
✍️ W10 Summative (30%)
2024/25 Autumn Term
This is the second graded problem set, and is worth 30% of your final grade in this course. We expect to see a lot of pandas skills for parsing JSON data, SQLite skills for storing the data, and data visualisation skills using the lets-plot library.
This assignment is part of the COURSEWORK component of your grade in this course.
📌 Watch a walkthrough of this assignment
⏲️ Due Date:
- 3 December 2024 at 8 pm UK time (2 weeks and 1 day from when these instructions were released)
About Extensions
- This time around, we will only grant extension to students whose reasons merit an extension at LSE.
👉 Fill out the extension request form and 📧 (Kevin) before the deadline.
📝 Instructions
Here, you will find what we want from you in this assignment. Unlike the previous exercises, you can do part of this assignment in pairs. You will still be graded individually.
💽 Data and Question
Question: We want you to be creative! This time, you have to come up with your own questions that can be answered using exploratory data analysis from the Spotify API. Clearly state your question in your README.md and notebook(s).
Data Source: Explore the Spotify API documentation to get an idea of the many endpoints and data available to you. You are required to use at least two different endpoint categories
- Example: You might want to collect data from the
artists(1 endpoint category) andalbums(another endpoint category) to answer a question about the relationship between the popularity of an artist and the popularity of their albums.
- Example: You might want to collect data from the
💻 Technical Requirements
Data Collection: We expect you to create a notebook called
code/NB01 - Data Collection.ipynb.In this notebook, you will use the
requestslibrary to collect data from the Spotify API and save the individual raw JSON responses to files in thedata/raw/directory. 1Data Storage: Create a notebook called
code/NB02 - Data Processing.ipynb.In this notebook, read the raw JSON responses from the
data/raw/directory into Pandas DataFrames and pre-process the data until you produce a SQLite database 2 file in thedata/directory.No lists, dictionaries this time around. Use Pandas for all the subsequent data manipulation tasks after reading the raw JSON responses into DataFrames.
You must design at least two tables
These two tables must be linked with at least one foreign key relationship.
Data types must be as economical as possible when it comes to storage. Ensure your database schema is efficient and avoids unnecessary data duplication.
Example: If you have data about artists and albums, you might have two tables:
artistsandalbums. Thealbumstable would have a foreign key column that links to theartiststable.
Data Visualisation: Create a notebook called
code/NB03 - Data Visualisation.ipynb.Read data directly from your SQLite database into Pandas DataFrames. Prepare the data for visualisation and create at least two visualisations to answer your overall question, using the
lets-plotlibrary’sggplot()function to explore and answer your question.
🔐 API Credentials
(This will be covered in Week 08 Lecture)
🚨 IMPORTANT: Unlike the OpenMeteo where you can just simply send a request to the API, you need to create a developer account on Spotify and then authenticate before you request any data! You will find more on that at the end of the
Follow the instructions on the Spotify API page to create a developer account and obtain your API credentials.
- Safely store your API credentials on the
.envfile in your repository. - Do not ever push your
.envfile to GitHub. It should be listed in your.gitignorefile.
👥 Individual vs Pairs: You Decide
You can choose to do this project by yourself or in pairs. There are pros and cons to each option, so it is up to you to decide which one is best for you.
Individual: You will be expected to produce all three Jupyter Notebooks in your GitHub repository.
In Pairs: Working in pairs mean you will work on the first two notebooks together, but you will each be responsible for your individual data visualisation notebook.
- There has to be two NB03 notebooks in the repository, one from each of you.
- Name them according to your GitHub username:
code/NB03 - Data Visualisation - <username>.ipynb. - Both of you will use the same GitHub repository (more on that below)
- However, the questions you pose to the data on the
NB03 - Data Visualisation.ipynbnotebook MUST be different. - The
data/directory should contain the same data files for both of you. - You will be graded individually.
Prepare the  GitHub Repository
GitHub Repository
Decide if you are working alone or in pairs:
If you want to work in pairs, you need to decide before you start working on the assignment. You can’t change your mind later, sadly.
If working alone, keep following the instructions below. If working in pairs, follow the instructions below together.
Find the GitHub assignment link:
Click here to go to the Slack post in the
#announcementschannel where you will find the link to the GitHub assignment or click here to go to the Moodle version of this instructions where the link is available.We don’t share the link publicly. It is a private repository for enrolled students only.
Specify a ‘team name’ and accept the assignment:
Once you click the link you will see this page:
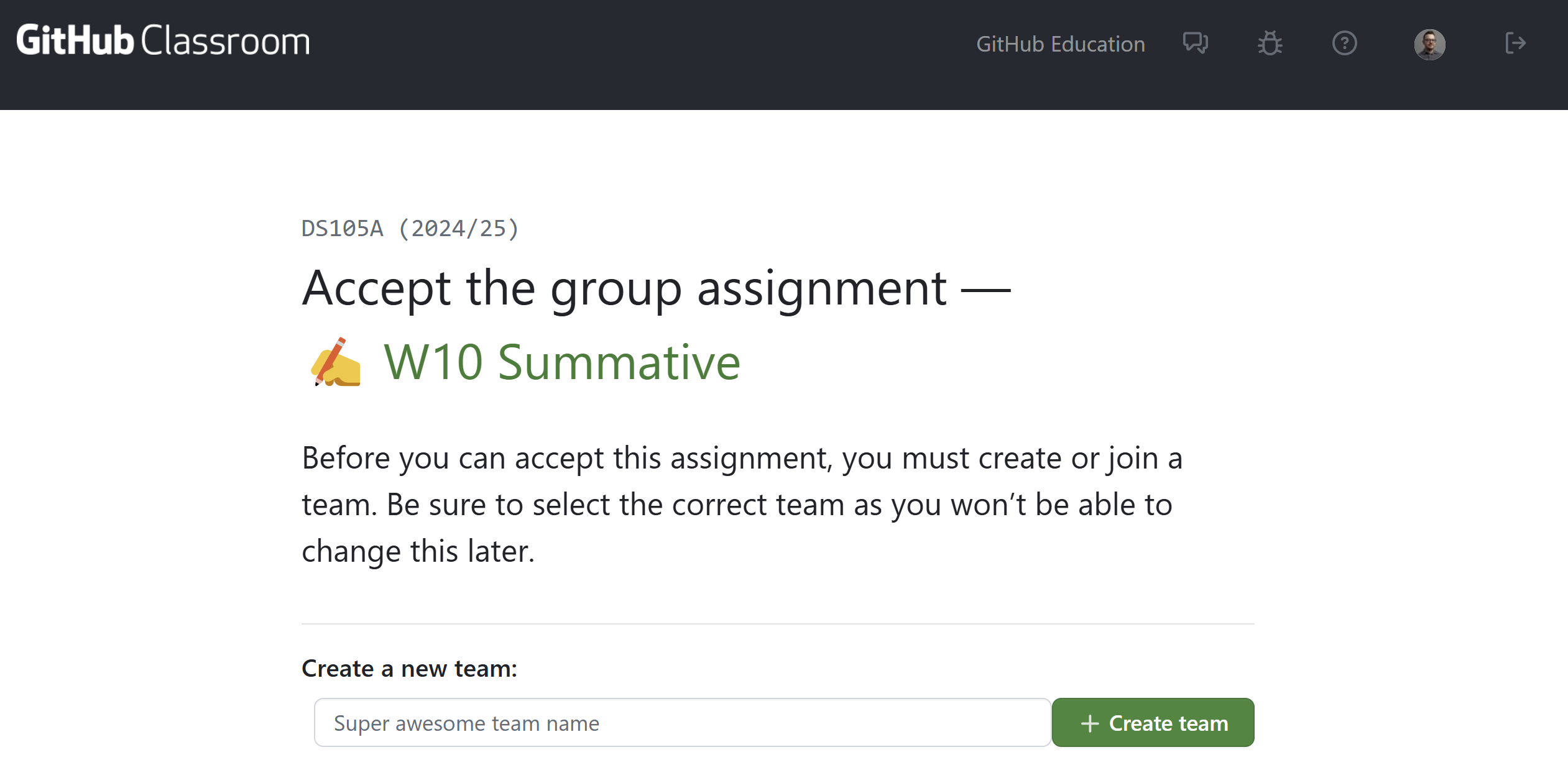
If you are working alone: Type in your GitHub username in the ‘Team Name’ field and click ‘Create team’. Then accept the assignment.
If you are working in pairs: One of you should do this first. Type in your GitHub usernames separated by two underscores in the ‘Team Name’ field and click ‘Create team’.
💡 For example, if your GitHub usernames are
aliceandbob, you should typealice__bobin the ‘Team Name’ field. If I am creating a repository with Riya, for example, we would typejonjoncardoso__RiyaChhikaraas our ‘Team Name’.Then, accept the assignment. In the final page, you will see that a repository has been created for both of you.
The second person should refresh the GitHub assignment page and select the team name that was created by the first person.
You should both have access to the same repository now.
(Optional) Keep an AI chat window for this assignment.
If you like to use OpenAI’s ChatGPT or Google’s Gemini for coding assistance, it might be a good idea to create a separate chat window just for this assignment 3. Then, when you’re done, export the chatlog and add the link to it in your repository.
Why, though?
We’ve been finding from the
 GENIAL research that AI chatbots can sometimes ‘hijack’ our learning process without us ever realising it. There is a risk that we miss out on key learning goals in an attempt to be more productive.
GENIAL research that AI chatbots can sometimes ‘hijack’ our learning process without us ever realising it. There is a risk that we miss out on key learning goals in an attempt to be more productive.AI chatbots often suggest code solutions that work but are overly complex, odd, or against our ‘coding philosophy’. While this is not necessarily an issue, there are many ways to achieve the same thing in Python, it’s likely that you will struggle a lot in the future as complexity increases.
👉 If we suspect this happened to you, more than simply describing what you did wrong, we can point to where the AI chatbot might have led you astray so you can improve for next time.
⬆️ Submission:
You don’t need to submit anything on Moodle. We will mark your latest version of what is in your GitHub repository.
Simply
git pushyour changes to your allocated GitHub repository before the due date.Read the Extensions to know what to do if you need an extension.
✔️ How we will grade your work
I don’t enjoy this but, unfortunately, I must be strict when grading summative assignments to mitigate fears over grade inflation. Higher marks are reserved for those who demonstrate exceptional talent or effort, but in a way that aligns with the learning objectives and coding philosophy of this course. (Simply adding more analysis or complicating the code is not sufficient!) The good news is that, if you have been attentive to the teaching materials and actively engaged with the exercises and asked clarifying questions whenever you got stuck, it should still be feasible to achieve a ‘Good!’ level (70 marks).
Even though we will have to be stricter with the grading, we still want to see you succeed! It should still be possible to achieve a 70/100 mark if you have been attentive to the teaching materials and actively engaged with the exercises and asked clarifying questions whenever you got stuck. Aim for a ‘Good!’ level, and don’t stress too much about the ‘WOW!’ level. Only improve your project if you have time and energy to do so.
🧐 Originality (0-15 marks)
Your entire project will be assessed for originality. This includes the questions you pose to the data, the selection of endpoints (or additional data sources), the way you curated the dataset for analysis, and the visualisations you created to answer your questions.
| Marks Awarded | Level | Description |
|---|---|---|
| < 7 | Poor | Either the questions you posed to your data are very simple and lack creativity or originality, they may repeat examples that are easy to find online, or the selected endpoints do not effectively answer the questions. |
| 7-10 | Good! | You have created a good set of questions for the Spotify API, and the chosen endpoints are suitable. The project just cannot score higher because your ideas may be similar to those of others in the course or are topics commonly explored with the Spotify API, which one can easily find online. |
| 11-14 | Very Good | The questions you asked are original, and we could not have predicted them. They may be a bit more complex and require combining extra sources or more creativity. If you use additional data sources, they support and do not overshadow the data from the Spotify API. |
| 15 | 🏆 WOW! | Your questions took us by surprise! They are very creative and show a great understanding of the Spotify API data. You might have explored a unique area of the API or combined data from multiple endpoints in a new and insightful way. |
💽 Data Collection (0-25 marks)
We will focus on the NB01 - Data Collection.ipynb notebook to evaluate your data collection process.
| Marks Awarded | Level | Description |
|---|---|---|
| <12 | Poor | The code has major errors or does not run. The API key may be exposed on GitHub, or the data collection process is poorly documented. |
| 12-18 | Good! | In line with the coding philosophy of the course, the code uses custom functions when applicable, the requests are well-structured and done in a smart way (no unnecessary/repeated requests), loops are used if needed, and the data is saved in the correct format (raw JSONs). In addition, the API key was not exposed on GitHub, and the README clearly explains how to replicate the Python environment and set up API credentials. The code is organized and easy to read. |
| 19-23 | Very Good | In addition to the “Good!” criteria, you have included several additional endpoints or new data sources that are relevant to your questions. The code is well-documented and easy to follow. |
| 25 | 🏆 WOW! | This resembles a final project, showcasing a wealth of data that can lead to significant findings in other notebooks. |
🔩 Data Manipulation (0-25 marks)
We will focus on the NB02 - Data Processing.ipynb notebook to evaluate your data manipulation process.
| Marks Awarded | Level | Description |
|---|---|---|
| < 12 | Poor | The code fails to read the raw JSON data correctly or exhibits significant errors in pandas operations. The SQLite database might be missing or implemented incorrectly, with inappropriate keys or data types. Over-reliance on lists, dictionaries, and for loops without justification. |
| 12-18 | Good! | The code reads and parses raw JSON data effectively using pandas. Data manipulation includes appropriate merging, cleaning, and transformation steps. A well-structured SQLite database is created, with correct keys and data types. The tables and columns of the database clearly make sense for the questions of the project. The database schema is well-designed and efficient, avoiding unnecessary data duplication. The data types are as economical as possible. ‘Pure python’ objects (lists, dictionaries, and for loops) are avoided unless absolutely necessary and justified. |
| 19-23 | Very Good | Beyond the “Good!” criteria, we were surprised to see advanced use of SQL queries, pandas functions, or data manipulation techniques that go beyond the scope of the course. |
| 25 | 🏆 WOW! | The student showcases advanced data manipulation techniques beyond the scope of the course. Are you a professional Data Engineer or Database Administrator (DBA)? |
📊 Data Visualisation and Interpretation (0-35 marks)
We will focus on the NB03 - Data Visualisation.ipynb notebook to evaluate your data visualisation and interpretation process. This is where you will be able to show off your creativity and storytelling skills.
| Marks Awarded | Level | Description |
|---|---|---|
| < 20 | Poor | Visualisations are poorly chosen, or irrelevant to the question. Titles are missing or do not convey insights. Interpretations are superficial, generic, or inaccurate. The code might read data from sources other than the SQLite database or lack the groupby->apply->combine strategy when applicable. |
| ~25 | Good! | Visualisations are appropriate for the questions posed and effectively convey key insights. Titles clearly summarise the main takeaway from each plot. Interpretations are well-reasoned and are not overly verbose or too generic. The code reads data directly from the SQLite database and employs the groupby->apply->combine strategy for data aggregation where appropriate. Colour schemes were well-chosen with colourblindness in mind. |
| ~30 | Very Good | Visualisations are well-designed and insightful. Titles are concise yet informative, highlighting key trends and patterns. Interpretations are thorough and demonstrate a deep understanding of the data. The code showcases efficient data handling and consistent use of the groupby->apply->combine strategy for complex visualisations. It’s the kind of data visualisation you would find on a professional data journalism website. |
| 35 | 🏆 WOW! | You should be hired by the pudding.cool or The Markup people! |
Footnotes
Similar to how we have been practising since the beginning of the course.↩︎
This topic is covered in the Week 08 Lecture↩︎
I don’t think you can share logs of tools like Google’s NotebookLM, but if you want, you can add a screenshot or describe the interactions somewhere if you think it will help us understand your thought process better.↩︎