Understand: Why organisations normalise data into multiple tables
Practice: Schema design, pd.merge(), and basic SQL queries
Why this matters: These skills enable structured data storage and support your ✍️ Mini-Project 2 work, where you can optionally use SQLite for organising TfL and ONS data.
1️⃣ Intro to Databases
The Scenario
If you work for a company, you will discover that they likely already have a lot of data in their internal systems.
You might find data in Excel spreadsheets (which you can easily read into Python using pandas) or convert them to CSV files.
At larger organisations, you will likely find that this operational data is stored in databases.
You also won’t be able to view the contents of a database file with cat because it’s not a plain text file. Internally, databases use data structures more advanced than the ones we learn in this course to store and guarantee data integrity.
🔗 Link: (Advanced) Click here to learn of how one database system (SQLite) stores its data in its internal file format.
Database as a collection of tables
A relational database is a collection of tables connected by relationships.
Tables store data in rows and columns, similar to DataFrames.
We can connect tables through information they share.
(I labelled the relationships in this imaginary diagram just for the sake of clarity. In reality, the type of databases I am talking about don’t allow you to name the relationships.)
Tables are like enhanced DataFrames
Columns in the pandas DataFrame are like columns in the database table.
Pandas DataFrame (movies)
movie_id (int64)
title (object)
rating (float64)
votes (int64)
1
Carmencita
5.7
1335
2
Le clown
5.4
842
3
Pauvre Pierrot
6.2
1971
But in pandas, you can:
add or remove columns at will
change the types of columns anytime
have missing values in any column
rely on row indices instead of enforcing keys (like foreign keys in databases)
But database tables are stricter
You can’t just do anything you want with a database table. You have to follow the rules.
Database table (movies)
movie_id (PK) (INTEGER)
title (TEXT NOT NULL)
average_rating (REAL)
num_votes (INTEGER NOT NULL)
1
Carmencita
5.7
1335
2
Le clown
5.4
842
3
Pauvre Pierrot
6.2
1971
Database table (ratings)
movie_id (PK, FK) (INTEGER)
average_rating (REAL)
num_votes (INTEGER)
1
5.7
1335
2
5.4
842
3
6.2
1971
You need to know that:
tables must be defined before you insert data, and changing them later is harder
a column can only have missing values if it is declared NULL when the table is created
tables have primary keys that uniquely identify each row (PK = Primary Key)
tables can have foreign keys that reference other tables (FK = Foreign Key)
2️⃣ Reading from databases (IMDb exploration)
There are many databases out there. We’ll use one called SQLite because it’s free, lightweight, and easy to use.
What is IMDb?
IMDb (Internet Movie Database) powers millions of lookups.
We’re examining the real production schema, not a toy example.
Same normalisation principles you’ll apply to TfL + ONS data.
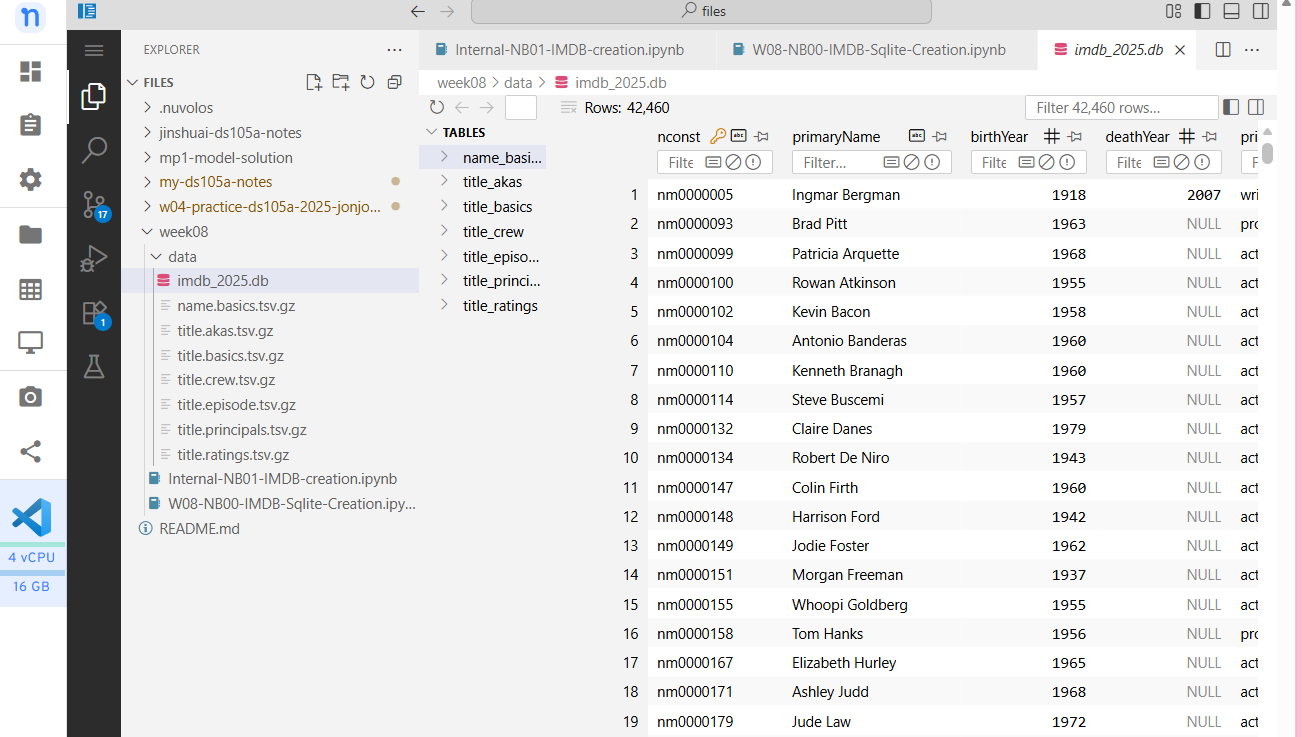
To keep VS Code responsive we created imdb_2025.db, a curated slice of titles whose endYear = 2025.
You should see a copy of it on your workspace at /files/week08/data/imdb_2025.db.
The IMDB homepage as of 20 Nov 2025
Explore a database visually (1/2)
Install the SQLite Viewer extension in VS Code.
Access VS Code on Nuvolos
Click on the Extensions icon in the left sidebar
Search for “SQLite Viewer”
Click on the “Install” button
Explore a database visually (2/2)
Open the database file in the SQLite Viewer.
Go back to the file explorer in VS Code
Navigate to imdb_2025.db inside your Week 08 data folder
Right-click the file and select “Open with SQLite Viewer”
You should see the database file open in the SQLite Viewer
Explore database using Python
From within /files/week08/ you will find a W08-NB01-Lecture notebook which has code like the one below. We need to add the sqlite3 library to the notebook.
# This must be added to the top of the notebook# SQLite3 is a library for interacting with SQLite databases# It already comes with Python, no need to pip install anythingimport sqlite3
Then we can connect to the database and read the first 5 rows of the title_basics table:
conn = sqlite3.connect("./data/imdb_2025.db")# This reads the first 5 rows of the title_basics tablepd.read_sql("SELECT * FROM title_basics LIMIT 5;", conn)
(Alt) Connect via Nuvolos Tables
Note from Jon: Nuvolos has this particular feature where it lets us all access the same database. Listen closely during the lecture to see if this is enabled. It if is, you can use the code below to connect to the database.
from nuvolos import get_connectionimport pandas as pdconn = get_connection()pd.read_sql("SELECT * FROM title_basics LIMIT 5;", conn)
The Nuvolos version (if available) is much bigger than the imdb_2025.db file you have on your workspace and has all the historical data.
SQL Basics Preview
SQL stands for Structured Query Language. It is the language used to query databases and the inspiration for many of pandas’s DataFrame methods.
Tomorrow’s lab builds SQL skills progressively:
SELECT specific columns
WHERE to filter rows
COUNT and COUNT(DISTINCT) for aggregations
GROUP BY to split-apply-combine
Combine everything to recreate plot_df
Today, we will use the accompanying notebook to explore these patterns. Listen carefully during the lecture.
Explore the Structure
IMDb has several tables. Look at a few:
# Titles and basic informationpd.read_sql("SELECT * FROM title_basics LIMIT 5", con)# Ratings for those titlespd.read_sql("SELECT * FROM title_ratings LIMIT 5", con)# Actors and their rolespd.read_sql("SELECT * FROM title_principals LIMIT 5", con)# Names of actorspd.read_sql("SELECT * FROM name_basics LIMIT 5", con)
Data split across multiple tables.
How IMDb Tables Connect
Look at tconst. It appears in both title_basics and title_ratings.
title_basics:
tconst
primaryTitle
tt0000001
Carmencita
tt0000002
Le clown
title_ratings:
tconst
averageRating
tt0000001
5.7
tt0000002
5.4
One title has one rating. Connected by tconst.
ORDER BY + LIMIT (rankings)
How can I get the top 10 highest rated popular (100k+ votes) titles?
on="tconst" tells pandas which column matches between tables.
how="inner" keeps only the rows that exist in both tables.
Result: ratings + human-readable title in one DataFrame.
The output
This is more like how we want to see the data.
tconst
averageRating
numVotes
primaryTitle
titleType
0
tt4574334
8.6
1504453
Stranger Things
tvSeries
1
tt9253284
8.6
255970
Andor
tvSeries
2
tt7221388
8.4
237080
Cobra Kai
tvSeries
3
tt5834204
8.3
290989
The Handmaid’s Tale
tvSeries
4
tt31806037
8.1
252695
Adolescence
tvMiniSeries
5
tt10919420
8.0
727012
Squid Game
tvSeries
6
tt1869454
8.0
121327
Good Omens
tvSeries
7
tt1751634
7.6
204936
The Sandman
tvSeries
8
tt7335184
7.6
354235
You
tvSeries
9
tt7462410
7.2
161539
The Wheel of Time
tvSeries
Merge parameters cheat sheet
Parameter
Meaning
left, right
DataFrames you want to combine
on
Column present in both DataFrames
left_on, right_on
Use when join column names differ
how
"inner", "left", "right", "outer"
suffixes
Rename overlapping columns (('_rating', '_info'))
This is the same logic you’ll use for MP2’s TfL + ONS merges if you choose to use a database.
SQL JOIN equivalent
Everything above can be run directly inside SQLite as well:
SELECT b.primaryTitle, r.averageRating, r.numVotesFROM title_ratings AS rJOIN title_basics AS bON r.tconst = b.tconstWHERE r.numVotes >100000ORDERBY r.averageRating DESCLIMIT10;
pd.read_sql() will return the merged DataFrame without needing pandas-side merge().
5️⃣ Creating a SQLite Database
You do not have to build your own database for ✍️ Mini Project 2, but you will for the 📦 Final Project. These slides demonstrate part of the process of creating a SQLite database.
How these tables were created
In Part 1 I showed how we describe a table, what we call the schema.
If you decide to define your own tables (optional for ✍️ Mini Project 2, required later), this is exactly how the IMDb schema looks in SQL:
Once those statements exist you can write them to a .db file like this:
conn = sqlite3.connect("imdb_2025.db")create_query ="""CREATE TABLE ... statements here..."""# Do it for each tableconn.execute(create_query)# Then close the connectionconn.close()
Populating IMDb Tables
If this data was in DataFrames, you’d populate like this: