
📝 W06 Summative
2023/24 Winter Term
⏲️ Due Date:
- 21 February 2024 at 5 pm UK time
If you submit after this date without an authorised extension, you will receive a late submission penalty.
Did you have an extenuating circumstance and need an extension? Send an e-mail to 📧
🎯 Main Objectives:
- Practice some more Git/GitHub
- Practice web scraping in Python
⚖️ Assignment Weight:
30%
This assignment is worth 30% of your final grade.
📚 Preparation
Read carefully. Some details are different from the previous assignments.
Find the GitHub assignment link: Go to our Slack workspace’s
#announcementschannel. We don’t share the link publicly. It is a private repository for enrolled students only.Accept the assignment: Click the link, sign in to GitHub, and click the green button.
Access your private repository: You’ll be redirected to a new private repository named
ds105w-2024-w06-summative-<yourusername>.Clone your repository: Clone your repository to your computer. A folder
ds105w-2024-w06-summative-<yourusername>will appear on your computer. We will refer to this folder as<github-repo-folder>in the rest of this document.Install the required packages:
pip install numpy pandas requests scrapyMandatory requirement: keep your AI chat logs. If you used AI tools for assistance with this assignment, it’s essential to retain a log of your chat interactions. We will collect your chat logs just before releasing your grades (after grading and de-anonymising your assignment).
For
 GENIAL participants: Submit your logs via the standard weekly forms. We’ll take it from there.
GENIAL participants: Submit your logs via the standard weekly forms. We’ll take it from there.If you have chosen not to participate in the study, we’ll contact you via e-mail when the time comes to submit your logs.
Please Note: There will be no penalties for using or abstaining from using AI tools.
7. Learn how to get help:
- Pose questions in the public channels on Slack.
- Attend the drop-in sessions facilitated by our colleagues at the Digital Skills Lab.
- Refer to the 🙋 Getting Help section below for guidance on collaborating with peers without compromising the originality of your work.
📋 Tasks
The questions below primarily build on principles taught at the 👨🏻🏫 W04 Lecture & 👨🏻🏫 W05 Lecture as well as the 💻 W05 Lab.
What do we actually want from you?
📝 Task 0: Setup
Open
<github-repo-folder>/notebooks/NB01 - Data Collection.ipynband add your candidate number to the first markdown cell.Inside the # ⚙️ SETUP section, replace
<your candidate number>with your actual candidate number.Run the code cell inside the Discover your unique assignment section to discover the web page you will be scraping.
Push it to GitHub
git addgit commit -m "Setting up my assignment"git push
📝 Task 2: Collecting boxes (50 marks)
Not all, but most LSE department webpages have a few ‘content boxes’, typically with some text and a figure. For example, see below a highlighted content box from the LSE Data Science Institute research webpage:
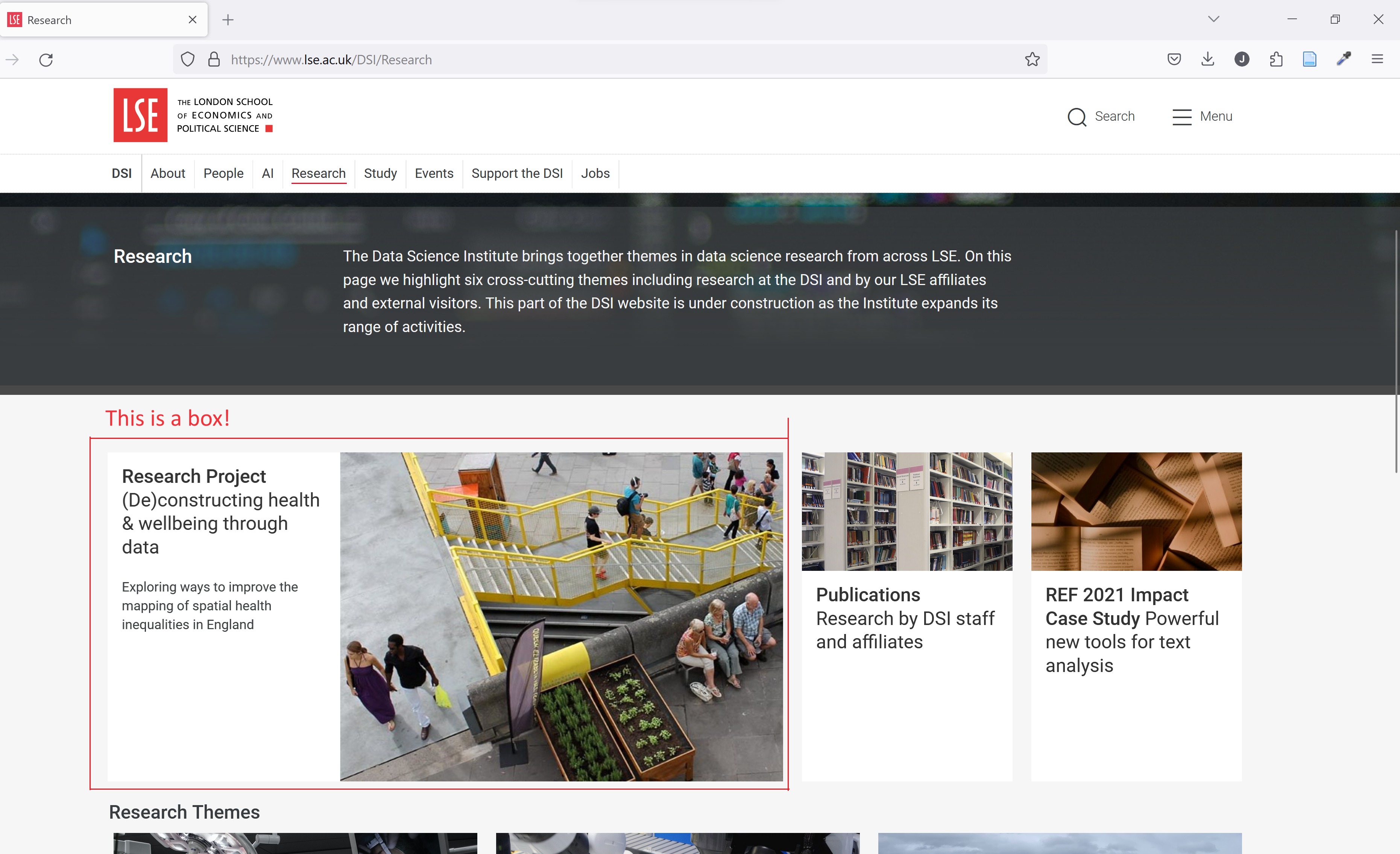
Let’s organise the content of these boxes into a dataframe.
Add a new section on
NB01 - Data Collection.ipynb, add a H1 header and call it Task 2 - Scraping the Schedule.Read the
menu.jsonfile you created in Task 1 as a dictionary.
(Sure, in real life, this is unnecessary, given that you already have the dictionary in your memory. But we want to see your file reading skills!)
Scrape all content boxes from each link in your
menudictionary. Extract the title, subtitle, text, image URL, and alt title from each box using Python data structures.For example, a dictionary representation of the content box highlighted above would be:
{ "title": "Research Project", "subtitle": "(De)constructing health & wellbeing through data" "text": "Exploring ways to improve the mapping of spatial health inequalities in England", "image_url": "/Cities/Assets/Images/research-page-images/DSI-Deconstructing-health-and-wellbeing/DSI-photo-a-747x560.jpg", "image_alt": "DSI-photo-a-747x560" }Organise this data into a single dataframe called
df_boxeswith the following columns
| department | page_title | page_url | box_title | box_subtitle | box_text | box_image_url | box_image_alt |
|---|---|---|---|---|---|---|---|
| Data Science Institute | Research | https://www.lse.ac.uk/dsi/research | Research Project | (De)constructing health & wellbeing through data | Exploring ways to improve the mapping of spatial health inequalities in England | /Cities/Assets/Images/research-page-images/DSI-Deconstructing-health-and-wellbeing/DSI-photo-a-747x560.jpg | DSI-photo-a-747x560 |
| … | … | … | … | … | … | … | … |
| … | … | … | … | … | … | … | … |
👉 Note: The first column is the same for all rows. This is the department you were assigned to.
Leave cells empty whenever the information is not available.
Save the dataframe as a CSV file to
<github-repo-folder>/data/boxes.csv.Commit & push as frequently as you want.
📝 Task 3: Collecting the images (30 marks)
Now, let’s download the images from the boxes you scraped in Task 2.
Add a new section on
NB01 - Data Collection.ipynb, add a H1 header and call it Task 3 - Downloading Images.Read the menu dictionary from the
menu.jsonfile and thedf_boxes.csvfiles again.Use the Python
oslibrary to create a folder called<github-repo-folder>/data/imagesto store the images.Still using the
oslibrary, add sub-folders for each menu page. For example, if you have a menu item called “Research”, you should create a sub-folder called<github-repo-folder>/data/images/research.Using the
requestslibrary, download the images from thebox_image_urlcolumn of thedf_boxesdataframe and save them to the appropriate sub-folder.Commit & push as frequently as you want.
Wrapping up
- Edit the README.md file to include a brief description of your work and the structure of your repository.
✔️ How we will grade your work
- We will run your notebook and check if it produces the expected JSON, CSV, and image files and that they are in the right places.
- We will check if your notebook (markdown and code) is well-organised, efficient, and doesn’t throw any errors.
- In line with typical LSE expectations around course grades, you will score around 70% if you get everything right. More marks are only awarded for exceptional work beyond what we have taught you.
How to get help and how to collaborate with others
🙋 Getting help
You can post general coding questions on Slack but should not reveal code that is part of your solution.
For example, you can ask:
- “What is a good way to extract just the middle part of a string?”
- “How do I convert a string to a date?”
You are allowed to share ‘aesthetic’ elements of your code, if they are not part of the core of the solution. For example, suppose you find a really cool new way to write a for loop. You can share that on Slack.
If we find that you posted something on Slack that violates this principle without realising, you won’t be penalised for it - don’t worry, but we will delete your message and let you know.
👯 Collaborating with others
You are allowed to discuss the assignment with others, work alongside each other, and help each other. However, you are not allowed to share code or to copy code from others. Pretty much the same rules as above. Copying code from others is plagiarism and will be dealt with accordingly.
Aim to strike a balance: you want to be able to talk to others about programming in general without getting too specific about the assignment. This is a good way to ensure your submission has your personal touch (more likely to earn more marks) and avoid getting into trouble.
🤖 Using AI help?
You can use Generative AI tools such as ChatGPT when doing this research and search online for help. If you do use it, however minimal use you made, you are asked to report in the final section of your notebook, explaining which tools and the extent to which you used it and to keep the chat logs that show evidence of how you used it.
If you are a
GENIAL participant, things are easier for you. Just don’t forget to submit your logs via the standard weekly forms.If you don’t participate in the study, we’ll contact you via e-mail when the time comes to submit your logs.
To see examples of how to report the use of AI tools, see 🤖 Our Generative AI policy.