🗓️ Week 02 – Day 03: JSON & APIs
Another way to get data from the web.
🥅 Learning Objectives
Review the goals for today
At the end of the day, you should be able to:
- Recognise the JSON file format and how it resembles Python dictionaries
- Navigate the JSON file structure
- Write code to collect data from APIs
- Navigate API documentation
Part I: ⏪ Review & Solutions: Wikipedia scraping
We will spend the first part of the morning session reviewing the web scraping code you wrote over the past few days.
We intentionally did not give out all the solutions to the exercises so that you could practice your problem-solving skills, but we will now go over the solutions together.
📋 NOTE: To reward students who are attending lectures, I will not post solutions to the website!
What we will review:
- Live demo of solutions to 💻 Week 02 Day 01 Lab
- Discussion of your solutions to 💻 Week 02 Day 02 Lab
- I will leave GitHub Copilot on while editing your code so we can learn from it (and learn when to ignore it)
💡 TIP: Learn about the robots.txt file to understand which pages site managers allow you to scrape from their websites.
Part II: 📚 Preparation for collecting data from Reddit API
We will now learn of a different way to collect data from the web: APIs. We will do so by collecting data from Reddit, a popular social media platform.
While the bulk of the work will be done in the lab, we will use the morning session to prepare for it.
🎯 ACTION POINTS:
Create a Reddit account
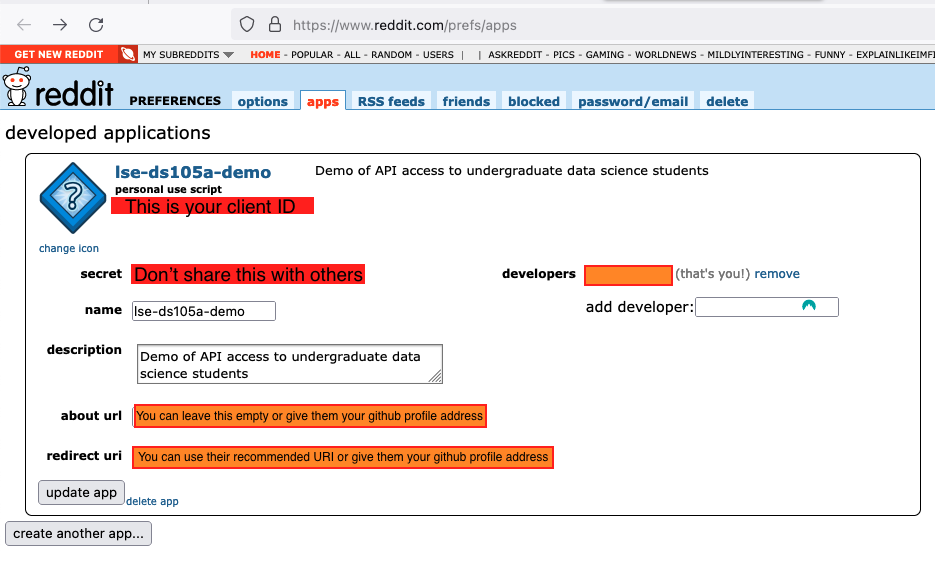
Then, follow these First Steps to create an app and get your credentials.
Take note of your Reddit username and password, as well as the client ID and client secret of the app you created:
Use ME204 instead of DS105A! (Optional) Install the JSON Crack Extension for VS Code
If there’s enough time, head to the 💻 Week 02 Day 03 Lab page to download the lab’s Jupyter Notebook.
🖇️ USEFUL LINKS:
- W3 Schools’ HTTP Request Methods page
- Reddit API’s documentation
- 🐼 pandas’
pd.json_normalize()function documentation