
💻 Lab 06 – Working with JSON data
Week 02 – Day 02 - Lab Roadmap (90 min)
📋 Lab Tasks
We worked with Wikipedia data last week on 💻 Week 01 – Day 04. Today we will work with the same data but in a different format. Instead of scraping the website, we will use Wikimedia’s API to download the data in JSON format.
Part 1: ⚙️ Setup (5 min)
Create a new script (
lab06.R) or, preferably, a new Quarto markdown document (lab06.qmd) to host your code and answers.Load the
tidyverse,jsonliteandhttr2packages.
library(tidyverse)
library(jsonlite)
library(httr2)Part 2: 🔐 Getting an API key (25 min)
🎯 ACTION POINTS
- Go to Getting started with Wikimedia APIs page and follow steps 1 to create a Wikimedia account.
- You will have to verify your e-mail address.
- Follow the link under Step 2 of the same webpage. You will be asked to create a new application. Fill it out as follows, replacing
<your-user-name>with your actual user name:
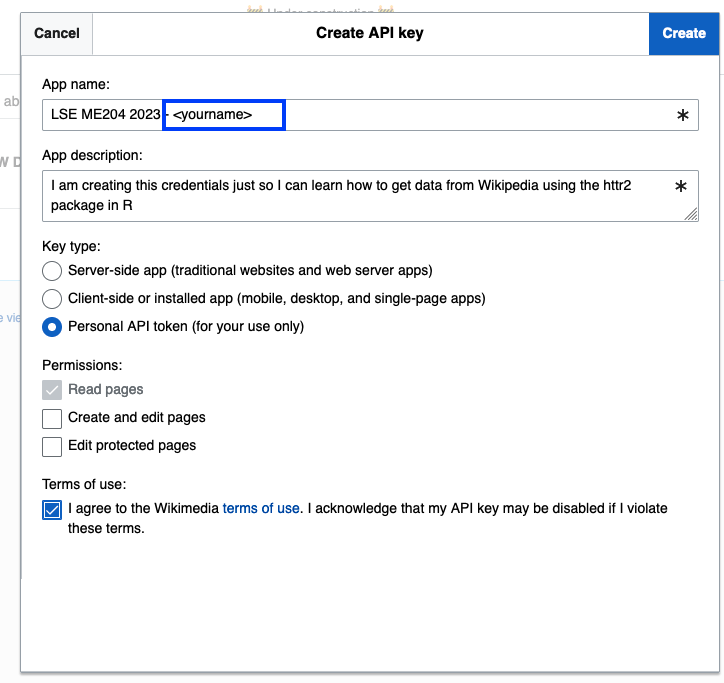
- You will be given a Client ID: and a Client secret and an Access token. Copy it all and save it to a text file safely on your computer. You will need it to access the API.
NEVER share your API keys with anyone.
NEVER upload your API keys to GitHub or any other public repository.
If you accidentally share it with someone, you will have to create a new set of keys and update your code accordingly.
Copy just the Access Token to a file called
my_secret_access_token.txt. If this file is not in the same folder as your R script, you will have to specify the path to it in your code.Test that you can access the API by running the following code:
# Read the access token from a file
access_token <- readr::read_file("my_secret_access_token.txt")
# Get API endpoint for yesterday's featured English Wikipedia article
url <- "https://api.wikimedia.org/feed/v1/wikipedia/en/featured/2023/07/17"
# Get the data
response <- request(url) %>% req_auth_bearer_token(access_token) %>% req_perform()
# Check the status of the request
response$status_codeThis should return a 200 status code, which means that the request was successful.
If you get a 401 status code, it means that your access token is not valid. You will have to create a new one and update your code accordingly.
- Test that you can get a JSON response from the API by running the following code:
response %>% resp_content_type()should return:
[1] "application/json"- Test that you can parse the JSON response by running the following code:
response %>% resp_body_json() %>% glimpse()(which will print out a lot of content on your R console).
Part 3: 🔖 Consulting Wikimedia’s API documentation (15 min)
👩🏻🏫 TEACHING MOMENT: Browse the links below with your class teacher.
![]()
The Wikimedia Foundation is a non-profit organization whose mission is to bring free educational content to the world. Wikimedia hosts and operates several projects, perhaps the most well-known being Wikipedia.
Click on the links below to read about the different projects:
API Access
Wikimedia provides a lot of APIs to access their open and public resources. You can find a list of all the APIs at the Wikimedia API catalog.
Part 4: What are today’s most read articles? (45 min)
In Part 1, we used the Featured content endpoint of the Feed API to retrieve the featured article for Monday, 17 July 2023. You can find detailed information about this endpoint on the documentation page.
🎯 ACTION POINTS
Take a close look at the documentation page and locate the section that mentions how the same endpoint can provide the most-read articles of the previous day.
Now, figure out how to write code to get a
listof the most-read articles of Sunday, 16 July 2023 (the previous day). Save this list to an object calledmost_read.If you did everything correctly, you should have a list of 46 articles. To check that, run:
length(most_read)You should also be able to peek at the structure of the first article in the list by running:
most_read %>% head(1) %>% glimpse()Click here to see the output
The code above would return:
List of 1 $ :List of 23 ..$ views : int 1898650 ..$ rank : int 2 ..$ view_history :List of 5 .. ..$ :List of 2 .. ..$ :List of 2 .. ..$ :List of 2 .. ..$ :List of 2 .. ..$ :List of 2 ..$ type : chr "standard" ..$ title : chr "Carlos_Alcaraz" ..$ displaytitle : chr "<span class=\"mw-page-title-main\">Carlos Alcaraz</span>" ..$ namespace :List of 2 .. ..$ id : int 0 .. ..$ text: chr "" ..$ wikibase_item : chr "Q85518537" ..$ titles :List of 3 .. ..$ canonical : chr "Carlos_Alcaraz" .. ..$ normalized: chr "Carlos Alcaraz" .. ..$ display : chr "<span class=\"mw-page-title-main\">Carlos Alcaraz</span>" ..$ pageid : int 63121147 ..$ thumbnail :List of 3 .. ..$ source: chr "https://upload.wikimedia.org/wikipedia/commons/thumb/b/b7/Alcaraz_MCM22_%2827%29_%2852036462443%29_%28edited%29"| __truncated__ .. ..$ width : int 320 .. ..$ height: int 480 ..$ originalimage :List of 3 .. ..$ source: chr "https://upload.wikimedia.org/wikipedia/commons/b/b7/Alcaraz_MCM22_%2827%29_%2852036462443%29_%28edited%29.jpg" .. ..$ width : int 1662 .. ..$ height: int 2492 ..$ lang : chr "en" ..$ dir : chr "ltr" ..$ revision : chr "1165816009" ..$ tid : chr "70260c10-24bb-11ee-9add-2bcc34c83094" ..$ timestamp : chr "2023-07-17T16:03:08Z" ..$ description : chr "Spanish tennis player (born 2003)" ..$ description_source: chr "local" ..$ content_urls :List of 2 .. ..$ desktop:List of 4 .. ..$ mobile :List of 4 ..$ extract : chr "Carlos Alcaraz Garfia is a Spanish professional tennis player. He is ranked as the world No. 1 in men's singles"| __truncated__ ..$ extract_html : chr "<p><b>Carlos Alcaraz Garfia</b> is a Spanish professional tennis player. He is ranked as the world No. 1 in men"| __truncated__ ..$ normalizedtitle : chr "Carlos Alcaraz"Now, create a tidy data frame containing all the articles in
most_read. The data frame should have the following columns:title: the title of the articledescription: the description of the articleviews: the number of views the article had on Sunday, 16 July 2023date: the date for which the articles were retrieved
Save this data frame to an object called
most_read_df.If you did everything correctly, you should have a data frame with 46 rows and 3 columns and the content will look like this:
most_read_df %>% head(5)title description views date Carlos_Alcaraz Spanish tennis player (born 2003) 1898650 2023-07-16 Novak_Djokovic Serbian tennis player (born 1987) 1228361 2023-07-16 Jane_Birkin British-French singer and actress (19472023) 717477 2023-07-16 Wimbledon_Championships Tennis tournament held in London 448186 2023-07-16 J._Robert_Oppenheimer American theoretical physicist (19041967) 328668 2023-07-16 (If time allows) If you manage to finish the step above, spend some time optimising and refactoring your code. For example, you could create a function
get_most_read_en_articles()that takes a lubridate date object and the access_token as arguments and returns the data frame with the most-read articles for that date.
🏡 Bonus Task
- Write the code to produce a data frame
df_all_dateswhich is a single data frame that contains ALL most-read articles since the start of 2023 until yesterday.
- reuse your
get_most_read_en_articles()function from Step 4 above - use
lapplyto loop over a sequence of dates - use
bind_rows()to combine the data frames into a single one - (extra tip) replace
lapplywithpblapplyfrom the pbapply package to get a progress bar while the code is running.