
✅ Week 05 Lab - Solutions
How was your first web scraping ️ adventure?
More than solutions to the Week 05 lab exercises (found in 💻 Week 05 lab), I showcase a way of thinking that might help you write better code in the future.
Read along even if you managed to solve everything by yourself. You might still learn a few new tricks.
Part I
This was just set up + a reference list for HTML & CSS.
Part II: Time to put all of this into practice
Q1
Go to the Data Science Seminar series website and inspect the page (mouse right-click + Inspect) and find the way to the name of the first event on the page.
By following the procedure, you should conclude that the title is inside a <h6> tag, as highlighted by the red boxes in the image below:
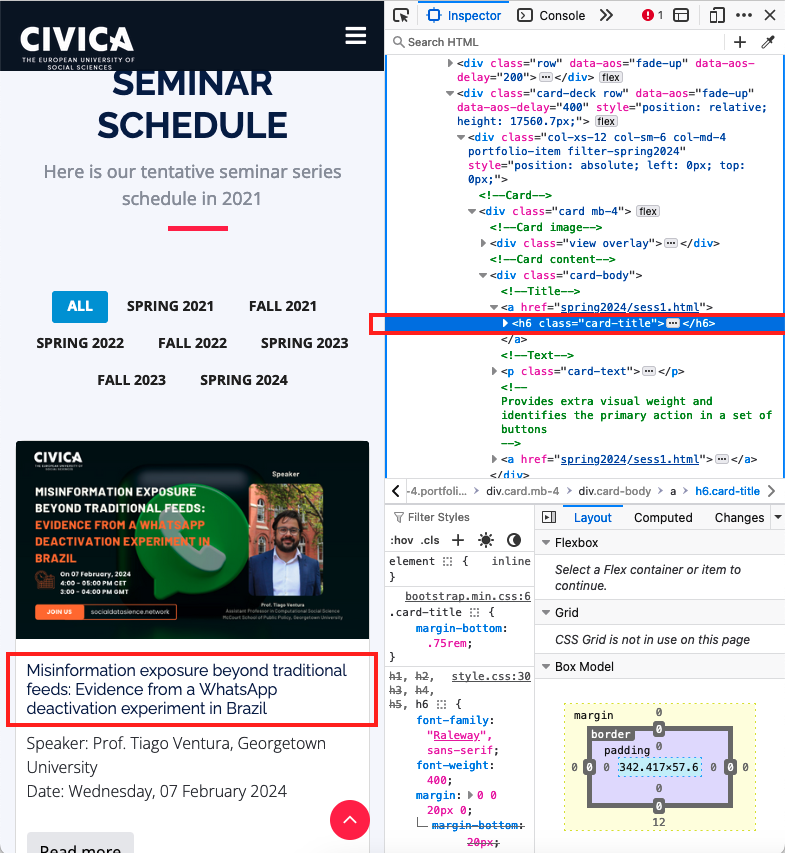
💡 TIP: Pay close attention to how the tags are nested!
Our <h6> tag doesn’t appear isolated within the body structure of the HTML (<html> <body> ... </body> </html>). Instead, developers and web designers intentionally constructed this website so that the content boxes and their titles are nested deeply within several <div> and <section> tags.
For example, this is what the surrounding structure of our desired title looks like:
<div class="card-body">
<!--Title-->
<a href="spring2024/sess1.html">
<h6 class="card-title">Misinformation...</h6>
</a>
<!--Text-->
<p class="card-text">Speaker: ... <br> Date: ...</p>
<a href="spring2024/sess1.html">
<button>Read more</button>
</a>
</div>Q2
Write down the full “directions” inside the HTML file to reach the event title.
To obtain the full path to the title, right-click on the tag and select “Copy,” then choose the appropriate option. The method of copying may differ depending on your browser. In Mozilla Firefox, the following options are available:
Copy > Copy CSS Path
This shows just how deep the title is nested within the HTML structure. Here’s the full path to the title:
html body main#main section#schedule.section-with-bg div.container.wow.fadeInUp div.card-deck.row div.col-xs-12.col-sm-6.col-md-4.portfolio-item.filter-spring2024 div.card.mb-4 div.card-body a h6.card-titleCopy > Copy CSS Selector
This option provides a more direct way to access the title using CSS selectors:
.filter-spring2024 > div:nth-child(1) > div:nth-child(2) > a:nth-child(1) > h6:nth-child(1)Copy > Copy XPath
XPath is an alternative method for specifying HTML tags, similar to specifying a path in the Terminal. Here’s the full XPath to the title:
/html/body/main/section[2]/div/div[3]/div[1]/div/div[2]/a[1]/h6We will talk about XPath in the 👨🏻🏫 Week 05 lecture.
Q3
Write the required Python code to scrape the CSS selector you identified above.
Here’s the Python code to scrape the title using the CSS selector:
url = "https://socialdatascience.network/index.html#schedule"
response = requests.get(url)
selector = Selector(text=response.text)
# Specify the full CSS Path to the title
# Note that I added the `::text` to extract the text inside the tag
title_css_path = "html body main#main section#schedule.section-with-bg div.container.wow.fadeInUp div.card-deck.row div.col-xs-12.col-sm-6.col-md-4.portfolio-item.filter-spring2024 div.card.mb-4 div.card-body a h6.card-title::text"
# Specify the CSS Selector to the title
# Note that I added the `::text` to extract the text inside the tag
title_css_selector = ".filter-spring2024 > div:nth-child(1) > div:nth-child(2) > a:nth-child(1) > h6:nth-child(1)::text"
# Use either the CSS Path or the CSS Selector to extract the title
title = selector.css(title_css_path).extract_first()
print(title)💬 CONSIDER THIS: While both the full CSS Path and the CSS Selector provided above function adequately, they are not optimal.
For one, they are not very human-readable. The CSS Path is quite lengthy, and the CSS Selector, although more concise, still relies on manual indexing (selecting the first child of a div, then its second child, and so forth). This makes the code more prone to breaking if the website’s structure changes even slightly in the future.
Q4
Let’s simplify. Let’s capture the title of the first event again, but instead of writing the entire full absolute path, like above, identify a more direct way to capture it.
- Note: Either use scrapy’s
.extract_first()or useextract()and later filter the list using regular Python
Here’s a more direct way to capture the title of the first event using a CSS Selector:
# I noticed that only event titles use the <h6> tag
# I can specify the tag directly in the CSS Selector
title_css_selector = "h6::text"
title = selector.css(title_css_selector).extract_first()
print(title)Alternatively, you can use the extract() method and filter the list using regular Python:
title = selector.css(title_css_selector).extract()
# Filter the list to get the first title
title = title[0](The first approach is a bit more elegant and also more efficient, as it doesn’t require creating a list of all the titles on the page just to filter it afterwards.)
Q5
Collect all the titles. OK, now let’s practice getting all event titles from the entire page. Save the titles into a list.
NOTE: Again, collect all the information from the webpage at once. Don’t use the notion of containers just yet. We will practice it in the W05 lecture.
Presumably, the code above - with the CSS Selector h6::text - will already collect all the titles from the entire page.
titles = selector.css("h6::text").extract()That’s it. Or is it? The next question will explain why this approach is not always the best.
Q6
Do the same with the dates of the events and speaker names and save them to separate lists.
NOTE: Again, collect all the information from the webpage at once. Don’t use the notion of containers just yet. We will practice it in the W05 lecture.
Using the same approach as before, after inspecting the page again, you will eventually discover that the info you want is inside the <p> tag that contains the class card-text.
Interestingly, the information is not separated by any tag but by a line break (<br>). There is no way to capture that with a CSS Selector alone. 1.
👉 Note also that the break line is an odd tag. It’s a tag that doesn’t have a closing tag! More confusingly, sometimes it appears as <br> and sometimes as <br/>.
Option 01: capture the text and post-process it in Python
Knowing what you know, you could still use the ::text pseudo-element to capture the text inside the <p> tag but you will need to post-process the text later using Python.
# Get everything inside the <p> tag
info = selector.css("p.card-text::text").extract()However, there’s a drawback: the extract() function will split the text by line breaks, resulting in a list of strings containing alternating speaker names and dates.
That is, if you look inside the info list, you will see:
['Speaker: ... ', ' Date: ...',
'Speaker: ... ', ' Date: ...', ...]Not the end of the world. From here, I could just filter the list to get the speaker names and dates separately. Inspired by the code that Oliver Gregory shared in the #help-python-pandas channel on Slack, I could do something like:
dates = []
speakers = []
for i in range(len(info)):
if i % 2 == 0:
speakers.append(info[i])
for i in range(len(info)):
if i % 2 != 0:
dates.append(info[i])This works! But there’s a neat and elegant alternative way to do this using list slicing:
# Start at item 0 and go to the end, step by 2
speakers = info[::2]
# Start at item 1 and go to the end, step by 2
dates = info[1::2]Option 02: use the xpath method
As you will eventually learn, XPath lets you capture the text inside the <p> tag and separate the speaker names and dates in one go. All we need to do is to specify the position of the text we want to capture.
speakers_xpath = "//p[@class='card-text']/text()[1]"
speakers = selector.xpath(speakers_xpath).extract()
dates_xpath = "//p[@class='card-text']/text()[2]"
dates = selector.xpath(dates_xpath).extract()This is definitely the most elegant and efficient way to capture the speakers’ names and dates. This is preferred over the previous method. The XPath is concise and arguably human-readable, and the code is more efficient as it doesn’t require processing the collected text in Python afterwards.
Q7
🥇 Challenge: Combine all these lists you captured above into a single pandas data frame and save it to a CSV file.
Tip 1: Say you have lists called dates, titles, speakers, you can create a data frame (a table) like this:
df = pd.DataFrame({'date': dates,
'title': titles,
'speakers': speakers})Tip 2: What if an event does not have a date or speaker name? Set that particular event’s date or speaker to None
At first glance, this seems like a super simple task. But it’s not.
As soon as you try to simply copy and paste the code above, you will notice that the lists dates, titles, and speakers have different lengths. This is because some events don’t have a date or a speaker name!
Let’s print out the lengths of the lists to see what we’re dealing with:
print(len(titles), len(dates), len(speakers))yielding:
39 35 35Four events don’t have a date or a speaker name.
What should you do in this case? Here is what I recommend:
Option 01: Debug the issue
Try to understand why some events don’t have a date or a speaker name. Is it a problem with the code? Or is it a problem with the website?
At least on Firefox, the Inspector window lets you search the page using the same CSS selectors you’d use on scrapy. You can type it on the search bar there (see the bit in yellow in the image below).
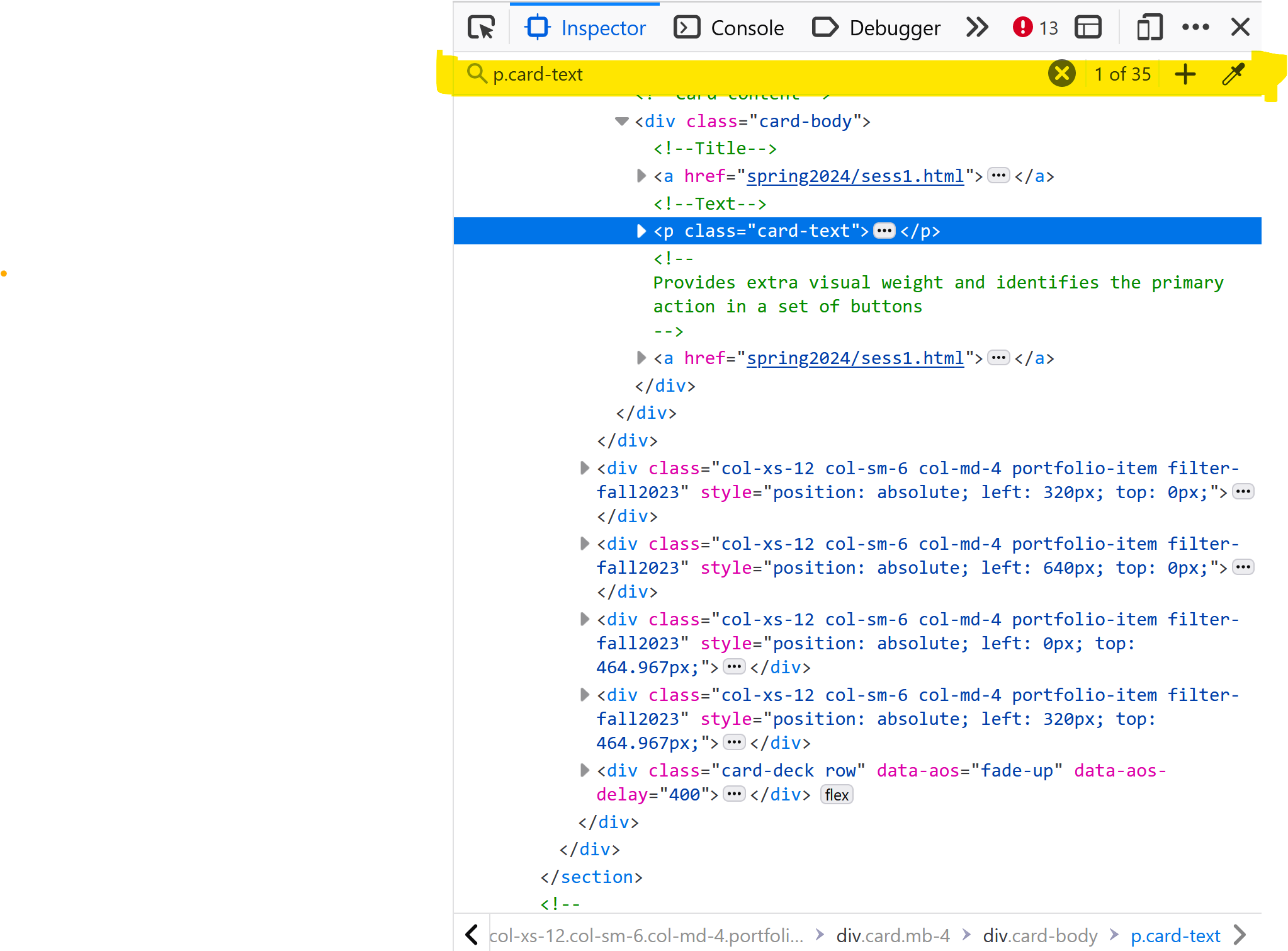
Keep hitting Enter to navigate the multiple matches and determine which ones are left out when using this selector.
👉 Eventually, you’ll notice that while all boxes contain paragraphs displaying speakers and dates, a few relevant <p> tags lack the card-text class. Why? Well, who knows! It seems like the maintainers of the website might have forgotten to tick a box or something.
These inconsistencies are super common in web scraping. It’s important to be aware of them and to know how to handle them.
Option 02: Think of a more robust selector
Instead of immediately selecting the p.card-text, we could consider using a parent tag as our reference point.
The <div class="card-body"> tag is the most natural reference point in this context. As the overarching container for the event details, given that it contains only a single <p> tag, we can use the div.card-body selector to capture the information.
Using CSS Selectors:
info = selector.css("div.card-body > p ::text").extract()
## Use the list-slicing method to separate the speakers and dates
speakers = info[::2]
dates = info[1::2]Using XPath:
speakers_xpath = "//div[@class='card-body']/p/text()[1]"
speakers = selector.xpath(speakers_xpath).extract()
dates_xpath = "//div[@class='card-body']/p/text()[2]"
dates = selector.xpath(dates_xpath).extract()Perfect! Now, we have the same number of speakers, dates, and titles. We can proceed to create the data frame and save it to a CSV file.
df = pd.DataFrame({'date': dates,
'title': titles,
'speakers': speakers})
df.to_csv("seminar_series.csv", index=False)In the upcoming lecture, 👨🏻🏫 Week 05, we will discuss XPath and how to write custom functions to extract all you need from containers.
Footnotes
But it’s possible to use an XPath though! See Option 2 We will talk about it in the 👨🏻🏫 Week 05 lecture.↩︎