
📝 W07 Summative
2023/24 Autumn Term
⏲️ Due Date:
- 8 November 2023 at 12:00pm UK time
If you update your files on GitHub after this date without an authorised extension, you will receive a late submission penalty.
Did you have an extenuating circumstance and need an extension? Send an e-mail to 📧
🎯 Main Objectives:
Demonstrate your ability to
- Organise your code and data files in a GitHub repository.
- Write good markdown documentation.
- Scrape data from the web using Python.
- Use Python’s data structures (lists, dicts and sets) and functions well.
- Use
listordictcomprehensions.
⚖️ Assignment Weight:
This assignment is worth 30% of your final grade and is the last individual assignment of the course.
30%
📝 Instructions
Read carefully, as some details are new.
Go to our Slack workspace’s
#announcementschannel to find a GitHub Classroom link entitled 📝 W07 Summative. Do not share this link with anyone outside this course!Click on the link, sign in to GitHub and then click on the green button
Accept this assignment.You will be redirected to a new private repository created just for you. The repository will be named
ds105a-2023-w07-summative-yourusername, whereyourusernameis your GitHub username.- The repository will be private and contain simply a
.gitignorefile.
- The repository will be private and contain simply a
This is not an anonymous submission! In fact, this submission requires identifying yourself to Wikipedia. This is to adhere to Wikipedia’s own suggested best practices for bots and automated tools.
Autonomy is an essential aspect of this submission. You decide how to organise your Python code and data files in your repository. For example, you can create one or multiple
.ipynbfiles, or you might want to use pure.pyscripts.Creativity and originality will also play a role. Your task involves coming up with a topic to explore by yourself.
The only file requirement is that your repository must have a
README.mdfile with a brief description of your project and instructions on running your code (which packages to install, in what order to run your scripts/notebooks, etc.)- Tip: You won’t need to write instructions on installing the packages you used if you add a
requirements.txtfile to your GitHub repo.
- Tip: You won’t need to write instructions on installing the packages you used if you add a
Push your work to your GitHub repository as often as possible before the deadline. We will only grade the last version of your assignment. Having trouble using Git on your computer? You can always add the files via the GitHub web interface.
Read the section How to get help and collaborate with others at the end of this document.
“What do I submit?”
We expect to see the following in your repository:
- a README.md file at the root of your repository
- Python code files (
.py) or Jupyter notebooks (.ipynb) that you used to scrape the data - Python code files (
.py) or Jupyter notebooks (.ipynb) that you used to analyse the data - Data files (
.csv,.json, etc.) containing the data you scraped
You don’t need to click to submit anything. Your assignment will be automatically submitted when you commit AND push your changes to GitHub. You can push your changes as many times as you want before the deadline. We will only grade the last version of your assignment. Having trouble using Git on your computer? You can always add the files via the GitHub web interface.
🗄️ The data
This problem set revolves around querying data from Wikimedia projects.
![]()
The Wikimedia Foundation is a non-profit organisation whose mission is to bring free educational content to the world. Wikimedia hosts and operates several projects, perhaps the most well-known being Wikipedia.
Click on the links below to read about the different projects:
As part of your assignment, you must pull data from at least one Wikimedia project. If you don’t have enough time to browse the links above, I suggest you use Wikipedia as your primary resource.
Whatever Wikimedia project you use, you must use only their English version.
Searching
Each one of the Wikimedia projects allows you to perform an advanced search for pages containing specific keywords, categories, etc.:
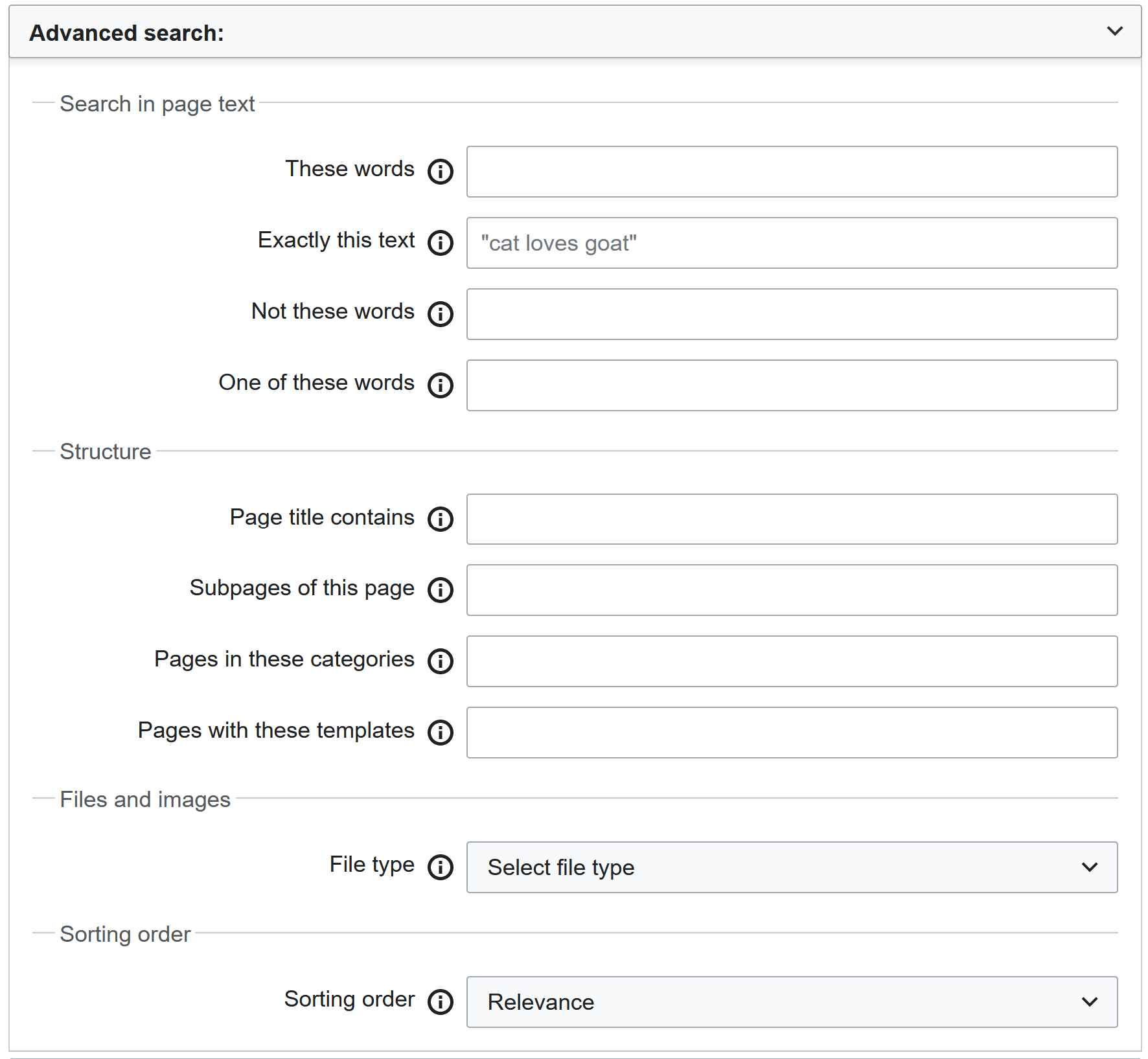
💡 TIP: Recall what you learned about URL and query string parameters in 💻 Week 05 lab.
📋 Your Tasks
What do we actually want from you?
Part I: choosing something you want to explore (20 marks)
Choose a theme, topic or series of events to explore. It can be anything you want, as long as you can find data about it on a Wikimedia project.
Requirement: Your search must return at least 1000 results on your main chosen Wikimedia project. This lower bound does not apply to other Wikimedia projects if you use more than one.
Requirement: You must use only the English version of the Wikimedia project you choose.
Think about something exciting and insightful you want to collect from each page later.
For example, say I chose to explore “London Borough Council election” pages. I noticed that each page, or most of them, has a ‘Results’ header with a paragraph indicating the number of seats won by each party. This is interesting information I could collect from each page and put on a data frame.
Obtain the precise URL that produces the search results you want to explore. For example, this URL returns all Wikipedia articles with “London” in their title.
Write the
scrapycode to scrape all 1000+ links obtained by your search.Requirement: You should set the
User-Agentheader to something that identifies you, just like you did in 💻 Week 05 lab.Requirement: You cannot change the URL manually to get the following results page. You must paginate through the results.
Requirement: You should not use BeautifulSoup, as this was not covered in the course. You should use
scrapyinstead.
Part II: analysing the data (80 marks)
Write Python code with
scrapyto collect something interesting from each page returned by your search.What constitutes something interesting? Anything that is not too trivial (e.g. the page title) and that, when collected as an aggregate, can produce exciting summary tables or visualisations. Think of the example I gave above: the number of seats won by each party in London Borough Council elections is interesting because it can be used to produce a table or a bar chart showing the evolution of the political landscape in London’s geographic areas over time.
If you already know who your group members are, there are ways to collaborate safely on this assignment without incurring academic misconduct. See the section How to get help and collaborate with others at the end of this document.
Summarise the results you collected from all these pages into a single pandas data frame.
You are allowed to include None values in your data frame. For example, if not all of your pages have the same information, you can include None values in your data frame. Likewise, your resulting data frame might have different numbers of rows for each scraped page.
Adjust the data types of each column in your data frame to the most appropriate type, as we did in 🧑🏫 Week 04 lecture.
Write two interesting findings from the data frame you collected.
For example: ‘Labour won X% more seats than the Conservatives since 1990 according to this data’ or ‘Wikibooks about Y have on average X pages more than books about Z’.
You can use further loops, list comprehensions, etc., to produce these findings. Or, if you are feeling adventurous, you can use pandas’ groupby method to make them (we will only cover pandas summaries from 🧑🏫 Week 07 lecture), or visualisations.
Ensure you use Python’s data structures (lists, dicts and sets) and custom functions well.
Ensure you use Python’s list or dict comprehensions as much as possible.
✔️ How we will grade your work
Here, we start to get more strict. Following all the instructions, you should expect a score of around 70/100. Only if you go above and beyond what is asked of you in a meaningful way will you get a higher score. Simply adding more code or text will not get you a higher score; you need to add insightful new analysis or meaningful code to get a distinction.
Part 1: choosing something you want to explore (20 marks)
Here is a rough rubric for this part:
- <5 marks: A deep fail. Your repository is empty, contains minimal code or data, or does not follow the instructions (such as not having a README file).
- 5-10 marks: A pass. You identified a topic and showed a base URL but failed to do something important, such as setting the
User-Agentheader, paginating through the results, or adding details to your README. - ~15 marks: Good! You did everything correctly and as instructed. Your submission just fell short of perfect. Your code or markdown could be more organised, or your answers were not concise enough (unnecessary, overly long text).
- 20 marks: Impressive! Your topic is worthy of a data journalism article, your README is well-written, and your code is well-organised.
Part 2: analysing the data (80 marks)
Here is a rough rubric for this part:
- <20 marks: A deep fail. Your repository is empty, contains minimal code or data, or does not follow the instructions (such as not having a README file).
- 20-40 marks: A pass. You collected data from the pages returned by your search but failed to do something important, such as collecting something interesting from each page or summarising the results into a data frame. Or it could mean that your README is not well-written or your code is not reproducible in an organised way.
- 40-50 marks: Good! However, your code might not have used Python’s data structures and functions well, it is hard to follow your thought process, there is not enough documentation, or the text in markdown is not concise enough (unnecessary, overly long text). This is where most submissions will fall.
- ~60 marks: Very Good! You did everything correctly and as instructed. Your submission just fell short of perfect. Your code or markdown could be more organised, or your answers were not concise enough (unnecessary, overly long text). This is a good score!
- >60 marks: Impressive! Not long was everything done correctly, you combined more than one Wikimedia project and managed to put them together in a single data frame!
- ~80 marks: You are a semi-god! We would never have expected this level of creativity, originality and technical expertise. You used multiple Wikimedia projects, used pandas extensively, created a database, and merged and pivoted data. Your README is a work of art; your code has docstrings everywhere, and oh…am I seeing this correctly? You automated the entire process of your analysis as a Python package to perform this type of analysis and published it on PyPI? Wow!
How to get help and how to collaborate with others
🙋 Getting help
As usual, you can post general coding questions on Slack, but you should not reveal code that is part of your solution.
For example, you can ask:
- “How can I use another of my functions from within a function?”
- “Is anyone else collecting table data from each page? Any tips?”
- “Does anyone have any tips on selecting search terms that adhere to the criteria?”
You can share your code’s aesthetic elements if they are not part of the solution’s core. For example, you can share tips on Python visualisations or making your code more readable.
If you posted something on Slack that violates this principle without realising it, you won’t be penalised for it - don’t worry, but we will delete your message and let you know.
👯 Collaborating with others
- You can brainstorm ideas with course colleagues, and, given the creative nature of this assignment, you could even choose to do complementary analysis to the future peers of your group project. However, you cannot use the equivalent search terms as them.
- For example, one of you might want to search for election data in the UK, while the other might want to keep the political theme and search for election data in the US.
- It is okay to ask on Slack,‘does this sound interesting?’ Other colleagues can chip in and make suggestions, and we can also tell you if your idea is suitable for this assignment or too trivial. Just don’t ask us a day before the deadline!
Aim to strike a balance: you want to be able to talk to others about programming in general without getting too specific about the assignment. This is a good way to ensure your submission has your personal touch (more likely to earn more marks) and avoid getting into trouble.
🤖 Using AI help?
When writing your assignment, you are allowed to use Generative AI tools such as ChatGPT or GitHub Copilot. If you use it, however minimal use you made, you are asked to report the AI tool you used and add an extra section to your notebook to explain the extent to which you used it.
Note that while these tools can be helpful, they tend to generate responses that sound convincing but are not necessarily correct. Be mindful of how you use them. If you don’t understand what you get from the AI tool, you might end up with a convoluted and complicated code that will be hard to read.
To see examples of how to report the use of AI tools, see 🤖 Our Generative AI policy.