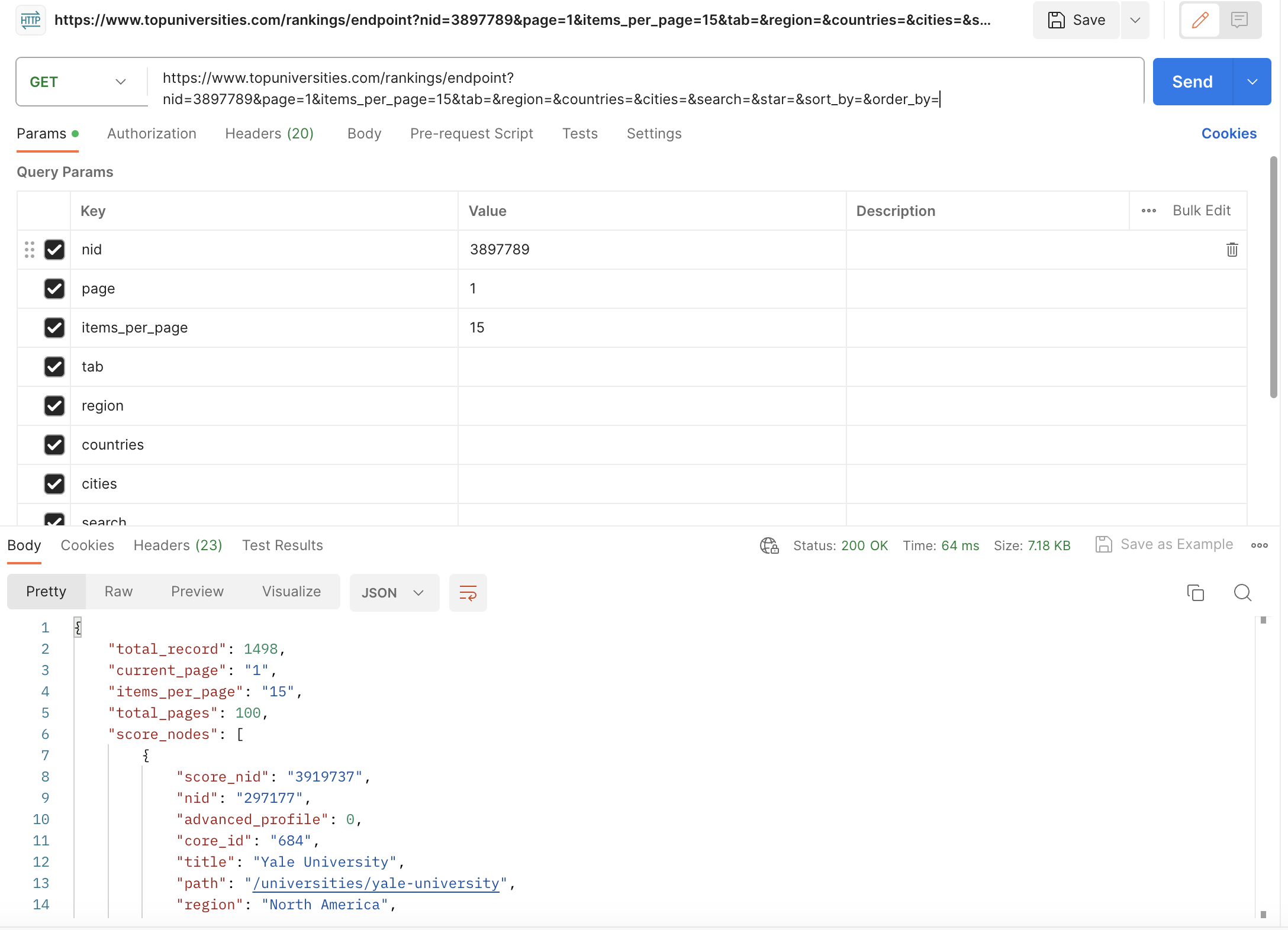
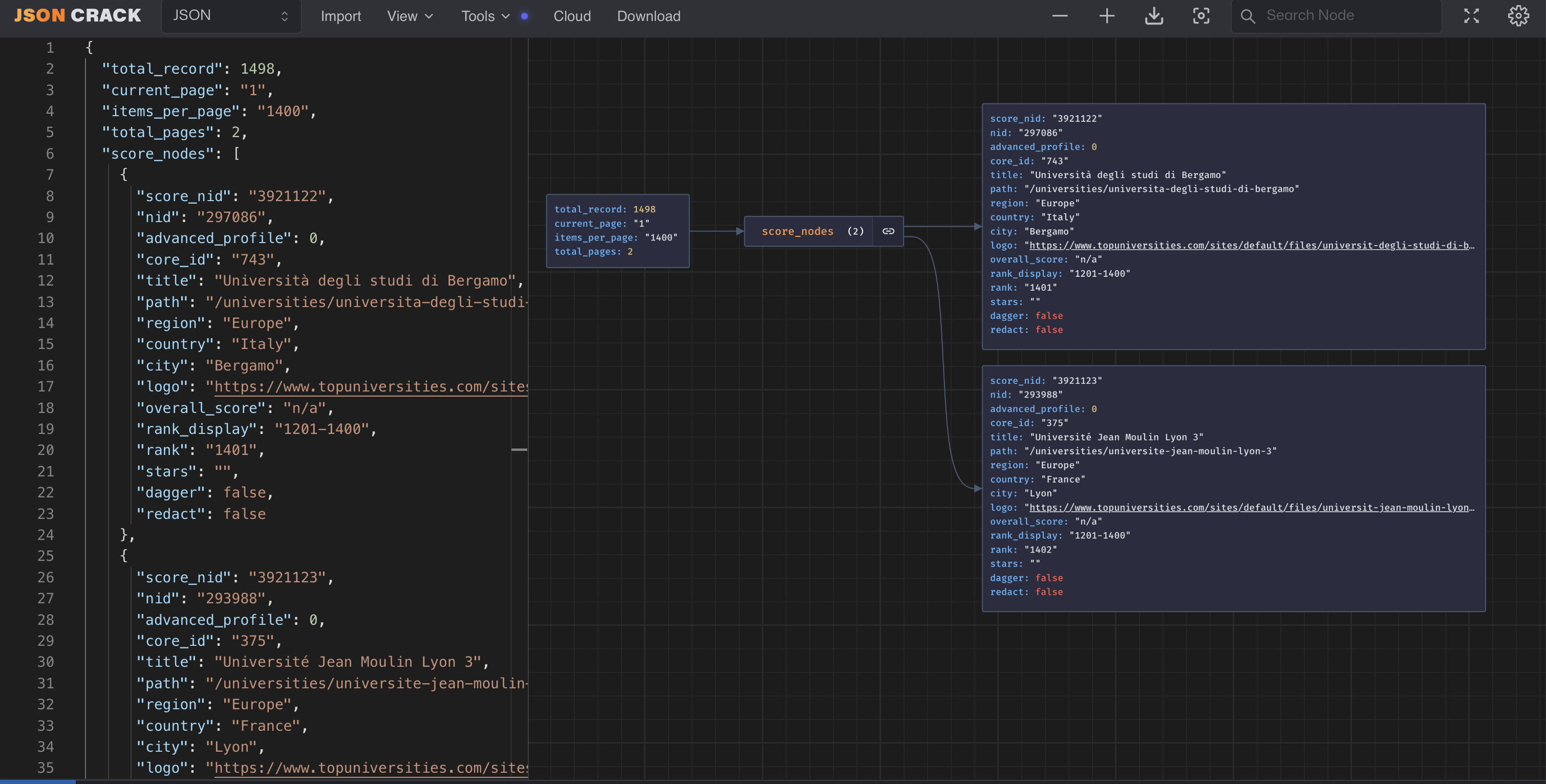
Scraping using traditional methods
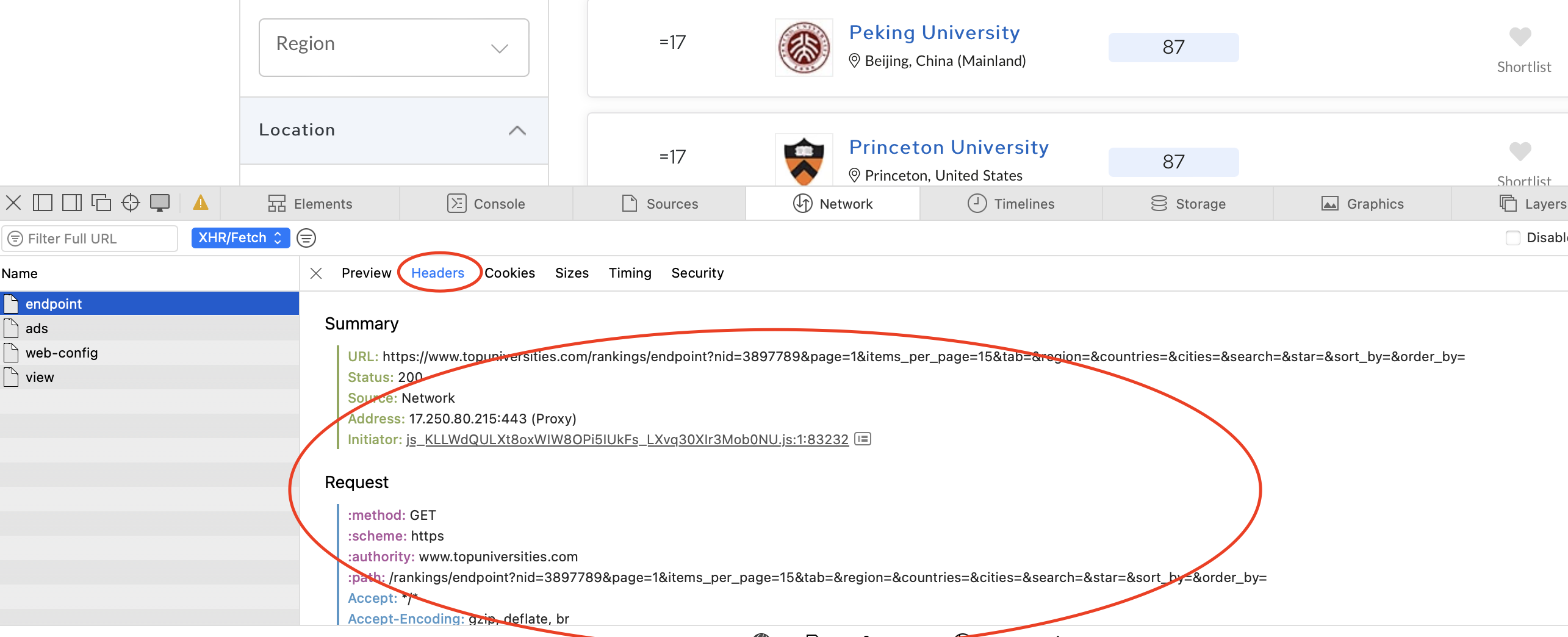
It is relatively simple to find endpoints for scraping data and the output is usually well-structured. We have now obtained the ratings for all universities in the 2024 QS ranking, and one of the data points is the URL ‘slug’ for accessing the webpages of individual universities, which is where the scores for each indicator are stored. If we go to one of the pages, we can use the same process for filtering down requests and finding the endpoint responsible for the data we need. It turns out
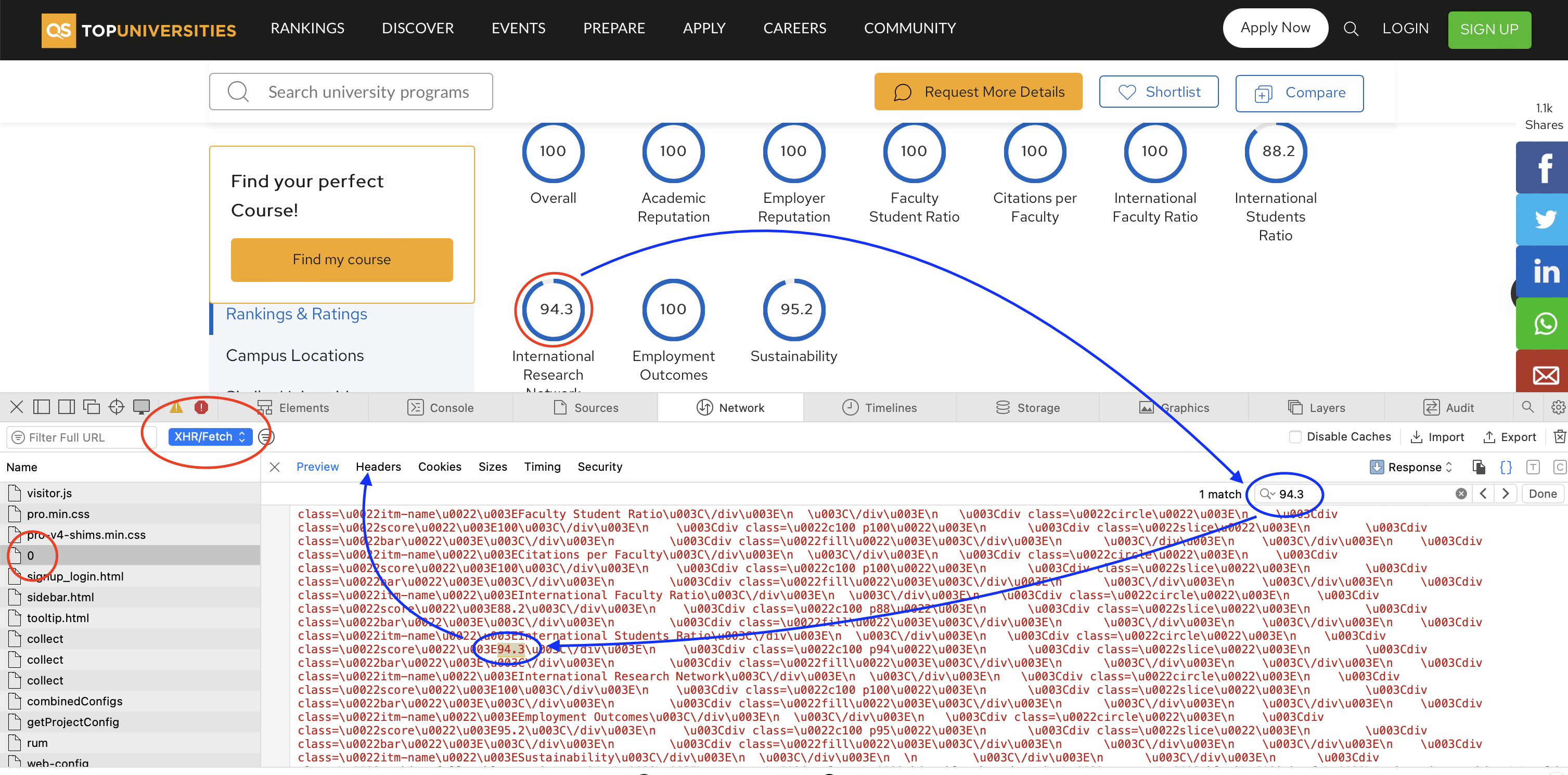
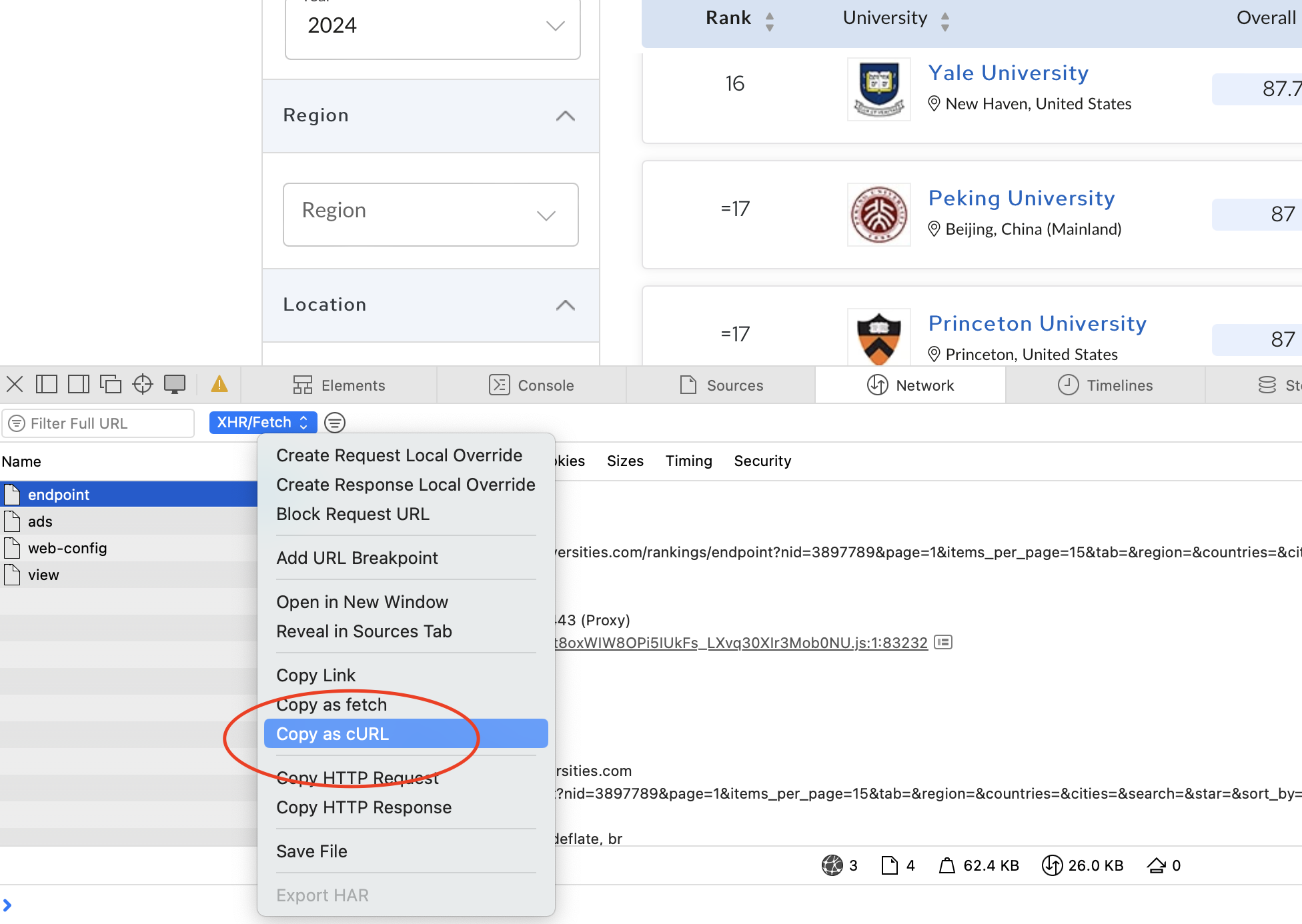
After identifying the request, we can again copy the cURL command and import it into Postman. We can then export it to Python and iterate through all the universities to get the data we need. Notice that this is a POST request, whereas previously we were dealing with GET requests.
Your cURL command should look something like this:
curl 'https://www.topuniversities.com/qs-profiles/rank-data/513/478/0?_wrapper_format=drupal_ajax' \
-X 'POST' \
-H 'Content-Type: application/x-www-form-urlencoded; charset=UTF-8' \
-H 'Accept: application/json, text/javascript, */*; q=0.01' \
-H 'Sec-Fetch-Site: same-origin' \
-H 'Accept-Language: en-GB,en;q=0.9' \
-H 'Accept-Encoding: gzip, deflate, br' \
-H 'Sec-Fetch-Mode: cors' \
-H 'Host: www.topuniversities.com' \
-H 'Origin: https://www.topuniversities.com' \
-H 'Content-Length: 1212' \
-H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.6 Safari/605.1.15' \
-H 'Referer: https://www.topuniversities.com/universities/university-oxford' \
-H 'Connection: keep-alive' \
-H 'Sec-Fetch-Dest: empty' \
-H 'Cookie: STYXKEY_first_visit=yes; mktz_ab=%7B%2258504%22%3A%7B%22v%22%3A1%2C%22l%22%3A134687%7D%7D; mktz_client=%7B%22is_returning%22%3A1%2C%22uid%22%3A%22172262619832803285%22%2C%22session%22%3A%22sess.2.565217329.1696875467083%22%2C%22views%22%3A7%2C%22referer_url%22%3A%22%22%2C%22referer_domain%22%3A%22%22%2C%22referer_type%22%3A%22direct%22%2C%22visits%22%3A2%2C%22landing%22%3A%22https%3A//www.topuniversities.com/universities/massachusetts-institute-technology-mit%22%2C%22enter_at%22%3A%222023-10-9%7C19%3A17%3A47%22%2C%22first_visit%22%3A%222023-10-3%7C16%3A48%3A36%22%2C%22last_visit%22%3A%222023-10-3%7C16%3A48%3A36%22%2C%22last_variation%22%3A%22134687%3D1696877223485%22%2C%22utm_source%22%3Afalse%2C%22utm_term%22%3Afalse%2C%22utm_campaign%22%3Afalse%2C%22utm_content%22%3Afalse%2C%22utm_medium%22%3Afalse%2C%22consent%22%3A%22%22%7D; _ga_16LPMES2GR=GS1.1.1696875469.2.1.1696877221.30.0.0; _ga_5D0D56Z1Z9=GS1.1.1696875469.1.1.1696877221.0.0.0; _ga_YN0B3DGTTZ=GS1.1.1696875469.2.1.1696877221.27.0.0; _ga=GA1.2.560061194.1696348117; _ga_8SLQFC5LXV=GS1.2.1696875469.2.1.1696877218.50.0.0; _gid=GA1.2.1105426707.1696875469; _hjAbsoluteSessionInProgress=0; _hjSession_173635=eyJpZCI6ImJkMTA0ZDkwLTZkZmEtNGU4MS1iYWY2LTBmNTJjMmZlZTg2OCIsImNyZWF0ZWQiOjE2OTY4NzU0Njk2ODQsImluU2FtcGxlIjpmYWxzZSwic2Vzc2lvbml6ZXJCZXRhRW5hYmxlZCI6ZmFsc2V9; __hssc=238059679.6.1696875470238; __hssrc=1; __hstc=238059679.00da05ec1d70ffb25c243f6a9eeb8cce.1696348118645.1696348118645.1696875470238.2; _fbp=fb.1.1696348117607.443804054; hubspotutk=00da05ec1d70ffb25c243f6a9eeb8cce; _gcl_au=1.1.1619037028.1696348117; _hjIncludedInSessionSample_173635=0; _hjSessionUser_173635=eyJpZCI6ImZkNzU2NzkzLTQxODItNTkwOC1iZjkyLTIwMjJiZDRiNDkzNSIsImNyZWF0ZWQiOjE2OTYzNDgxMTc4NjMsImV4aXN0aW5nIjp0cnVlfQ==; _gat_%5Bobject%20Object%5D=1; _gat_UA-223073533-1=1; _gat_UA-37767707-2=1; STYXKEY-user_survey=other; STYXKEY-user_survey_other=; STYXKEY-globaluserUUID=TU-1696875469298-84871097; mktz_sess=sess.2.565217329.1696875467083; __gads=ID=1157ddb27ff3be5a:T=1696348116:RT=1696348471:S=ALNI_Mb-2oHbrUmHI1cdHEugn-QF96rgEw; __gpi=UID=00000c8b9f3cdb41:T=1696348116:RT=1696348471:S=ALNI_MZUO-lvaEUqOejr5VPKMtpI2JY8Xg; sa-user-id=s%253A0-e6c12fca-af8d-42c6-4916-01680edc9fd5.j9WTOoI7TxfVNyC%252Bv%252FdVCmnmXYcLof1jmZyeL3NxcPY; sa-user-id-v2=s%253A5sEvyq-NQsZJFgFoDtyf1aziACI.ry2%252Bk1GJLTDWLdtrd%252B4MEEIItJsZhL7RAAspSMY5bVY; sa-user-id-v3=s%253AAQAKIBbb9JwS4hQF5PN5wvfoh8VY72kjgv3fCqon_R3rCJDAEG4YBCD_7_CoBigBOgRSIcquQgQDXf_T.ZWjQiq%252FulN34TyYO6iMJgqkpq3BX9A%252BFiT3Hft5fcnM; cookie-agreed=2; cookie-agreed-version=1.0.0' \
-H 'X-Requested-With: XMLHttpRequest' \
--data 'js=true&_drupal_ajax=1&ajax_page_state%5Btheme%5D=tu_d8&ajax_page_state%5Btheme_token%5D=&ajax_page_state%5Blibraries%5D=addtoany%2Faddtoany.front%2Cckeditor_accordion%2Faccordion.frontend%2Cclientside_validation_jquery%2Fcv.jquery.ckeditor%2Cclientside_validation_jquery%2Fcv.jquery.ife%2Cclientside_validation_jquery%2Fcv.jquery.validate%2Cclientside_validation_jquery%2Fcv.pattern.method%2Ccore%2Fdrupal.form%2Ccore%2Fdrupal.states%2Ccore%2Fnormalize%2Ceu_cookie_compliance%2Feu_cookie_compliance_bare%2Cflag%2Fflag.link_ajax%2Cga%2Fanalytics%2Clayout_discovery%2Fonecol%2Cqs_article%2Fqs_article%2Cqs_firebase_sso%2Fsso-lib%2Cqs_firebase_sso%2Fsso-lib-header%2Cqs_flexreg_user_flow%2Fqs_flexreg_user_flow%2Cqs_global_site_search%2Fsearch_header%2Cqs_profiles%2Fhighcharts%2Cqs_profiles%2Fqs_profiles%2Cqs_profiles%2Fqs_profiles_circle%2Cqs_user_profile%2FqsUserProfile%2Csystem%2Fbase%2Ctu_d8%2Fglobal%2Ctu_d8%2Fnode%2Ctu_d8%2Fprofile_header%2Ctu_d8%2Fqna_forums%2Ctu_d8%2Fqs_campus_locations%2Ctu_d8%2Fqs_instant%2Ctu_d8%2Fqs_profile_new%2Ctu_d8%2Fqs_profile_new_datalayer%2Ctu_d8%2Fqs_program_tabs%2Ctu_d8%2Fqs_ranking_chart%2Ctu_d8%2Fqs_related_content%2Ctu_d8%2Fqs_similar_programs%2Cviews%2Fviews.module'Here is what the request looks like in Postman:
cURL command for the POST requestA POST request means that the parameters are sent in the body of the request rather than in the URL; however, in our case it seems that the unique ID of each university is sent in the URL. We can try to change the ID to see if we can get data for other universities.
url = "https://www.topuniversities.com/qs-profiles/rank-data/513/478/0?_wrapper_format=drupal_ajax"This is the request sent to get the data for MIT, and in our qs_ranking_1.json file we can see that the ID for MIT is 478. Let’s try to change it to 362, which is the ID for LSE.
url = "https://www.topuniversities.com/qs-profiles/rank-data/513/362/0?_wrapper_format=drupal_ajax"The request is successful and we do indeed get the indicators for LSE. This means we can gather all the unique IDs for all the universities and iterate through them to get the data we need. However, as you might have seen, the data passed in the JSON response is still formatted in HTML, so me might need to do some cleaning before we can put it in a tabular format—this is where traditional scraping methods come in handy.
import json
from pprint import pprint
# open files beginning with `qs_ranking_`
# iterate through the files and append the data to a list
unis = []
for page in range(1, 3):
with open(f'qs_ranking_{page}.json', 'r') as f:
unis.extend(json.load(f)['score_nodes']) # read up on the difference between `extend` and `append`
pprint(unis[:2])Now we have a list of dictionaries, but we need a list of unique IDs Here they seem to be represented by the core_id key
Let’s create a list of unique IDs to scrape. We can use a for loop to iterate through the list of dictionaries and append the IDs to a new list. We can then use the set function to deduplicate the list.
uni_ids = []
for uni in unis:
uni_ids.append(uni['core_id'])
# Deduplicate the list
uni_ids = list(set(uni_ids))
# Let's check the length of the list of unique IDs
print(len(uni_ids))
# and a few items from the list
print(uni_ids[:5])We can use a similar method to the one we used previously to save the data to JSON files. It is probably a good idea just to save the JSON files for now and then later parse them for useful information—this way we don’t have to worry about getting the right data from the HTML stright away and instead focus on procuring it first.
This is a working request that we exported as Python code from Postman based on the cURL command above.
import requests
url = "https://www.topuniversities.com/qs-profiles/rank-data/513/410/0?_wrapper_format=drupal_ajax"
payload = "js=true&_drupal_ajax=1&ajax_page_state%5Btheme%5D=tu_d8&ajax_page_state%5Btheme_token%5D=&ajax_page_state%5Blibraries%5D=addtoany%2Faddtoany.front%2Cckeditor_accordion%2Faccordion.frontend%2Cclientside_validation_jquery%2Fcv.jquery.ckeditor%2Cclientside_validation_jquery%2Fcv.jquery.ife%2Cclientside_validation_jquery%2Fcv.jquery.validate%2Cclientside_validation_jquery%2Fcv.pattern.method%2Ccore%2Fdrupal.form%2Ccore%2Fdrupal.states%2Ccore%2Fnormalize%2Ceu_cookie_compliance%2Feu_cookie_compliance_bare%2Cflag%2Fflag.link_ajax%2Cga%2Fanalytics%2Clayout_discovery%2Fonecol%2Cqs_article%2Fqs_article%2Cqs_firebase_sso%2Fsso-lib%2Cqs_firebase_sso%2Fsso-lib-header%2Cqs_flexreg_user_flow%2Fqs_flexreg_user_flow%2Cqs_global_site_search%2Fsearch_header%2Cqs_profiles%2Fhighcharts%2Cqs_profiles%2Fqs_profiles%2Cqs_profiles%2Fqs_profiles_circle%2Cqs_user_profile%2FqsUserProfile%2Csystem%2Fbase%2Ctu_d8%2Fglobal%2Ctu_d8%2Fnode%2Ctu_d8%2Fprofile_header%2Ctu_d8%2Fqna_forums%2Ctu_d8%2Fqs_campus_locations%2Ctu_d8%2Fqs_instant%2Ctu_d8%2Fqs_profile_new%2Ctu_d8%2Fqs_profile_new_datalayer%2Ctu_d8%2Fqs_program_tabs%2Ctu_d8%2Fqs_ranking_chart%2Ctu_d8%2Fqs_related_content%2Ctu_d8%2Fqs_similar_programs%2Cviews%2Fviews.module"
headers = {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Sec-Fetch-Site': 'same-origin',
'Accept-Language': 'en-GB,en;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Sec-Fetch-Mode': 'cors',
'Host': 'www.topuniversities.com',
'Origin': 'https://www.topuniversities.com',
'Content-Length': '1212',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.6 Safari/605.1.15',
'Referer': 'https://www.topuniversities.com/universities/massachusetts-institute-technology-mit',
'Connection': 'keep-alive',
'Sec-Fetch-Dest': 'empty',
'Cookie': 'STYXKEY_first_visit=yes; mktz_ab=%7B%2258504%22%3A%7B%22v%22%3A1%2C%22l%22%3A134687%7D%7D; mktz_client=%7B%22is_returning%22%3A1%2C%22uid%22%3A%22172262619832803285%22%2C%22session%22%3A%22sess.2.565217329.1696875467083%22%2C%22views%22%3A2%2C%22referer_url%22%3A%22%22%2C%22referer_domain%22%3A%22%22%2C%22referer_type%22%3A%22direct%22%2C%22visits%22%3A2%2C%22landing%22%3A%22https%3A//www.topuniversities.com/universities/massachusetts-institute-technology-mit%22%2C%22enter_at%22%3A%222023-10-9%7C19%3A17%3A47%22%2C%22first_visit%22%3A%222023-10-3%7C16%3A48%3A36%22%2C%22last_visit%22%3A%222023-10-3%7C16%3A48%3A36%22%2C%22last_variation%22%3A%22134687%3D1696875480078%22%2C%22utm_source%22%3Afalse%2C%22utm_term%22%3Afalse%2C%22utm_campaign%22%3Afalse%2C%22utm_content%22%3Afalse%2C%22utm_medium%22%3Afalse%2C%22consent%22%3A%22%22%7D; _ga_16LPMES2GR=GS1.1.1696875469.2.0.1696875478.51.0.0; _ga_5D0D56Z1Z9=GS1.1.1696875469.1.0.1696875478.0.0.0; _ga_YN0B3DGTTZ=GS1.1.1696875469.2.0.1696875478.51.0.0; _ga=GA1.2.560061194.1696348117; _ga_8SLQFC5LXV=GS1.2.1696875469.2.1.1696875473.56.0.0; _gid=GA1.2.1105426707.1696875469; __hssc=238059679.1.1696875470238; __hssrc=1; __hstc=238059679.00da05ec1d70ffb25c243f6a9eeb8cce.1696348118645.1696348118645.1696875470238.2; hubspotutk=00da05ec1d70ffb25c243f6a9eeb8cce; _fbp=fb.1.1696348117607.443804054; _gat_%5Bobject%20Object%5D=1; _gat_UA-223073533-1=1; _gat_UA-37767707-2=1; _gcl_au=1.1.1619037028.1696348117; _hjAbsoluteSessionInProgress=0; _hjIncludedInSessionSample_173635=0; _hjSessionUser_173635=eyJpZCI6ImZkNzU2NzkzLTQxODItNTkwOC1iZjkyLTIwMjJiZDRiNDkzNSIsImNyZWF0ZWQiOjE2OTYzNDgxMTc4NjMsImV4aXN0aW5nIjp0cnVlfQ==; _hjSession_173635=eyJpZCI6ImJkMTA0ZDkwLTZkZmEtNGU4MS1iYWY2LTBmNTJjMmZlZTg2OCIsImNyZWF0ZWQiOjE2OTY4NzU0Njk2ODQsImluU2FtcGxlIjpmYWxzZSwic2Vzc2lvbml6ZXJCZXRhRW5hYmxlZCI6ZmFsc2V9; STYXKEY-globaluserUUID=TU-1696875469298-84871097; mktz_sess=sess.2.565217329.1696875467083; __gads=ID=1157ddb27ff3be5a:T=1696348116:RT=1696348471:S=ALNI_Mb-2oHbrUmHI1cdHEugn-QF96rgEw; __gpi=UID=00000c8b9f3cdb41:T=1696348116:RT=1696348471:S=ALNI_MZUO-lvaEUqOejr5VPKMtpI2JY8Xg; sa-user-id=s%253A0-e6c12fca-af8d-42c6-4916-01680edc9fd5.j9WTOoI7TxfVNyC%252Bv%252FdVCmnmXYcLof1jmZyeL3NxcPY; sa-user-id-v2=s%253A5sEvyq-NQsZJFgFoDtyf1aziACI.ry2%252Bk1GJLTDWLdtrd%252B4MEEIItJsZhL7RAAspSMY5bVY; sa-user-id-v3=s%253AAQAKIBbb9JwS4hQF5PN5wvfoh8VY72kjgv3fCqon_R3rCJDAEG4YBCD_7_CoBigBOgRSIcquQgQDXf_T.ZWjQiq%252FulN34TyYO6iMJgqkpq3BX9A%252BFiT3Hft5fcnM; cookie-agreed=2; cookie-agreed-version=1.0.0',
'X-Requested-With': 'XMLHttpRequest'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)The only thing we need to change here is the core_id within the URL. We have 1498 unique ID to get through, so it would be a good idea to save the data with the ID as the filename. We can also add a sleep function to avoid overloading the server with requests—but this is optional for now as we will only do a few requests.
# Let's create a function that will save the JSON files for us.
def save_json(data: str, filename:str):
with open(filename, 'w') as f:
f.write(data)It might also be a good idea to save the data in a separate folder. We can use the os library to create a folder if it does not exist yet.
import os
# Create a folder called `data` if it does not exist yet
if not os.path.exists('data'):
os.mkdir('data')Now we can iterate through the list of unique IDs and save the data to JSON files.
import requests
import time
from tqdm.notebook import tqdm # a progress bar library
import os # a library for working with files and folders
url = "https://www.topuniversities.com/qs-profiles/rank-data/513/{}/0?_wrapper_format=drupal_ajax" # notice the {} in the URL---this is a placeholder for the ID
# Create a folder called `data` if it does not exist yet
if not os.path.exists('data'):
os.mkdir('data')
for id in tqdm(uni_ids[:5]):
print(f"Saving data for {id}")
# make a POST request instead of a GET request
response = requests.request("POST", url.format(id), headers=headers, data=payload)
save_json(response.text, f"data/{id}.json")
time.sleep(1)Explore the structure of the files you have saved. Within each of them, we can see the HTML for the indicators—it seeems to be within the last dictionary in a list. There are also some additional data about historical ratings that you might want to make use of in eg. finding out which regions have had the most impressive improvements over the past decade. As we are only interested in the 2024 indicators, however, we can extract the HTML and its associated university ID, then use Scrapy Selectors to parse the HTML and extract the data we need.
Saving the files and parsing them later allows you to separate the data collection and data processing steps. This can be beneficial for a few reasons:
Reduced server load: By saving the data to files and processing it later, you can avoid overloading the server with too many requests at once. This can help prevent your IP address from being blocked or banned by the server.
Flexibility: Saving the data to files allows you to work with the data at your own pace and on your own schedule. You can parse the data when it’s convenient for you, and you can easily re-parse the data if you need to make changes to your parsing code.
Data backup: Saving the data to files provides a backup in case something goes wrong during the parsing process. If your parsing code encounters an error or if your computer crashes, you can simply re-run the parsing code on the saved data rather than having to re-collect the data from scratch.
# Create an empty dictionary to store the university data
uni_data = {}
# Loop through each file in the `data` folder
for filename in os.listdir('data'):
# Open the file and read in the JSON data
with open(f'data/{filename}', 'r') as f:
json_data = json.load(f)
# Get the ID of the university from the filename
uni_id = filename.split('.')[0]
# Add a new key-value pair to the `uni_data` dictionary
# where the key is the ID and the value is the last dictionary
# in the list of dictionaries in the JSON data
uni_data[uni_id] = json_data[-1]['data']Now that we have the HTML, we can use Scrapy Selectors to parse it and extract the data.
from scrapy import Selector
# Let's create a function that will extract the data we need from the HTML
def extract_data(html: str):
# define a selector
sel = Selector(text=html)
# extract the data from div.circle---this gives you a list of Scrapy selector objects which you can drill down into
indicators = sel.css('div.circle')
# create a dictionary to store the data
indicator_data = {}
# iterate through the indicators and extract the data
for indicator in indicators:
indicator_name = indicator.css('.itm-name::text').get().strip()
indicator_value = indicator.css('.score::text').get().strip()
# Store data in a dictionary
indicator_data[indicator_name] = indicator_value
return indicator_data
# Let's test the function on the HTML we have saved
extract_data(uni_data['2551'])
# And now we can iterate through the dictionary and extract the data for each university
for id, data in uni_data.items():
uni_data[id] = extract_data(data)Now we have a dictionary with the data we need. We can use pandas to convert it to a dataframe and save it to a CSV file.
import pandas as pd
df = pd.DataFrame.from_dict(uni_data, orient='index')
df.head()
# and then save it to a CSV file
df.to_csv('qs_indicators.csv')Now we have a dataframe with all the indicators for all the universities, however, the data are missing university names, regions, and weblinks that we received with the previous request. We can use the core_id to join the two dataframes together. First, let us load the data from the previous request.
import json
import pandas as pd
# Open the json file
with open('qs_ranking_1.json', 'r') as f:
data = json.load(f)
# get into the `score_nodes` key which contains required data
data = data['score_nodes']
# convert to a pandas dataframe
unis_df = pd.DataFrame.from_dict(data)
# Merge the two dataframes together
unis_df = unis_df.merge(df, left_on='core_id', right_index=True)
# Save the dataframe to a CSV file
unis_df.to_csv('qs_ranking.csv')Let’s take a look at the dataframe we have created.
import pandas as pd
unis_df = pd.read_csv('qs_ranking.csv', index_col=0)
unis_df.head()This data set now contains all the information we need to answer the questions we set out to answer. You can now use the data to create visualisations, perform statistical analysis, or build a machine learning model.
Summary
In this tutorial, we have learned
- how to use
Postmanto identify the requests responsible for getting the data we need and how to export them to Python - how to save the data to files and how to parse it later
- how to use
Scrapy Selectorsto parse HTML and extract the data we need - how to join two dataframes together using a common key
- how to save the data to a CSV file.
Happy scraping!