
✍️ Mini-Project 2 (30%): London Transport Connectivity Analysis
2025/26 Autumn Term
Fill out the LSE Course Survey about DS105A. It’s quite important!
Current response rate: 17% (14 of 82 students)
0% to 50% 50% to 75% 75% to 100%
Remember that everyone on the teaching team qualifies as “your teacher” in the survey, so please rate each person you have interacted with this term.Last updated: 25 November 2025, 2pm
This is your second graded summative assignment, worth 30% of your final mark. Mini-Project 2 builds directly on the workflow you developed for Mini-Project 1, but introduces a new API and an exploratory question that gives you even more autonomy to choose your own direction.
| ⏳ | Deadline | Wednesday, 3 December 2025 (Week 10) at 8 pm UK time |
| 💎 | Weight | 30% of final grade |
| ✋ | GitHub Classroom | GitHub Classroom Repository (link on Moodle for registered students) |
📝 The Question
Just as you did in the ✍️ Mini Project 1, you are asked to investigate a specific question using predefined data sources.
This time, you are asked to investigate the question:
Where are the areas in London with poor transport connectivity?
This question is intentionally exploratory. You will have to define what constitutes “poor connectivity”, figure out how to measure it, choose the right evidence, then communicate what you find. Consider journey time, frequency, or accessibility as starting points for your methodology. Your project must be scoped to answer this question given the requirements mentioned below.
🚫 For security reasons, I cannot post the invitation link here on the public website. Go to Moodle to view the uncensored version of this page. The invitation link is available there.
Click here for a 💡 TIP
💡 TIP ON HOW TO GET STARTED
Start simple. Don’t go overboard from the start. The worst thing you can do is to start by gathering data for all of London. That’s a lot of data to process and it will be very time-consuming.
For example, start by using LSE as your reference point and then think of one single area of London where you know it’s easy to get to LSE by public transport. Gather data, make it tabular, then see if it matches your intuition. Git add, git commit, git push. Start there and build up later.
📋 High-level requirements
Project structure
Your project MUST be structured as identified in the file tree below. You can read about what each file is for in the sections below.
<your-github-repo-folder>/
├── NB01-Data-Collection.ipynb # Template provided, you adjust it to your needs
├── NB02-Data-Transformation.ipynb # You create
├── NB03-Exploratory-Data-Analysis.ipynb # You create
├── REPORT.md # Two insights, narrative titles, visuals
├── README.md # Very brief this time - project overview and reproduction notes
├── data/
│ ├── raw/
│ │ ├── london_postcodes-ons-postcodes-directory-feb22.csv # Not tracked by git
│ │ └── *.json # or *.csv files, your choice
│ └── processed/
│ └── *.csv (or london_transport.db, optional)
└── .env # Not tracked by gitIf you think you need to deviate from the above, ask us in the #help Slack channel for advice before the day of the deadline.
Click here for a 💡 TIP
💡 TIP ABOUT THE FIRST COMMIT
Practice your Terminal and ![]() Git command skills from the very start so that you don’t get confused later on with the different files and folders.
Git command skills from the very start so that you don’t get confused later on with the different files and folders.
# If using Nuvolos, make sure to change to the correct directory first.
cd /files/<your-github-repo-folder>
# Create all necessary folders
mkdir -p data/raw data/processed
# Create remaining files
touch .env
touch NB02-Data-Transformation.ipynb
touch NB03-Exploratory-Data-Analysis.ipynb
git add NB02-Data-Transformation.ipynb
git add NB03-Exploratory-Data-Analysis.ipynb
git commit -m "Create empty NB02 and NB03 notebooks"
git push🗄️ Data sources
However you choose to answer the question of the project, you MUST use data solely from these two specific data sources:
TfL API, more specifically the Journey Planner endpoint:
https://api.tfl.gov.uk/Journey/JourneyResults/{from}/to/{to}And you are to collect it using the
requestslibrary, like we have been doing in the course so far.
How to get a TfL API key
Go to api-portal.tfl.gov.uk and click on the ‘register’ link to sign up for an account. Use any e-mail address you like.
TfL requires us to explicitly register for their API key after we’ve signed up.
After signing on, go to the Products tab and find the ‘500 Requests per min’ product (or click 🔗 this direct link).
Subscribe to the product by entering some identifier in the textbox and clicking the ‘Subscribe’ button.
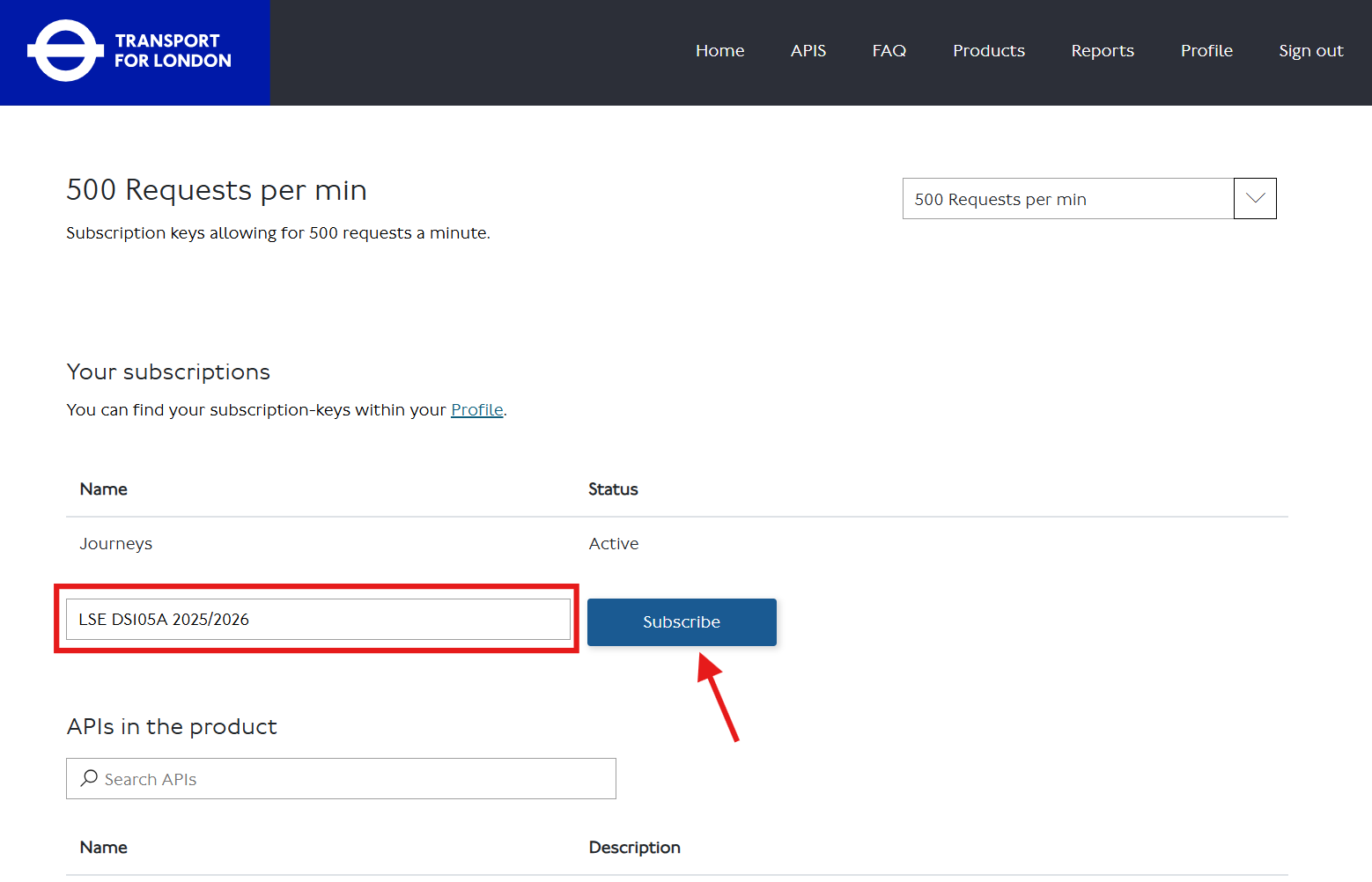
This will likely take you to the keys page, where you will see your API key hidden in there.
Click ‘Show’ to reveal your API key. Copy it and paste it into your
.envfile with an appropriate name:API_KEY=your_key_hereYou can always go back to your TfL API - Profile page to check your API key again.
-
This is a static CSV that you will have to download and load into your project. Git does not like large files, so this file will be in the
.gitignoreby default.
How to download the ONS Postcode Directory
Simply go to the ONS Postcode Directory page and click on the ‘Download’ button.
Download the latest version of the ONS Postcode Directory, a 122Mb file called
london_postcodes-ons-postcodes-directory-feb22.csv, to your computer. DO NOT RENAME THIS FILE OR YOU WILL HAVE TROUBLE WITH GIT LATER ON.Upload the file to the
<your-github-repo-folder>/data/raw/folder using the Nuvolos file explorer. Note: this means you must go inside your<your-github-repo-folder>folder and then into thedata/raw/folder inside it.Confirm that this file is correctly
gitignoredby running the following command:git statusYou should NOT see the
london_postcodes-ons-postcodes-directory-feb22.csvfile listed. If the file appears there, it means that something is wrong with your.gitignorefile.
Click here for a 💡 TIP about data collection
💡 TIP ON HOW TO GET STARTED
Once again, start simple. Don’t try to use all parameters available in the API. Start with just the from and to parameters and see what the JSON looks like.
For example, discover the coordinates for LSE (add a line to your REPORT.md to document how you located it) and then use it to make a request to the API. See what the JSON looks like, make it tabular, then see if it matches your intuition. Git add, git commit, git push. Start there and build up later.
📌 Your decisions and where to document them
📌 DECISIONS, DECISIONS, DECISIONS
You will need to make several decisions independently:
Reference point: Use LSE as your reference point, or justify any alternative choice.
Locations: Which specific postcodes (or lat+long pairs) will you use to investigate the question? How will you justify your choice? 📚 See Appendix for essential columns that will help you select meaningful postcodes.
Time period: what time period will you use to collect the data? How will you justify your choice?
Other details about the data: Whatever else you decide to do with the data, you MUST document it in your
REPORT.mdfile. That includes but is not limited to: specific modes of transportation, specific parameters passed to the API, or any decisions related to the London Postcode Directory dataset.
Click here for 💡 TIPS
💡 TIPS ON HOW TO MAKE THE DECISIONS
Reference point: Use LSE as your reference point, or justify your alternative choice in your
REPORT.mdfile. Add your choice to yourREPORT.mdas soon as you have decided on it.Locations: START SMALL! Grab data for a single location, make it tabular, explore it a bit, familiarise yourself with the data first, only then go back and add more locations.
Time period: As you learned in practice with the ✍️ Mini Project 1, APIs might not always allow you to collect data for the entire time period you want. Read the documentation and play around with the time parameters to find out what is possible. Document your findings in the
REPORT.md.Other details about the data: Whatever else you decide to do with the data, you MUST document it in your
REPORT.mdfile. That includes but is not limited to: specific modes of transportation, specific parameters passed to the API, or any decisions related to the London Postcode Directory dataset.
🧰 Technical Requirements
Here is a list of MUST-DOs for your project:
You MUST add reflection notes in your notebooks to document your learning process.
If you use AI a lot in this assignment, don’t forget to share your chat logs (
REPORT.mdor in notebooks). It helps us see your learning process directly and you don’t need to write as much in your reflection notes.
What to write in the reflection notes
Say you were trying to produce a plot but it took you forever to figure out how to write the write code to produce the plot_df. You could add a Markdown cell like this:
💭 **Personal Reflection Notes:**
* I couldn't find a way to aggregate [this and that columns] [this way]. I tried to adapt the code from [particular lecture/class] but it wasn't working because [...]. The Claude bot suggested [blah] and although it didn't work at first, when I tweaked [bleh] and got to the version below that works!- All data collection MUST happen in
NB01and you MUST use therequestslibrary to authenticate with the TfL API and collect the data.
Rate limiting guidance
When making multiple API requests in a loop, use time.sleep(2) between requests to avoid overwhelming TfL servers. For example:
for postcode in postcodes:
response = requests.get(url, params=params)
# Process response... and save it somewhere
time.sleep(2) # Wait 2 seconds before next requestThis prevents rate limiting errors and shows good API citizenship.
Whatever data is produced in
NB01MUST be saved in thedata/raw/folder but you can choose to save it as either raw JSON files or as raw CSV files (your choice). The data does not need to be cleaned up and polished in this notebook.You can use
forloops inNB01for data collection, but you MUST use vectorised operations for analysis inNB02andNB03.If you feel you must use a
forloop for analysis then you must document why NumPy/Pandas alternatives wouldn’t work for your specific need.In your
NB02notebook, you MUST read the data from thedata/raw/folder and save processed data to thedata/processed/folder. You can save as CSV files or optionally as a SQLite database (e.g.,london_transport.db).You will learn about SQLite databases in the 🖥️ W08 Lecture if you want to use them, but they are optional for this assignment.
In your
NB03notebook, you MUST read the processed data fromNB02and explore it to search for relevant insights which you will then document in yourREPORT.mdfile. Every time you produce a plot, you MUST use theplot_dfpattern taught in the 🖥️ W05 Lecture and reinforced in 🖥️ W07 Lecture and 💻 W07 Lab. You will also see more advice on data visualisation throughout the 🖥️ W07-W09 Lectures.🗗️ Geographic visualisation tools with
geopandaswill be introduced in 🖥️ W09 Lecture if you want to create geographical maps.🗒️ IMPORTANT: This means that this time around you don’t need to worry about keeping only two clean insights in
NB03. You can freely explore your data here and the plots don’t all need to look super clean and pretty. You can produce as many insights as you want and only polish two relevant things (with nice titles and styling) to include in yourREPORT.mdfile. We will check that the code is good and aligned with the course philosophy (vectorised operations throughout) but in terms of insights, only the two polished insights will be marked.You MUST fill out the placeholders in the
README.mdand theREPORT.mdfile. This includes explaining whether you used AI and how much - if at all - AI has helped you in the process of building this project.
What do you mean by ‘placeholders’?
You will find that I have already written a good template for these two documents so you can focus most of your time and energy on the actual analysis and writing of the insights.
In both the README and the REPORT, you will find square brackets with the text [TODO: ...]. These are the placeholders for you to fill in with your own text.
For example, in the README.md file, you will find the following placeholder:
[TODO: ...explain _why_ you focused on this question the way you did...].You should replace this entire line - removing everything between the square brackets and replacing it with your own text.
✔️ How We Will Grade Your Work
I don’t enjoy this but, unfortunately, I must be strict when grading summative assignments to mitigate fears over grade inflation.
Higher marks are to be reserved for those who demonstrate exceptional talent or effort, in ways that align with the learning objectives and coding philosophy of this course (simply adding more analysis or complicating the code is not sufficient).
Critical reminder: You are graded on your reasoning process and decision documentation. Correct output with weak justification scores lower than incorrect output with clear evidence of learning.
Coherence matters: We assess whether what you write in your reflections matches what you actually did in your code. If you use sophisticated techniques but can’t explain why you chose them or how they relate to what we taught in lectures and labs, this suggests the work isn’t genuinely reflective of your own learning process. We want to see you link your decisions to specific course activities (e.g., “I used vectorised operations as shown in W04 Lab Section 3” rather than generic statements).
The good news is that, if you have been attentive to the teaching materials and actively engaged with the exercises, it should still be feasible to achieve a ‘Very Good!’ level (70-75 marks).
Here is a rough rubric of how we will grade your work.
📥 Technical Implementation (0-30 marks)
Data collection, processing, and analysis quality
| Marks awarded | Level | Description |
|---|---|---|
| <12 marks |
Poor | Your code logic doesn’t work (even if it runs OK). For example: API authentication failed, you used the wrong API endpoint, files are missing, credentials are hardcoded, or your code has so many errors it can’t run. |
| 12-14 marks |
Weak | Your code runs but has multiple serious problems. For example: you collected data that doesn’t actually help answer the question, you used lots of for loops when vectorisation would work, API credentials not properly secured, files are disorganised, or your code is very messy and hard to follow. |
| 15-17 marks |
Fair | Your workflow works but has notable problems. API authentication and data collection function but with concerning issues in how you implemented things, how you organised your code, data quality issues not addressed, or disconnection between the sophistication of your code and what we taught (using advanced techniques without explaining why they’re better than what we showed you). |
| 18-20 marks |
Good | Competent technical work. API authentication and data collection working with reasonable use of the techniques we taught (vectorised operations, proper file organisation, credentials managed securely). If you used techniques beyond the course, you show some understanding of why they were appropriate or better than what we showed you. |
| 21-23 marks |
Very Good! | Clean technical execution with proper data validation and security practices. API credentials properly managed (no hardcoded keys). Evidence of data quality awareness and appropriate handling of issues (e.g., missing values, outliers) when present. Vectorised operations used effectively. Code sophistication matches written explanations: what you write reflects what you genuinely did. If advanced techniques are used, you clearly explain why they’re appropriate. |
| 24+ marks |
🏆 WOW | Exceptional technical implementation. Exceptionally clean pandas transformations, creative method chaining, professional touches like exceptionally clean and clearly named custom functions or error handling, exemplary organisation, sophisticated data quality validation. Nothing is over-engineered but serves a clear purpose. |
📊 Communication & Insights (0-40 marks)
Your insights, exploration process, and reflections
| Marks awarded | Level | Description |
|---|---|---|
| <16 marks |
Poor | Your analysis doesn’t answer the question or has too many fundamental problems. For example: insights are missing, you didn’t use seaborn, your code has too many errors to interpret, axes are unlabelled or misleading, your interpretation is completely wrong or missing, or you show no awareness of statistical reasoning. |
| 16-19 marks |
Weak | You tried to do analysis but it doesn’t work well. For example: your visualisations don’t actually show what you’re trying to say, your titles just describe what’s in the chart rather than stating a finding, your charts are poorly formatted (missing labels, messy legends), your interpretation is very shallow, inappropriate statistical choices without justification, or you barely used vectorisation when you should have. |
| 20-23 marks |
Fair | Your analysis produces some insights but has notable problems. You’ve done analytical work but there are significant weaknesses in how you communicated findings, how you implemented the analysis, statistical reasoning is weak, or disconnection between the sophistication of your techniques and what we taught (using advanced methods without explaining why they’re better than what we showed you). |
| 24-27 marks |
Good | Competent analysis with reasonable insights. Two insights produced with acceptable visualisations, reasonable interpretation, appropriate statistical choices with some justification, and use of the techniques we taught (vectorised operations, appropriate plot types). If you used analytical methods beyond the course, you show some understanding of why. |
| 28-31 marks |
Very Good! | Two compelling insights with narrative titles. Appropriate statistical choices (mean vs median) with justification. Correct interpretation of visualisations and awareness of correlation vs causation. NB03 exploration shows genuine analytical thinking. Reflections demonstrate learning and connect to course activities. What you write matches what you did. |
| 32+ marks |
🏆 WOW | Exceptional analysis with compelling narrative. Publicati |
on-quality visualisations, sophisticated seaborn styling, professional pandas technique, nuanced pattern discovery, convincing narrative, sophisticated statistical reasoning throughout. |
🧐 Research & Methodology Design (0-30 marks)
How you defined and justified your approach
| Marks awarded | Level | Description |
|---|---|---|
| <12 marks |
Poor | Key methodology documentation is missing or has too many critical problems. For example: no clear definition of “poor connectivity”, reference point not specified, location selection not justified, or we simply can’t understand your approach or why you chose it. |
| 12-14 marks |
Weak | You submitted work but methodology has multiple serious problems. For example: methodology is very vague or poorly explained, decisions are not justified, location selection is arbitrary, or multiple key methodological elements are missing or severely incomplete. |
| 15-17 marks |
Fair | Adequate methodology with notable weaknesses. Approach is defined but justifications are generic, decision-making process is unclear, or lacks connection to course content. Some reasoning present but limited. |
| 18-20 marks |
Good | Competent methodology with reasonable justification. Clear definition of connectivity measures, reference point chosen and explained, location selection justified. Some connection to course materials though may be limited. |
| 21-23 marks |
Very Good! | Thoughtful methodology with clear reasoning. Decisions connect to specific course activities where relevant. Your written methodology matches your implementation. Evidence of genuine analytical thinking rather than surface completion. |
| 24+ marks |
🏆 WOW | Exceptional methodology with sophisticated understanding. Publishable-quality methodological design with evidence of deep research, comparative reasoning, and genuine analytical thinking throughout. |
♟️ A Tactical Plan (W07-W10)
Here’s a practical approach that will get you to a solid submission. This is a suggested timeline for the project, but you are free to adjust it to your own needs and preferences.
| Week | Focus | Key Tasks |
|---|---|---|
| W07 | Setup & Data Collection | - Accept the assignment and clone the repository into Nuvolos. - Set up repository structure as described in the project structure section above. - Get TfL API key working, check what the API returns when using LSE as reference point and another postcode for a predetermined time period. - Convert the output to temporary DataFrames (in NB01 at first, just to test it out)- Ask questions in the #help Slack channel if stuck.- Think of your initial decisions and document them in REPORT.md before you forget. |
| W08 | Data Transformation | - Read about the London Postcode Directory data (📚 see Appendix for column descriptions) and come up with a method to select at least 5 different postcodes that will provide good comparisons to answer the main question. - Edit your NB01 so you use the output of the london postcode CSV as an entry point to the TfL API requests.- Decide if you want to save everything separately (one JSON per location and time period) or all into a single JSON/CSV file. - Load the data into NB02, explore it using pandas, see if you spot any initial insights, clean up the data if needed so it’s better for NB03 and then save the cleaned up CSV file(s) to data/processed/.- Ask questions in the #help Slack channel if stuck.- Document new decisions in REPORT.md before you forget. |
| W09 | Exploration | - Explore your data in NB03.- Test different visualisations and analytical approaches. - Don’t worry about making everything perfect - this is your research space. - Identify patterns that surprise you or reveal transport connectivity gaps. - Ask questions in the #help Slack channel if stuck.- Document new decisions in REPORT.md before you forget. |
| W10 | Communication | - Polish two compelling insights for your REPORT.md.- Each needs a narrative title stating your finding, a clear visualisation, and evidence-based conclusions. - Make sure your README.md explains your methodology and enables reproduction.- Ask questions in the #help Slack channel if stuck.- Complete the REPORT.md. |
🚀 If you want to go the extra mile
If you’re ambitious about getting a distinction (beyond 70+ marks) and have the time, here are some ideas of how you could impress us with your work:
- Geographic scope: Instead of individual postcodes, analyse connectivity across multiple LSOAs (Lower Super Output Areas). You can get one postcode per LSOA (or multiple postcodes per LSOA) to compare area-level patterns. This reveals whether transport connectivity gaps cluster geographically. 📚 See Appendix for geographic hierarchy explanation.
- Temporal variation: Test the same locations at different times (morning peak, midday, evening peak, weekend). This reveals whether some areas lose transport connectivity during off-peak hours, which is a finding which could have policy implications.
- Socioeconomic dimension: Use the Index of Multiple Deprivation (IMD) column present in the ONS Postcode Directory to explore whether deprived areas face worse connectivity. Remember: correlation doesn’t equal causation! 📚 See Appendix for IMD column details and important caveats.
- Database integration: If you want to practice SQLite skills from W08, design a database schema that naturally supports your analysis.
These extensions require more API calls, careful rate limiting, and sophisticated analysis. Start with the baseline approach first, then extend if time permits. Document your progression in git commits and reflections in your REPORT.md file.
📮 Need Help?
- Post questions in the
#helpSlack channel. - Check the ✋ Contact Hours page for support times.
- Book office hours via StudentHub for deeper conversations.
You are building on everything you have learned so far. Start with the simple approach, keep your reflections purposeful, and give yourself enough time to polish your communication. Good luck!
📚 Appendix: ONS Postcode Directory Data Dictionary
Most Important Columns
Here are some of the columns from the ONS Postcode Directory data that you might want to use in your analysis. Note that there’s no compulsory use of any specific column. You are free to choose them as you see fit.
| Column | Type | Description | Example | Your Use |
|---|---|---|---|---|
| pcds | string | Postcode with space | SW1A 2AA |
TfL API input, human-readable |
| lsoa11 | string | Lower Super Output Area (2011 Census) | E01004736 |
Neighbourhood unit (~1,500 people) for aggregation |
| oslaua | string | Local Authority code (Borough) | E09000033 |
Borough context (Westminster = E09000033) |
| lat | float | Latitude (WGS84 decimal degrees) | 51.5074 |
Can calculate straight-line distances if you want to compare against TfL journey times |
| long | float | Longitude (WGS84 decimal degrees) | -0.1278 |
Paired with latitude for distance calculations |
Data source: London Datastore - ONS Postcode Directory
Geographic Hierarchy (How Areas Nest)
Individual Postcode (your API query unit)
↓ ~400 postcodes aggregate into
Output Area (OA11) - ~300 residents
↓ ~5 OAs aggregate into
Lower Super Output Area (LSOA11) - ~1,500 residents ← USEFUL FOR AGGREGATION
↓ ~5 LSOAs aggregate into
Middle Super Output Area (MSOA11) - ~7,500 residents
↓ Multiple MSOAs per
Borough (oslaua) - ~300,000 residents (33 London boroughs)If going for the tactical approach: Use individual postcodes, optionally note their LSOA
If ambitious/analysing multiple areas: Sample postcodes within LSOAs, aggregate journey metrics by LSOA
Full technical guide: ONS Postcode Products Documentation
Critical Data Handling Notes
You might want to filter to current postcodes only:
# Keep only active postcodes
df_active = df[df['doterm'].isna()].copy()Postcode format for TfL API:
Both SW1A 2AA (with space) and SW1A2AA (without) should work on the TfL API. You can use the pcds column directly.
London borough codes:
All start with E09, ranging from E09000001 (City of London) to E09000033 (Westminster)
Additional Columns (for ambitious students)
| Column | Type | Description | Range/Format | When to Use |
|---|---|---|---|---|
| imd | integer | Index of Multiple Deprivation rank for the LSOA this postcode belongs to | 1 (most deprived LSOA in England) to 32,844 (least deprived) | Test whether deprived neighbourhoods have worse connectivity. ⚠️ Important: This value is the same for ALL postcodes within the same LSOA - you cannot analyse “postcode-level deprivation” |
| osward | string | Electoral Ward code within the borough | Alphanumeric (varies by borough) | Sub-borough analysis. Wards are political/electoral boundaries used for local council elections - smaller than LSOAs but boundaries change frequently |
| ttwa | string | Travel To Work Area code | Alphanumeric geographic code | Natural economic areas where most residents both live and work. London has several TTWAs - useful to validate whether your connectivity analysis aligns with actual commute patterns |
| usertype | integer | Postcode classification | 0 = small user (residential) 1 = large user (business/organisation) |
Filter to residential postcodes (usertype=0) if analysing where people live |
| oac11 | string | 2011 Output Area Classification | Alphanumeric supergroup/group/subgroup codes | Statistical classification of neighbourhood types (e.g., ‘cosmopolitan students’, ‘suburban achievers’). Research ONS OAC methodology if using |
Reference Codes (research required if using)
If you want to explore these columns, you’ll need to research ONS geography documentation:
| Column | Full Name | What You’d Need to Research |
|---|---|---|
| pcd | Postcode (7 char fixed) | Formatting standards |
| pcd2 | Postcode (8 char) | Alternative format |
| dointr | Date of introduction | YYYYMM format, postcode lifecycle |
| doterm | Date of termination | YYYYMM or NULL, active vs terminated |
| oscty | County code | Mostly NULL in London, legacy structure |
| oseast1m | OS Grid Easting | British National Grid coordinate system |
| osnrth1m | OS Grid Northing | Alternative to lat/long, needs conversion |
| ctry | Country | E=England (all London postcodes) |
| rgn | Region code | Former Government Office Regions |
| pcon | Parliamentary Constituency | Westminster MP constituencies |
| ccg | Clinical Commissioning Group | NHS geography (pre-2022 reorganisation) |
| nhser | NHS England Region | Health service administration |
| sicbl | Sub-ICB Location | NHS geography (post-2022, replaced CCGs) |
| bua11 | Built-Up Area 2011 | Continuous urban settlement definition |
| wz11 | Workplace Zone 2011 | Areas with 200-625 workers, for employment statistics |
| pfa | Police Force Area | Policing jurisdiction |
⚠️ These require research: If you want to use any of these columns, you’ll need to spend time on the ONS Geography Portal understanding what they represent and how to interpret them. Most are unnecessary for answering the core connectivity question.
Footnotes
A more recent version of the ONS Postcode Directory (May 2024) is available from the ONS Open Geography Portal, but it contains UK-wide postcodes which is too much data for this assignment. We use the London-specific February 2022 version to keep the dataset manageable.
📚 See the Appendix: ONS Postcode Directory Data Dictionary for essential columns, geographic hierarchy, and data handling notes.↩︎