
✅ (Solutions) Lab 04
Solutions to the Lab 04 exercises.
(Ideally you would have solved this in a markdown file)
⚙️ Setup
The packages you’ll need:
library(tidyverse)
library(rvest)
Part 1: Navigating the DOM with rvest
Part 2: Extracting information from the featured article
Part 2: Extracting information from the featured article
Today’s featured article was a summary of the Wikipedia entry for the British Egyptologist Margaret Murray, as can be seen in the screenshot below:
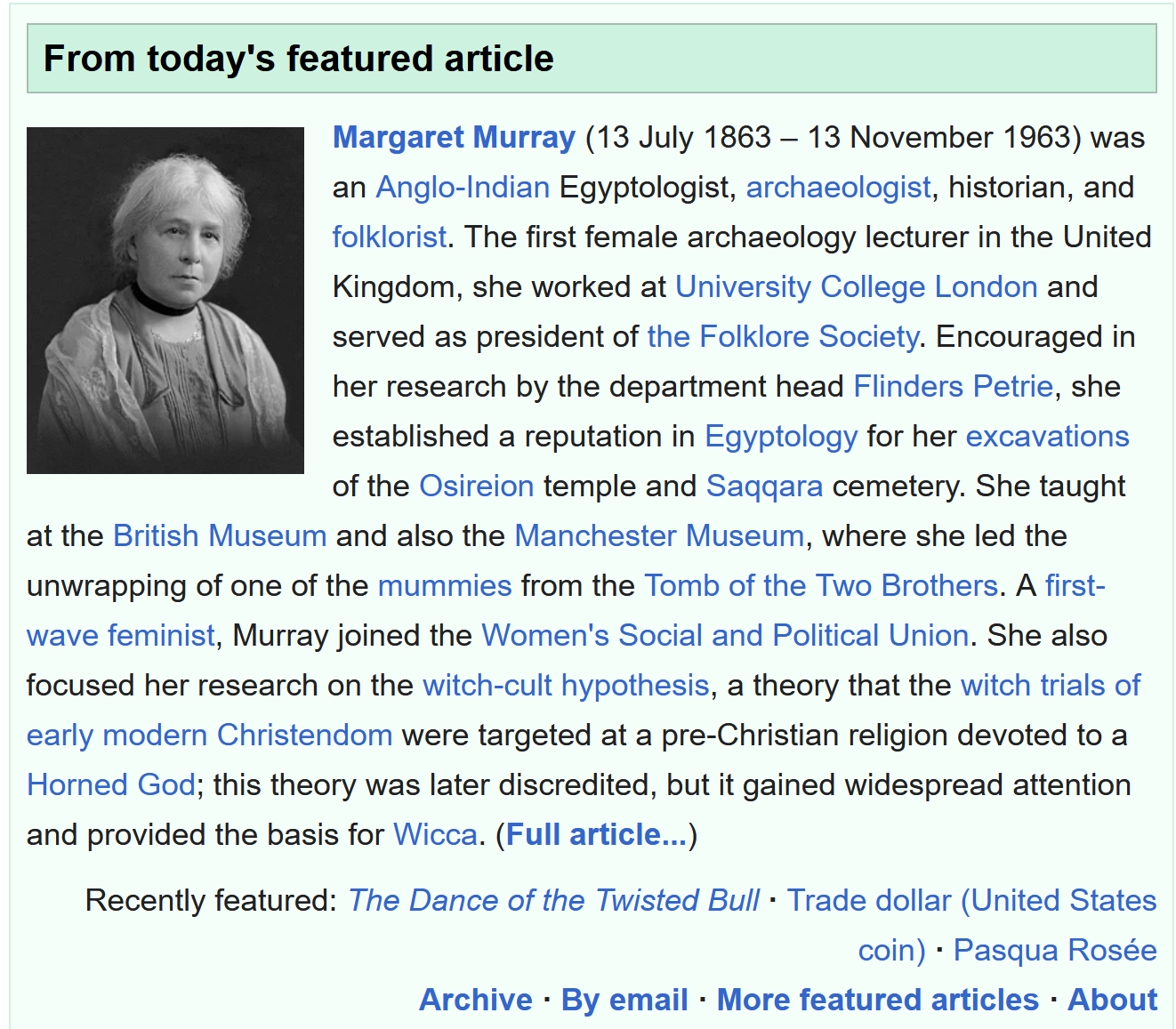
Step 1: is pretty straightforward.
featured_article <- wiki %>% html_element("#mp-tfa")producing:
featured_article{html_node}
<div id="mp-tfa" class="mp-contains-float">
[1] <div id="mp-tfa-img" style="float: left; margin: 0.5em 0.9em 0.4em 0em;">\n<div class="thumbinner mp-thumb" ...
[2] <p><b><a href="/wiki/Margaret_Murray" title="Margaret Murray">Margaret Murray</a></b> (13 July 1863 – 13 No ...
[3] <div class="tfa-recent" style="text-align: right;">\nRecently featured: <style data-mw-deduplicate="Templat ...
[4] <link rel="mw-deduplicated-inline-style" href="mw-data:TemplateStyles:r1129693374">\n
[5] <div class="hlist tfa-footer noprint" style="text-align:right;">\n<ul>\n<li><b><a href="/wiki/Wikipedia:Tod ...Step 2 Getting the text is easy, and we can pipe it to cat or print:
featured_article %>% html_element("p") %>% html_text() %>% print()But then you might be asking, why do I only see the first few lines of the article?
[1] "Margaret Murray (13 July 1863 – 13 November 1963) was an Anglo-Indian Egyptologist, archaeologist, historian,"Well, it’s just because R is preventing you from seeing the whole thing, as it is quite long. You can write the output text to a file and open it in a text editor to see the whole thing:
featured_article %>%
html_element("p") %>%
html_text() %>%
writeLines("featured_article.txt", useBytes = TRUE)Note that I used useBytes = TRUE to ensure that the text is written to the file in UTF-8 encoding.
Step 3: We make use of the html_elements() function.
featured_article_links <-
featured_article %>%
html_element("p") %>%
html_elements("a")which produces:
{xml_nodeset (22)}
[1] <a href="/wiki/Margaret_Murray" title="Margaret Murray">Margaret Murray</a>
[2] <a href="/wiki/Anglo-Indian_people" title="Anglo-Indian people">Anglo-Indian</a>
[3] <a href="/wiki/Archaeology" title="Archaeology">archaeologist</a>
[4] <a href="/wiki/Folklore_studies" title="Folklore studies">folklorist</a>
[5] <a href="/wiki/University_College_London" title="University College London">University College London</a>
[6] <a href="/wiki/The_Folklore_Society" title="The Folklore Society">the Folklore Society</a>
[7] <a href="/wiki/Flinders_Petrie" title="Flinders Petrie">Flinders Petrie</a>
[8] <a href="/wiki/Egyptology" title="Egyptology">Egyptology</a>
[9] <a href="/wiki/Archaeological_excavation" title="Archaeological excavation">excavations</a>
[10] <a href="/wiki/Osireion" title="Osireion">Osireion</a>
[11] <a href="/wiki/Saqqara" title="Saqqara">Saqqara</a>
[12] <a href="/wiki/British_Museum" title="British Museum">British Museum</a>
[13] <a href="/wiki/Manchester_Museum" title="Manchester Museum">Manchester Museum</a>
[14] <a href="/wiki/Mummy" title="Mummy">mummies</a>
[15] <a href="/wiki/Tomb_of_Two_Brothers" title="Tomb of Two Brothers">Tomb of the Two Brothers</a>
[16] <a href="/wiki/First-wave_feminism" title="First-wave feminism">first-wave feminist</a>
[17] <a href="/wiki/Women%27s_Social_and_Political_Union" title="Women's Social and Political Union">Women's So ...
[18] <a href="/wiki/Witch-cult_hypothesis" title="Witch-cult hypothesis">witch-cult hypothesis</a>
[19] <a href="/wiki/Witch_trials_in_the_early_modern_period" title="Witch trials in the early modern period">wi ...
[20] <a href="/wiki/Horned_God" title="Horned God">Horned God</a>
...Step 4: Create a data frame either with data.frame function or tibble function.
featured_article_df <-
tibble(href = html_attr(featured_article_links, "href"),
title = html_text(featured_article_links))
featured_article_dfproduces a data frame of the form:
| href | title |
|---|---|
| /wiki/Margaret_Murray | Margaret Murray |
| /wiki/Anglo-Indian_people | Anglo-Indian |
| /wiki/Archaeology | archaeologist |
| /wiki/Folklore_studies | folklorist |
| /wiki/University_College_London | University College London |
| /wiki/The_Folklore_Society | the Folklore Society |
| /wiki/Flinders_Petrie | Flinders Petrie |
| /wiki/Egyptology | Egyptology |
| /wiki/Archaeological_excavation | excavations |
| /wiki/Osireion | Osireion |
| /wiki/Saqqara | Saqqara |
| /wiki/British_Museum | British Museum |
| /wiki/Manchester_Museum | Manchester Museum |
| /wiki/Mummy | mummies |
| /wiki/Tomb_of_Two_Brothers | Tomb of the Two Brothers |
| /wiki/First-wave_feminism | first-wave feminist |
| /wiki/Women%27s_Social_and_Political_Union | Women’s Social and Political Union |
| /wiki/Witch-cult_hypothesis | witch-cult hypothesis |
| /wiki/Witch_trials_in_the_early_modern_period | witch trials of early modern Christendom |
| /wiki/Horned_God | Horned God |
| /wiki/Wicca | Wicca |
| /wiki/Margaret_Murray | Full article… |
Part 3: Website crawl
# Step 1: Take the first link from the `featured_article_df`
first_link <- featured_article_df$href[1]# Step 2: Use the `paste0()` function to create a full URL
first_link_url <- paste0("https://en.wikipedia.org", first_link)produces:
[1] "https://en.wikipedia.org/wiki/Margaret_Murray"# Step 3: Read the new page then use html_elements to get `<h2>` headers
first_link_html <- read_html(first_link_url)
h2_headers <- first_link_html %>%
html_elements("h2") %>%
html_text()
h2_headersto obtain the solution:
[1] "Contents" "Early life" "Later life"
[4] "Murray's witch-cult hypotheses" "Personal life" "Legacy"
[7] "Bibliography" "See also" "References"
[10] "External links"