💻 Lab 06 – Web Scraping Practice II
Week 02 – Day 02 - Lab Roadmap (90 min)
🗒️ The Brief
We will give you a new challenge to help you practice your web scraping skills. This time, feel free to choose between CSS or XPath selectors to extract the data you need. Try to write human-readable code and to convert your data to a pandas data frame as soon as possible.
⚙️ Setup
Install the required packages for today’s session:
pip install requests scrapy tqdmCreate a new Jupyter Notebook for this lab. Give it a meaningful name, such as
LSE_ME204_W02D02_lab.ipynb.Create a new Python cell and add the imports below:
import requests # for sending HTTP requests from tqdm.notebook import tqdm, trange # for progress bars from scrapy import Selector # for parsing HTML content
📋 Lab Tasks
Wikipedia is free to use and edit, but it has its own set of rules and guidelines. One of the most interesting pages on Wikipedia is the List of controversial issues. This page lists topics that are controversial – that is, pages that have been edited in a circular manner, with editors disagreeing on the content.
Our goal today is to treat this list as a dataset and get an understanding of the attributes that most commonly appear in controversial topics. We will use web scraping to extract the data from this page.
Part 1: Look at Controversial Issues on Wikipedia (20 minutes)
🎯 ACTION POINTS
Visit the Wikipedia page on List of controversial issues.
Click on a controversial topic, any topic, and once there, click on the “Talk” tab. This tab shows what editors have been discussing about the topic. See screenshot below.
⚠️ WARNING: If a particular issue evokes strong emotions in you, please avoid reading it. We want to investigate what type of content tends to be tagged as controversial on Wikipedia, not necessarily to debate the issues themselves.
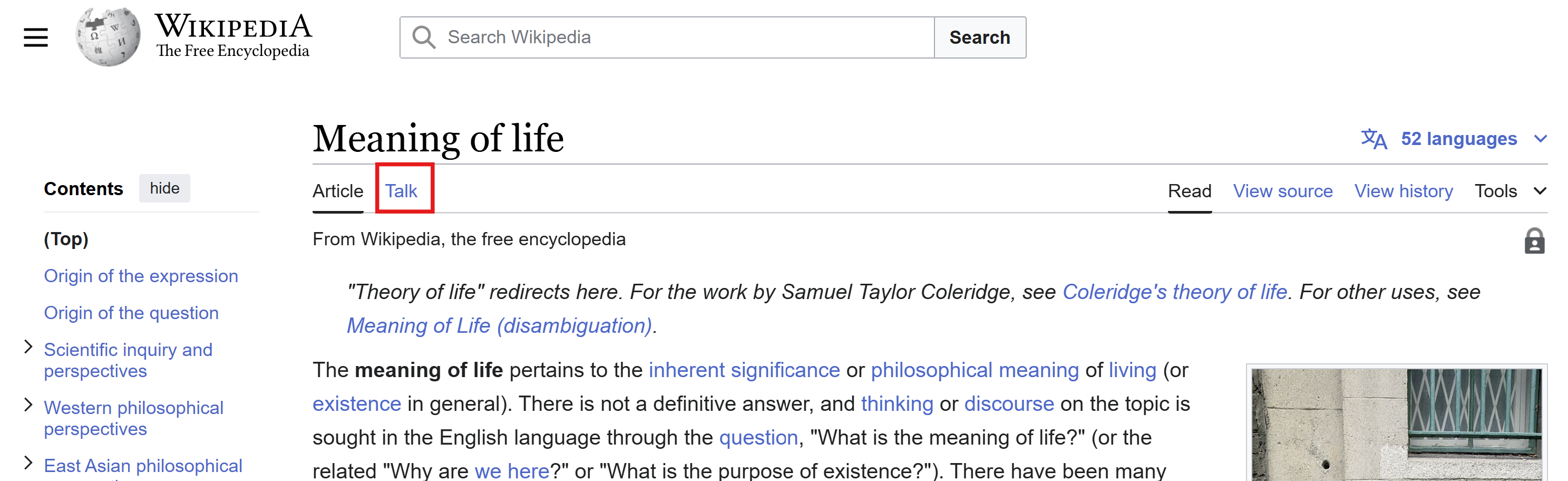
Where to find the “Talk” tab Spend some time reading the info on the page, just to get used to its structure.
I want to draw your attention to this particular box on the page, that contains a ‘content assessment’ of the article.

This box contains the ‘categories’ that our given page belongs to.
Part 2: Articulate your Thought Process out load (30 minutes)
🗣️ CLASSROOM DISCUSSION
Your class teacher will guide a class-wide conversation about the thought process required to produce the following output:
Think about – don’t write code yet – what you would have to do to extract the content of this box and convert it into a pandas data frame.
Ideally, we would want to create the following markdown table that summarises the major topics of the page:
Click here to view the table
| name | url | content_assessment_class | categories | categories_url |
|---|---|---|---|---|
| Meaning of Life | https://en.wikipedia.org/wiki/Meaning_of_life | C-class | ["Spirituality", "Philosophy", "Philosophy : Metaphysics", "Philosophy : Ethics", "Christianity", "Christianity : Catholicism", "Christianity : Anglicanism", "Christianity : Reformed Christianity", "Christianity : Latter Day Saints"] | ["https://en.wikipedia.org/wiki/Category:Spirituality", "https://en.wikipedia.org/wiki/Category:Philosophy", "https://en.wikipedia.org/wiki/Wikipedia:WikiProject_Philosophy/Metaphysics", "https://en.wikipedia.org/wiki/Wikipedia:WikiProject_Philosophy/Ethics", "https://en.wikipedia.org/wiki/Wikipedia:WikiProject_Christianity", "https://en.wikipedia.org/wiki/Wikipedia:WikiProject_Catholicism", "https://en.wikipedia.org/wiki/Wikipedia:WikiProject_Anglicanism", "https://en.wikipedia.org/wiki/Wikipedia:WikiProject_Reformed_Christianity", "https://en.wikipedia.org/wiki/Wikipedia:WikiProject_Latter_Day_Saint_movement"] |
- Better yet, what if you bundled all the information about
categoriesinto a single dictionary, as shown below?
Click here to view the table
| name | url | content_assessment_class | categories |
|---|---|---|---|
| Meaning of Life | https://en.wikipedia.org/wiki/Meaning_of_life | C-class | {"Spirituality": "https://en.wikipedia.org/wiki/Category:Spirituality", "Philosophy": "https://en.wikipedia.org/wiki/Category:Philosophy", "Philosophy : Metaphysics": "https://en.wikipedia.org/wiki/Wikipedia:WikiProject_Philosophy/Metaphysics", "Philosophy : Ethics": "https://en.wikipedia.org/wiki/Wikipedia:WikiProject_Philosophy/Ethics", "Christianity": "https://en.wikipedia.org/wiki/Wikipedia:WikiProject_Christianity", "Christianity : Catholicism": "https://en.wikipedia.org/wiki/Wikipedia:WikiProject_Catholicism", "Christianity : Anglicanism": "https://en.wikipedia.org/wiki/Wikipedia:WikiProject_Anglicanism", "Christianity : Reformed Christianity": "https://en.wikipedia.org/wiki/Wikipedia:WikiProject_Reformed_Christianity", "Christianity : Latter Day Saints": "https://en.wikipedia.org/wiki/Wikipedia:WikiProject_Latter_Day_Saint_movement"} |
Can you see why the above would be better? This way, we could use some fancy pandas functions (such as explode or json_normalize) later to flatten the dictionary into columns of the data frame.
Which other information from the “Talk” page would you like to extract? How would you add it to the data frame above?
Your class teacher will collect your initial ideas and write them down in the whiteboard/online whiteboard.
- How would you extract the content of the box?
- How would you create just a single line to represent information about the entire Talk page?
- How would you put together all controversial topics in a single data frame?
💡 TIP: Add Markdown cells to your Jupyter Notebook with the step-by-step procedure you would follow, from web scraping to single Data Frame.
Part 3: Write the Code (40 minutes)
Use the rest of the time to write the code that will extract the data from the Wikipedia page and convert it into a pandas data frame!
Remember to save your Jupyter Notebook and bring it to the morning session tomorrow. We will discuss the results and the challenges you faced during the lab.