
💻 Week 07 - Class Roadmap (90 min)
2025/26 Autumn Term
Machine Learning and AI in Medicine
Welcome to our week 07 seminar/lab class for DS101A.
This class continues with case studies – looking at the application of AI to medicine – and highlights issues that have arisen in the past due to problems in approach.
We will outline the main stages of the supervised learning approach, to understand what it aims to solve, and also how the application of these techniques to clinical practice can break down.
The papers used for class preparation presented some examples of the clinical reality of using AI for medicine. In this class we take a closer look at the machine learning modelling process, and we discuss what needs to be taken into consideration when exploring the techniques used.
We will discuss:
- Collecting data (20 minutes)
- Model training / selection (35 minutes)
- Model evaluation (30 minutes)
Step 00 - Machine learning pipeline (5m)
👨🏫 Teaching moment
Your tutor will take you through a basic machine learning pipeline.
Step 01 - Collecting data (above) (15m)
- What factors resulted in flaws in the data collection process for COVID-19 trackers?
- What negative externalities did these flaws have?
Step 02 - Model training / selection (30m)
- Classroom exercise
Thinking like an algorithm:
- how would you go about separating classes?
- How can we think about the inherent advantages and disadvantages of different ML models?
- What is training data? What factors result in good / bad training data? Was the data used to train the earlier COVID-19 trackers good training data?
🍵 Break (~5 min)
Step 03 - Model evaluation (25m)
- 👨🏫 Teaching moment
Now that we have built a model using training data, we can then test the quality of our predictions using our test set.
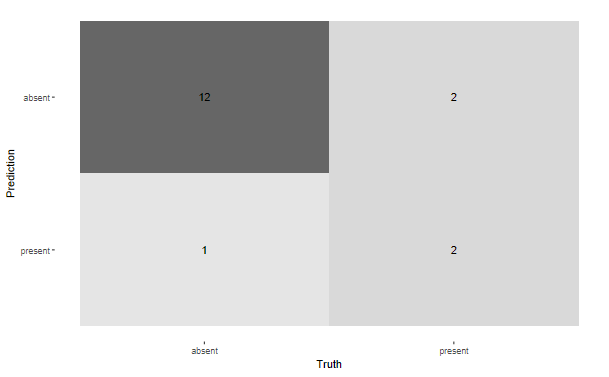
- How do we know if a model is fit for purpose? Your teacher will walk you through how a confusion matrix is constructed.
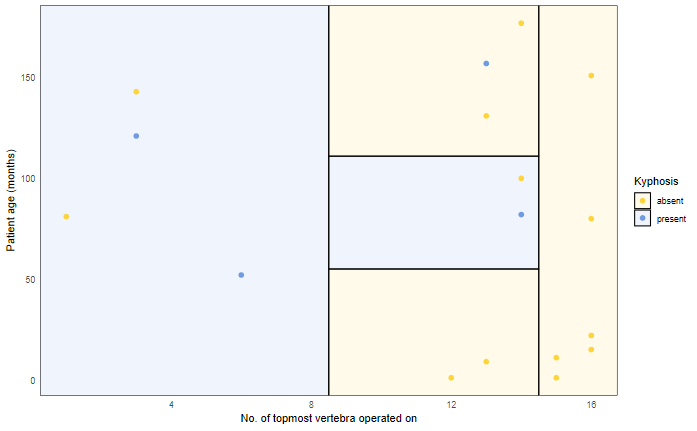
- What is testing data? Were many of the models deployed for tracking COVID-19 evaluated on testing data?
- What is overfitting? What are the externalities of overfitting?
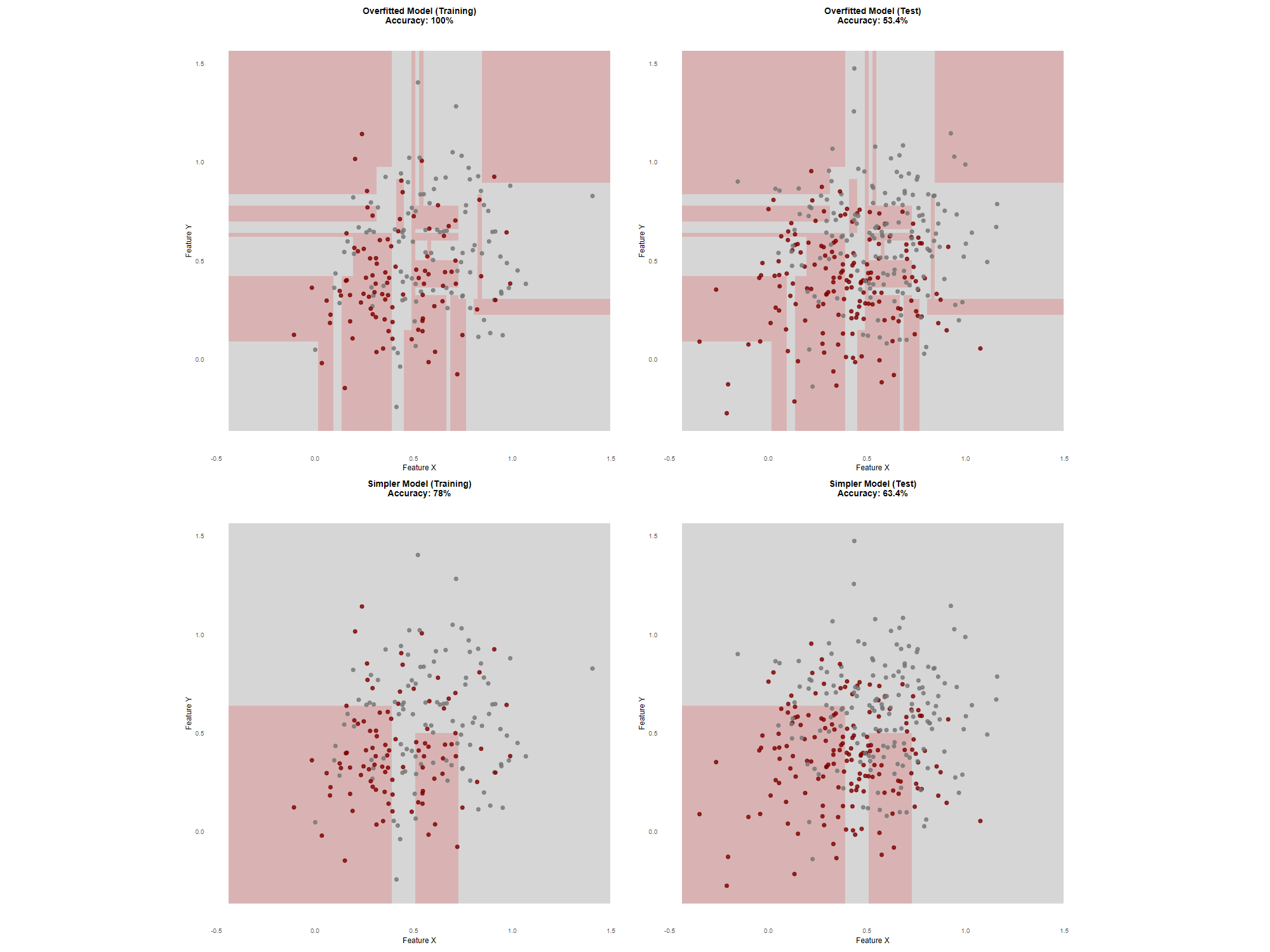
Step 04 - Another perspective on models (10m)
- Aside from the problems already discussed, do you see other sources of algorithmic problems in supervised learning algorithms applied to medicine (in particular COVID-19 trackers)? How can they be remedied?
- We talked about problems creeping in throughout the ML pipeline but what are the advantages of applying supervised learning to medicine when the right conditions align? And what are the “right conditions”?