
📝 W08 Summative
2023/24 Winter Term
⏲️ Due Date:
- 6 March 2024 at 5 pm UK time
If you submit after this date without an authorised extension, you will receive a late submission penalty.
Did you have an extenuating circumstance and need an extension? Send an e-mail to 📧
🎯 Main Objectives:
- Practice some more web scraping in Python
⚖️ Assignment Weight:
20%
This assignment is worth 20% of your final grade.
📚 Preparation
Read carefully. Some details are different from the previous assignments.
Find the GitHub assignment link: Go to our Slack workspace’s
#announcementschannel. We don’t share the link publicly. It is a private repository for enrolled students only.Accept the assignment: Click the link, sign in to GitHub, and click the green button.
Access your private repository: You’ll be redirected to a new private repository named
ds105w-2024-w08-summative-<yourusername>.Clone your repository: Clone your repository to your computer. A folder
ds105w-2024-w08-summative-<yourusername>will appear on your computer. We will refer to this folder as<github-repo-folder>in the rest of this document.Mandatory requirement: keep your AI chat logs. If you used AI tools for assistance with this assignment, it’s essential to retain a log of your chat interactions. We will collect your chat logs just before releasing your grades (after grading and de-anonymising your assignment).
For
 GENIAL participants: Submit your logs via the standard weekly forms. We’ll take it from there.
GENIAL participants: Submit your logs via the standard weekly forms. We’ll take it from there.If you have chosen not to participate in the study, we’ll contact you via e-mail when the time comes to submit your logs.
Please Note: There will be no penalties for using or abstaining from using AI tools.
Learn how to get help:
- Pose questions in the public channels on Slack.
- Attend the drop-in sessions facilitated by our colleagues at the Digital Skills Lab.
- Refer to the 🙋 Getting Help section below for guidance on collaborating with peers without compromising the originality of your work.
📋 Tasks
The questions below primarily build on principles taught at the 👨🏻🏫 W04 Lecture & 👨🏻🏫 W05 Lecture, 💻 W05 Lab as well as 💻 W07 Lab.
What do we actually want from you?
📝 Task 0: Context and Setup
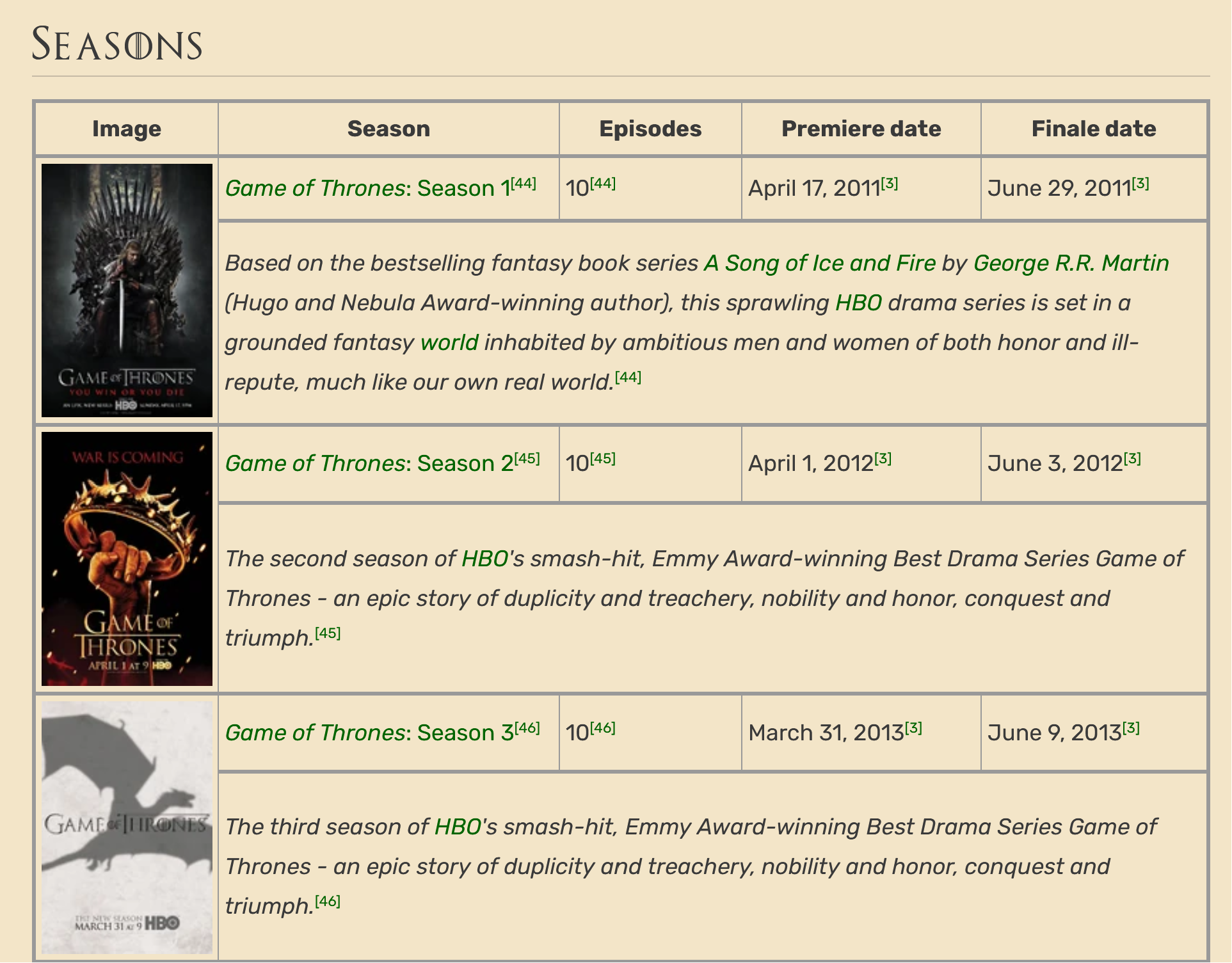
Online wikis are pages that resemble encyclopaedia articles maintained by a community of users. They are often used to create collaborative websites and to power community websites. Wikipedia is the most famous example of a wiki. For this assignment, we will use the Fandom Wiki to scrape information about TV shows. The Fandom Wiki is actually a collection of multiple wikis, each dedicated to a specific topic. For example, the Wiki of Westeros is a wiki dedicated not only to the main Game of Thrones series but also to the prequel and spin-off series.
Choose a TV show from the Fandom Wiki wikis. It must be one with at least 5 seasons.
On your browser (no coding), navigate the website until you identify the
base_urlfor the TV show you chose, where there is a list of all the TV show seasons. For example, the base URL for the Game of Thrones Wiki is https://gameofthrones.fandom.com/wiki/Game_of_Thrones.
Create two notebooks somewhere in your repository:
NB01 - Data Collection.ipynb: You will use this notebook to complete Task 1 & Task 2.NB02 - Data Analysis.ipynb: You will use this notebook to complete Task 3.
Note: We will not provide you with a notebook template nor with the structure of folders for your repository. You are to find a way to organise your repository and notebooks in a way that makes sense.
📝 Task 1: Collecting a list of episodes (30 marks)
Here, you will write code to scrape the links to all the episodes of the TV show you chose.
We don’t provide a template, but we have strict requirements for how we want you to write the logic to scrape the data. You will lose marks if any part of your code doesn’t meet these requirements.
Requirements:
- If you complete this task successfully, you will end up with a single pandas data frame with precisely the following columns:
tv_showis the name of the TV show you chose (string).season_numis the season number (integer).season_urlis the URL of the season’s wiki page (string).episode_numis the episode number (integer).episode_urlis the URL of the episode’s wiki page (string).episode_titleis the title of the episode (string).air_dateis the episode’s air date (date).
| tv_show | season_num | season_url | episode_num | episode_url | episode_title | air_date |
|---|---|---|---|---|---|---|
| … | … | … | … | … | … | … |
Somewhere in your code, there must be a string variable
base_urlwith the URL of the TV show wiki.Somewhere in your code, there must be a string variable
tv_showwith the name of the TV show you chose.Somewhere in your code, there must be a function
get_season_linkswith the following signature:def get_season_links(base_url): """ This function returns a list of dictionaries with each season's number and URL. Args: - base_url (str): The base URL of the TV show wiki. Returns: - list: A list of dictionaries with each season's number and URL. """Add the code to collect the URLs of the seasons inside this function.
💡 Pay close attention to the keys of your Python dictionaries. They must match some of the names of columns in the data frame we want you to produce.
Somewhere in your code, there must be a function
get_episode_datawith the following signature:def get_episode_data(season_url): """ This function returns a single dictionary that represents all the episodes of a season. Args: - season_url (str): The URL of the season's wiki page. Returns: - dict: A single dictionary containing the episode number, title, air date, and URL of all episodes. """The output dictionary should look something like this:
{ 'episode_num': [1, 2, 3, ...], 'episode_url': ['https://...', 'https://...', 'https://...', ...], 'episode_title': ['Winter Is Coming', 'The Kingsroad', 'Lord Snow', ...], 'air_date': ['2011-04-17', '2011-04-24', '2011-05-01', ...] }- Add the logic to collect the URLs of the episodes inside this function.
You must then use the code below to create the data frame.
This code contains advanced pandas operations you are not expected to know yet. As long as you did the previous steps correctly, this code will work and produce the data frame in the format we want.
# Create an initial data frame with the seasons' links df = pd.DataFrame.from_dict(get_season_links(base_url)) # Add the TV show name to the data frame df['tv_show'] = tv_show # Create a new column with all episode information df['episode_data'] = df['season_url'].apply(get_episode_data) # Convert the episode_data column into a data frame # and join it with the original data frame df = ( pd.json_normalize(df['episode_data']) .join(df.drop(columns='episode_data')) .explode(['episode_num', 'episode_url', 'episode_title', 'air_date']) ) # Re-order the columns ordered_columns = ['tv_show', 'season_num', 'season_url', 'episode_num', 'episode_url', 'episode_title', 'air_date'] df = df[ordered_columns].copy()Save the data frame as a suitably-located CSV file.
📝 Task 2: Collecting important info from episodes (50 marks)
The wiki pages for each episode invariably feature a synopsis written in paragraphs by the community. Interestingly, these synopses often include links referencing concepts of the universe of the TV show, such as specific characters, locations, or events. For example, see the image below:

Notice how the paragraph contains links to characters, locations, and other concepts from the Game of Thrones universe, as shown in the table below:
| Term | Points to link | Concept |
|---|---|---|
| rangers | Ranger | Character |
| Night’s Watch | Night’s Watch | Organisation |
| Ser | Knighthood | Title |
| Waymar Royce | Waymar Royce | Character |
| Will | Will | Character |
| Gared | Gared | Character |
| Wall | Wall | Location |
| wildlings | Free Folk | Organisation |
| Haunted Forest | Haunted Forest | Location |
| Beyond the Wall | Beyond the Wall | Location |
| wildling girl | Wildling Girl | Character |
💡 SMALL BUT IMPORTANT DETAIL: It’s worth noting that the word used in the link may not always match the title of the page it links to. For instance, in the paragraph above, we see the word “ranger,” but clicking on the link takes you to a page titled “Ranger” (with a capital “R”). Another example is the word “Ser,” which directs you to a page titled “Knighthood.”
Your task is to scrape the synopses of all episodes and create a CSV file that matches the columns of the following example:
| tv_show | season_num | episode_num | paragraph_id | link_title | link_url |
|---|---|---|---|---|---|
| Game of Thrones | 1 | 1 | 1 | Ranger | Ranger |
| Game of Thrones | 1 | 1 | 1 | Night’s Watch | Night’s Watch |
| … | … | … | … | … | … |
Where:
tv_showis the name of the TV show you chose (string).season_numis the season number (integer).episode_numis the episode number (integer).paragraph_idis the paragraph number (integer). The first paragraph in the synopsis is1, the second is2, and so on.link_titleis the title of the page the link points to (string). For example, the string “Ranger.”link_urlis the URL of the page the link points to (string). For example, the string “https://gameofthrones.fandom.com/wiki/Ranger.”
Remember to add your code to the NB01 - Data Collection.ipynb notebook. We won’t give you a template or a specification of how you should write your code. You must write the logic to scrape the data and build the data frame yourself.
📝 Task 3: Discovery (20 marks)
Use your Python (or pandas) skills creatively to show us an interesting insight from the collected data. For instance, you could explore how frequently a particular character appears in each episode or analyse the co-occurrence of two concepts or characters within the same paragraph.
Use the NB02 - Data Analysis.ipynb notebook to do this.
Wrapping up
- Ensure your GitHub repository is well-organised and contains all the necessary files to replicate your work.
✔️ How we will grade your work
- We will run your notebook and check if it produces the expected CSV files and analysis without errors.
- We will check if your repository (files, folders, notebooks) is well-organised and self-explanatory.
- If you are ambitious about achieving a First in this course, we recommend focusing on the organisation of your repository, the quality of your comments, the efficiency of your code and the complexity of the insights you can extract from the data.
Task 1 (30 marks)
Here is a rough rubric for this part:
get_season_links() function
| Marks awarded | Level | Description |
|---|---|---|
| 15 marks |
Excellent | - If we run get_season_links with the base URL of the TV show wiki, it returns a list of dictionaries with each season’s number and URL as expected - We see a good use of CSS/XPath selectors (not overly complex) to extract the relevant info - You used list/dict comprehension - You used the required libraries ( requests and scrapy). - You moved the functions to a .py file instead of leaving them in the notebook. Your notebook is neatly organised with headers and explanations |
| 12-14 marks |
Very Good | If we run get_season_links with the base URL of the TV show wiki, we get the expected output. It is just short of excellent. |
| 8-10 marks |
Reasonable | If you managed to produce the expected output but you didn’t follow the instructions correctly. - For example, your code is not in a function, or you created a function that doesn’t adhere to the template provided. Or, perhaps you wrote code that is too complex for no good reason or similar reason. |
| <8 marks |
Poor | We don’t get the expected output when we run get_season_links with the base URL of the TV show wiki; your notebook is full of errors, or you failed to follow the instructions. |
get_episode_data() function
It is the same as above but for the get_episode_data function.
Task 2 (50 marks)
Here is a rough rubric for this part:
| Marks awarded | Level | Description |
|---|---|---|
| 50 marks |
WOW | - If we run your code, we get the expected CSV file with the correct columns and rows. - The data frame you created adheres to the instructions. Or if, for some reason, some of the data could not be collected, you provided a clear explanation of the issue. - Your logic is clear, and the notebook is well-documented. - Instead of a single huge chunk of code, you broke the task into smaller, more manageable parts. - We see good use of CSS/XPath selectors (not overly complex) to extract the relevant info - You moved the functions to a .py file instead of leaving them in the notebook. - You favoured the use of pd.apply() + custom functions + list/dict comprehensions over for loops. - You used the required libraries ( requests and scrapy). - You exceeded the expectations very positively (say, by using scrapy’s spiders functionality masterfully or other advanced yet elegant solutions that we haven’t had the chance to teach you). |
| ~45 marks |
Excellent | - Nearly all of the above! |
| ~40 marks |
Very Good | - If we run your code, we get the expected CSV file with the correct columns and rows. It just wasn’t absolutely perfect. - There will be comments about what could have been improved. |
| 35-40 marks |
Good | - If we run your code, we get the expected CSV file with the correct columns and rows. But things could have been better. - For example, your code is not organised into smaller, more manageable parts, or you wrote code (CSS/XPath selectors, loops, etc) that is too complex for no good reason |
| 25-35 marks |
Reasonable | - You have put in some effort. We see the code and that a data frame was produced, but you did not fully adhere to the instructions. - For example, you didn’t collect all the data or did not clearly explain the issue. Or, perhaps your notebook has errors, or the code is convoluted, very complex, or not well-documented. |
| 10-25 marks |
Weak | - You have clearly tried but didn’t achieve much. You probably should have asked for help! - For example, you didn’t collect much data, your notebook is full of errors, or you failed to follow most of the instructions. |
| <10 marks |
Poor | - We don’t get the expected CSV file when we run your code. Your notebook is full of errors, or you failed to follow the instructions. |
Task 3 (20 marks)
Here is a rough rubric for this part:
| Marks awarded | Level | Description |
|---|---|---|
| 20 marks |
WOW | - You cleverly used Python/pandas (or even other packages!) to show an interesting insight from the collected data. - You used the NB02 - Data Analysis.ipynb notebook to do this. - Your insight is well-documented and well-presented. - We are surprised you managed to find the time to do this! |
| ~15 marks |
Excellent | - Excellent use of pandas summaries, visualisations, or other Python packages to show an interesting insight from the collected data. - You used the NB02 - Data Analysis.ipynb notebook to do this. - Your insight is well-documented and well-presented. |
| 10-15 marks |
Good | - You used Python/pandas to show an interesting insight from the collected data, but your code or documentation could have been better - Still, you used the NB02 - Data Analysis.ipynb notebook to do this. |
| 5-10 marks |
Reasonable | - You have put in some effort. We see the code and that an insight was produced, but it was too basic (a simple count, for example) or not well-documented. |
| <5 marks |
Weak | - You didn’t achieve much or you didn’t adhere to the instructions. |
📦 Submission
- All you need to do is push your changes to your GitHub repository. We will take it from there.
- If you are unsure whether your local changes were pushed correctly, visit the repository on GitHub and check if your changes are there. What you see on the website is what we will see when we grade your work.
How to get help and how to collaborate with others
🙋 Getting help
You can post general coding questions on Slack but should not reveal code that is part of your solution.
For example, you can ask:
- “What is a good way to extract just the middle part of a string?”
- “How do I convert a string to a date?”
You are allowed to share ‘aesthetic’ elements of your code, if they are not part of the core of the solution. For example, suppose you find a really cool new way to write a for loop. You can share that on Slack.
If we find that you posted something on Slack that violates this principle without realising, you won’t be penalised for it - don’t worry, but we will delete your message and let you know.
👯 Collaborating with others
You are allowed to discuss the assignment with others, work alongside each other, and help each other. However, you are not allowed to share code or to copy code from others. Pretty much the same rules as above. Copying code from others is plagiarism and will be dealt with accordingly.
Aim to strike a balance: you want to be able to talk to others about programming in general without getting too specific about the assignment. This is a good way to ensure your submission has your personal touch (more likely to earn more marks) and avoid getting into trouble.
🤖 Using AI help?
Be careful! AI tools can be handy but can also be a trap. Try to solve the problem by yourself first, and only then use AI tools to help you.
You can use Generative AI tools such as ChatGPT when doing this work and search online for help. If you do use it, however minimal use you made, you are asked to report in the final section of your notebook, explaining which tools and the extent to which you used it and to keep the chat logs that show evidence of how you used it.
If you are a
GENIAL participant, things are easier for you. Just don’t forget to submit your logs via the standard weekly forms.If you don’t participate in the study, we’ll contact you via e-mail when the time comes to submit your logs.
To see examples of how to report the use of AI tools, see 🤖 Our Generative AI policy.