🗓️ Week 05:
Support Vector Machines (SVM)
Non-linear algorithms
10/28/22
Building Intuition: the Hyperplane
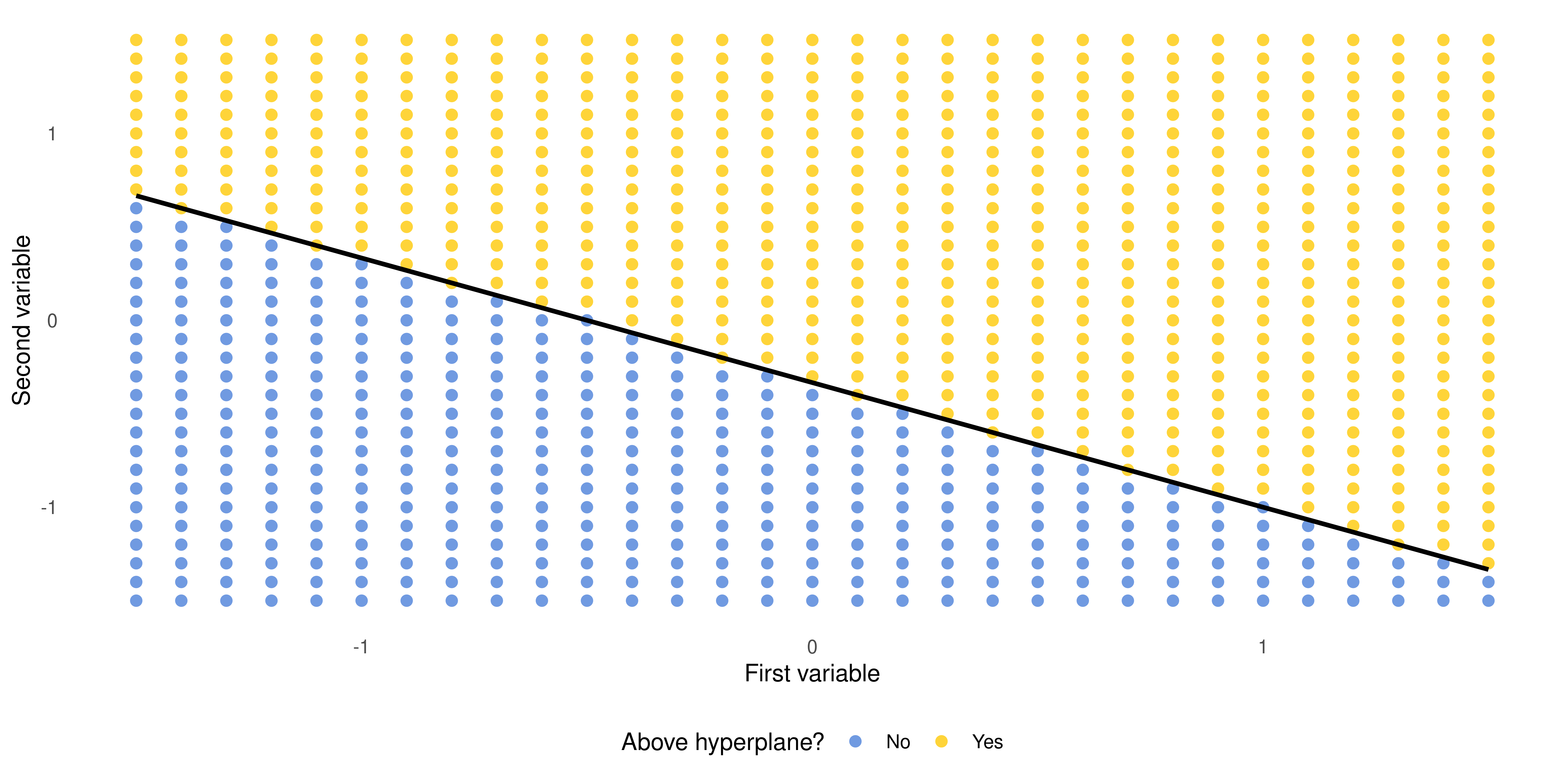
Building Intuition: the Hyperplane (cont.)
When \(1 + 2x_1 + 3x_2 < 0\)
Building Intuition: the Hyperplane (cont.)
When \(1 + 2x_1 + 3x_2 > 0\)

Building Intuition: the Hyperplane (cont.)
When \(1 + 2x_1 + 3x_2 = 0\)

The Maximal Marginal Classifier
The linearly separable case:
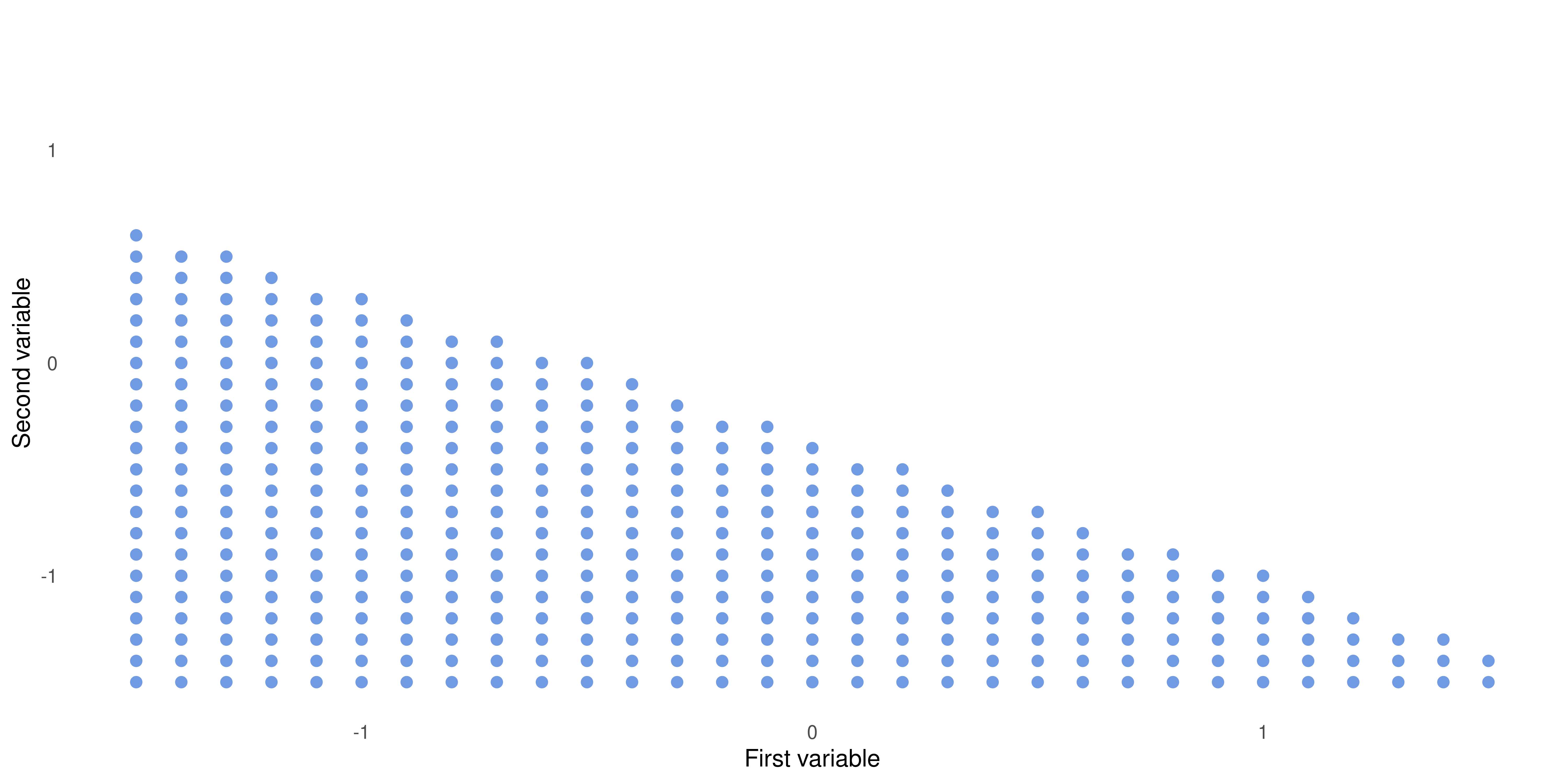
Identifying support vectors
The SV’s represent the so-called support vectors:

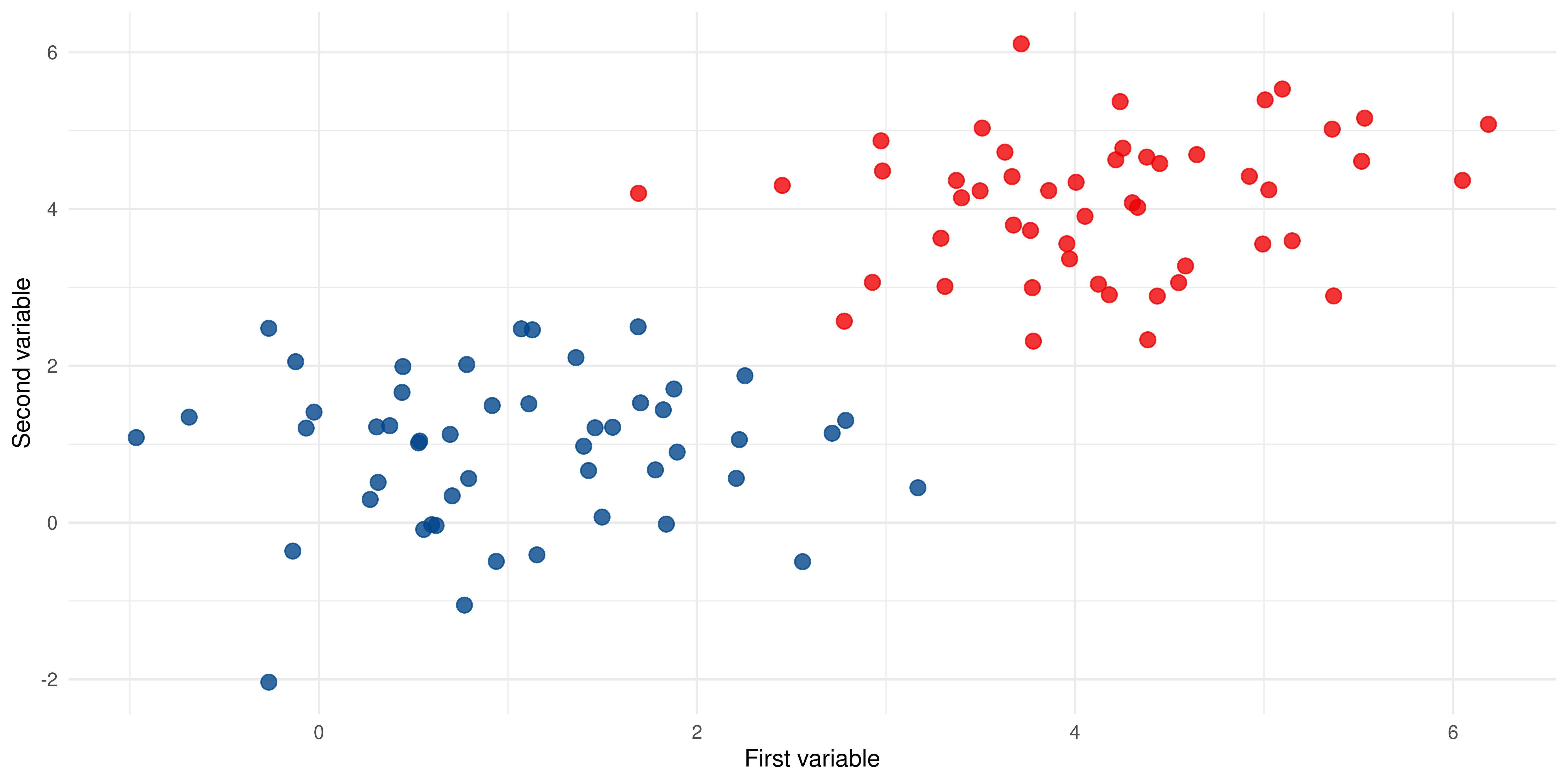
When data is not linearly separable
Suppose we have a case that is not linearly separable like this. We have two classes but class 1 is “sandwiched” in between class 2.
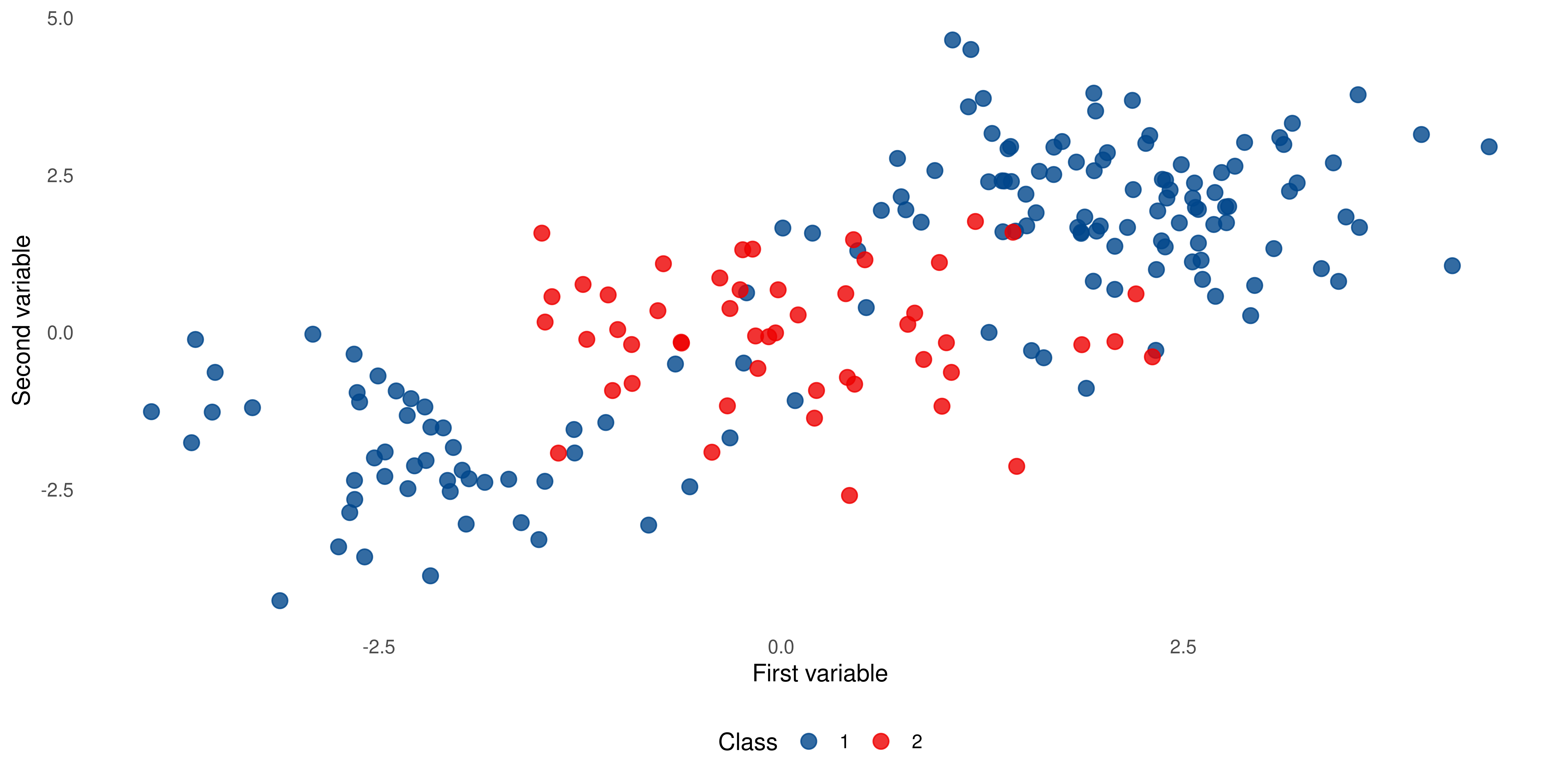
SVM with Linear Kernel

SVM with Polynomial Kernel
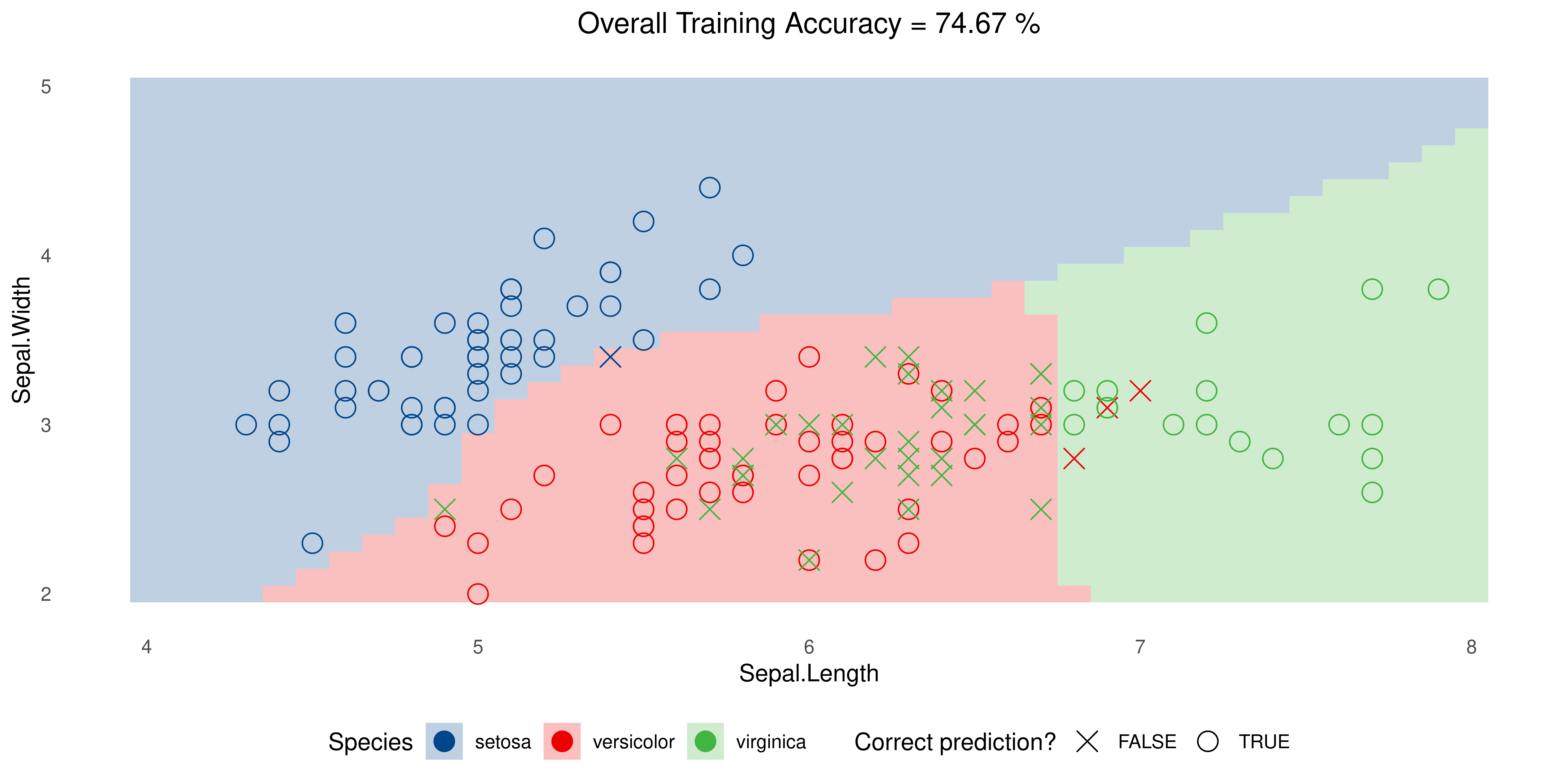
SVM with Sigmoid Kernel
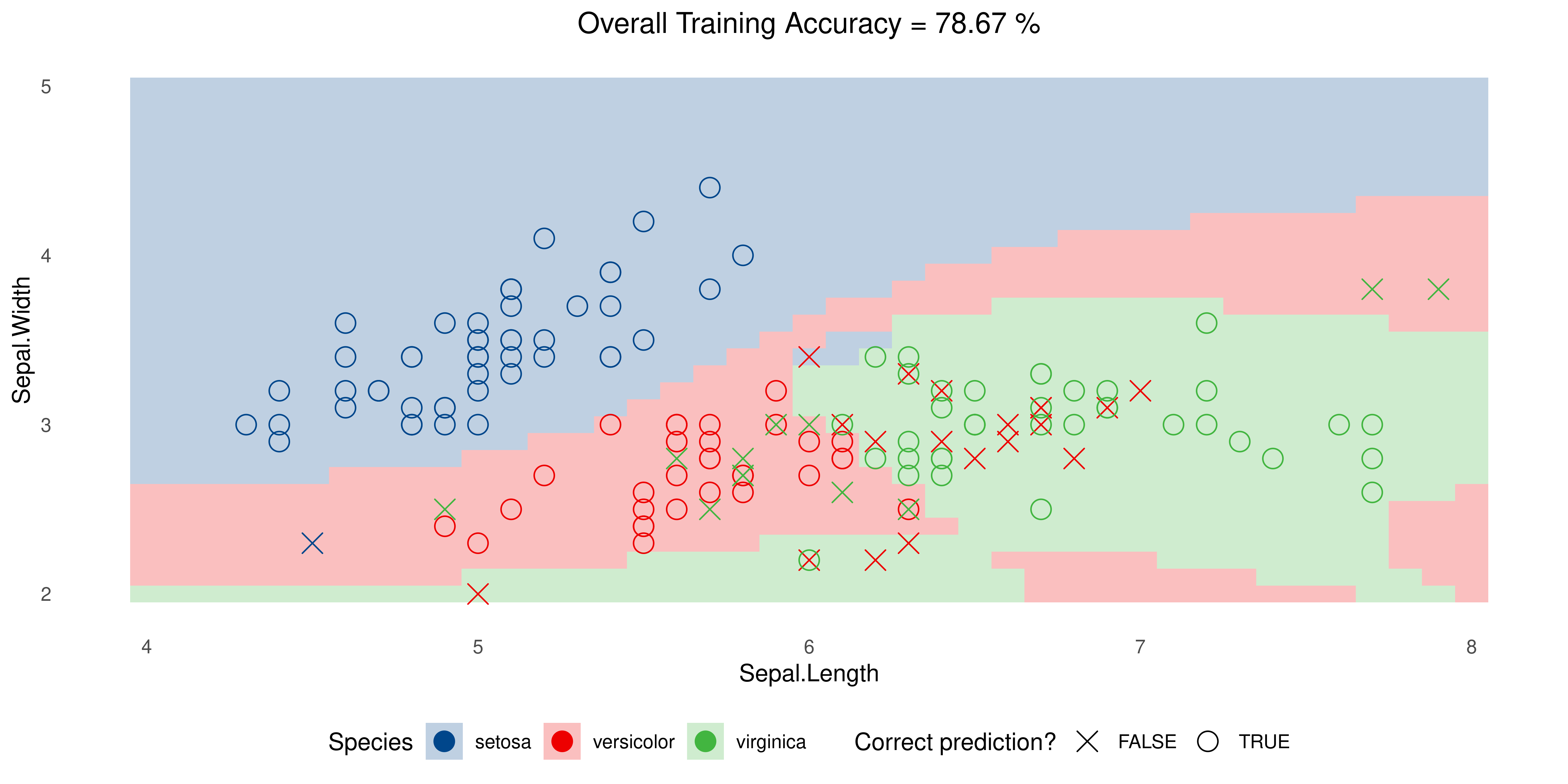
SVM with Radial Kernel
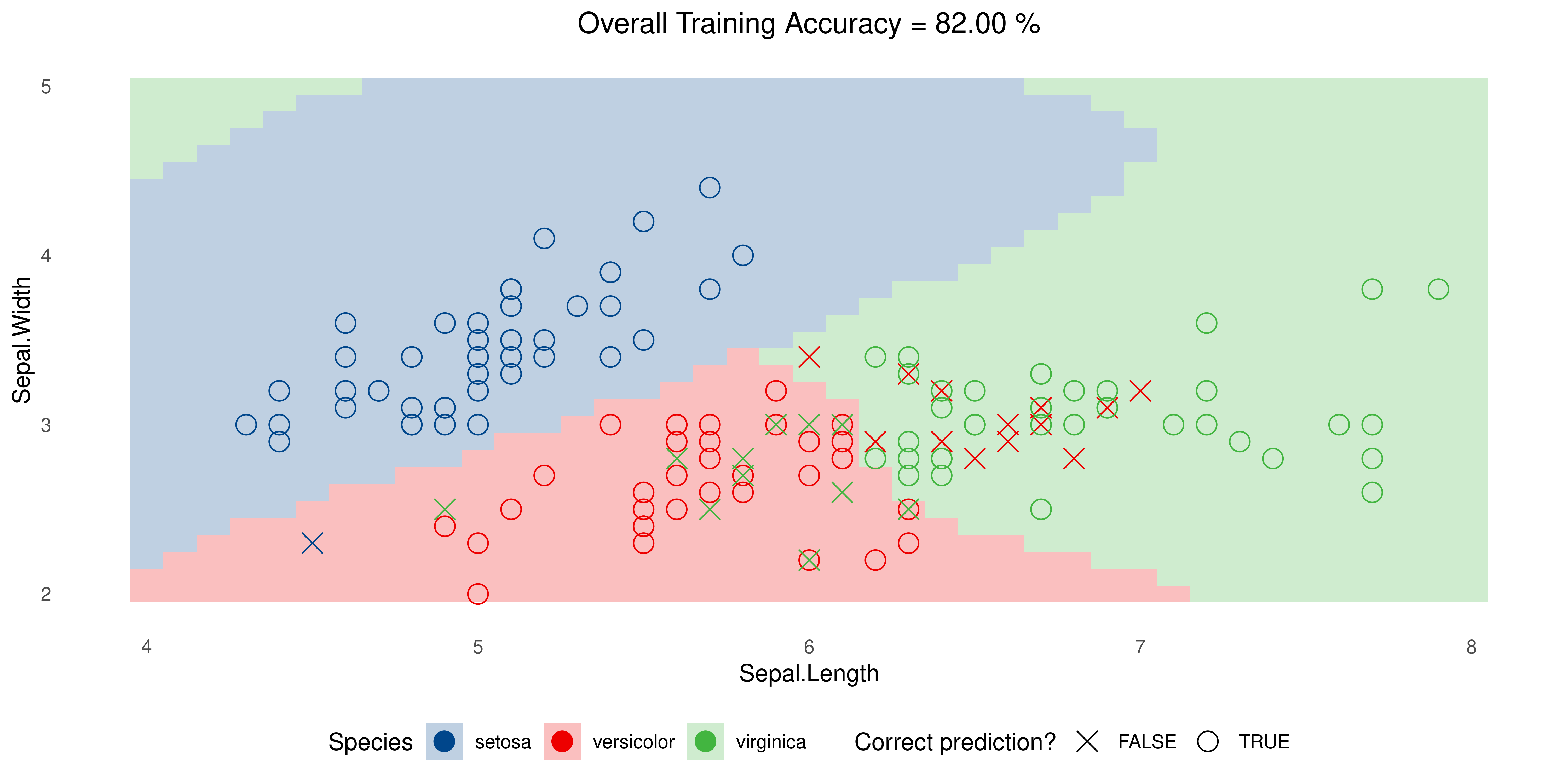
Simple model on training set
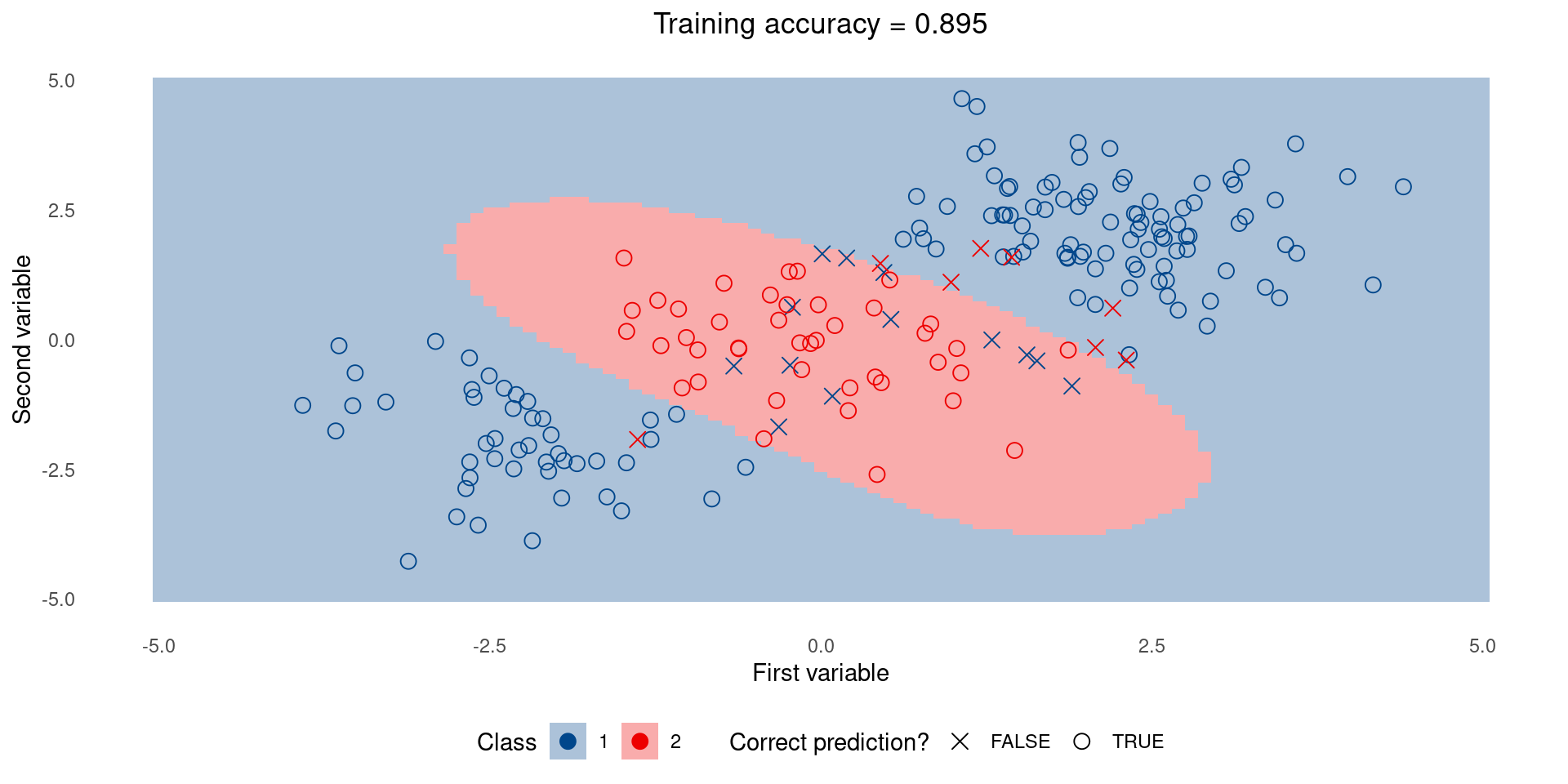
Complex model on training set
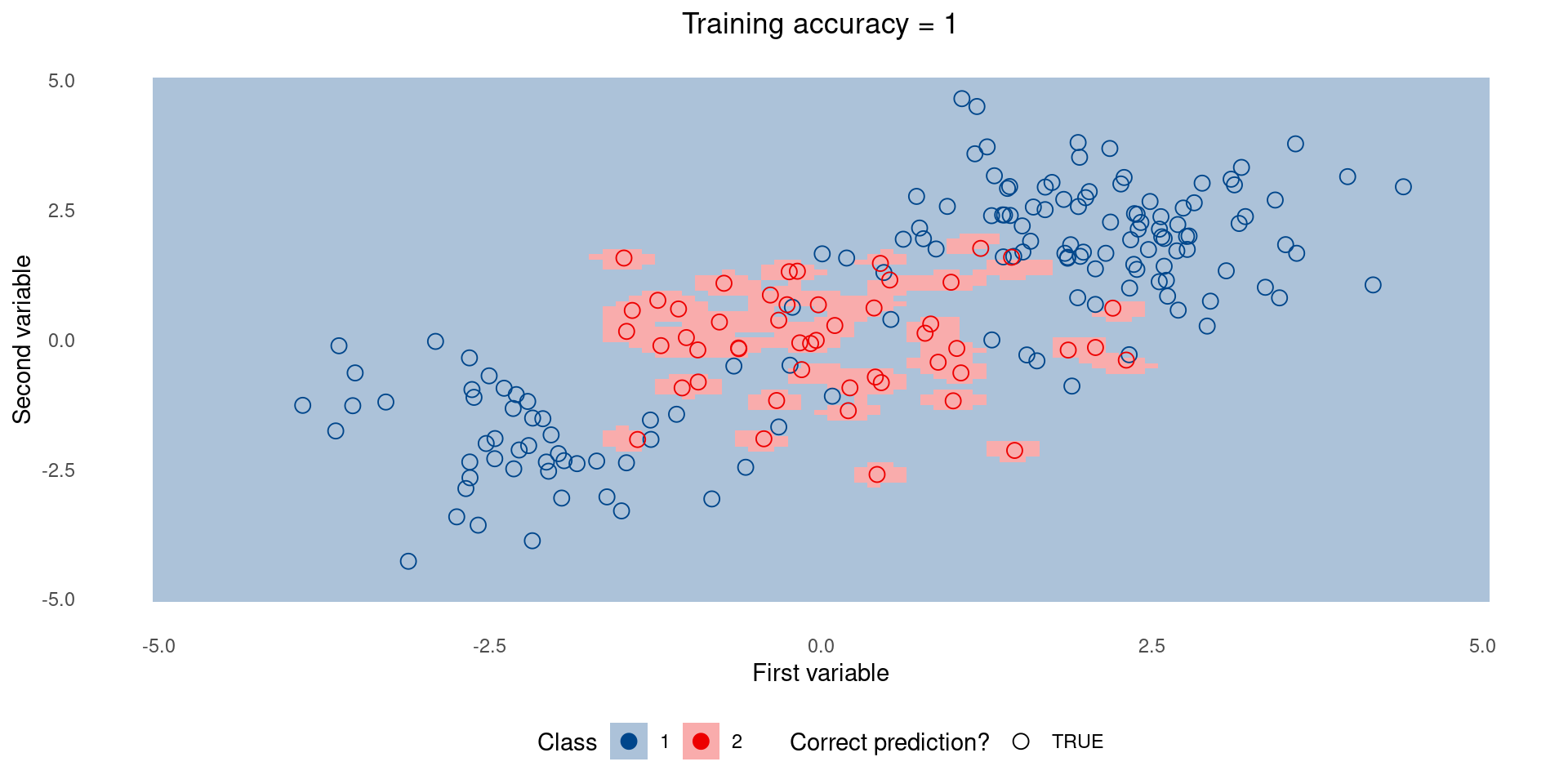
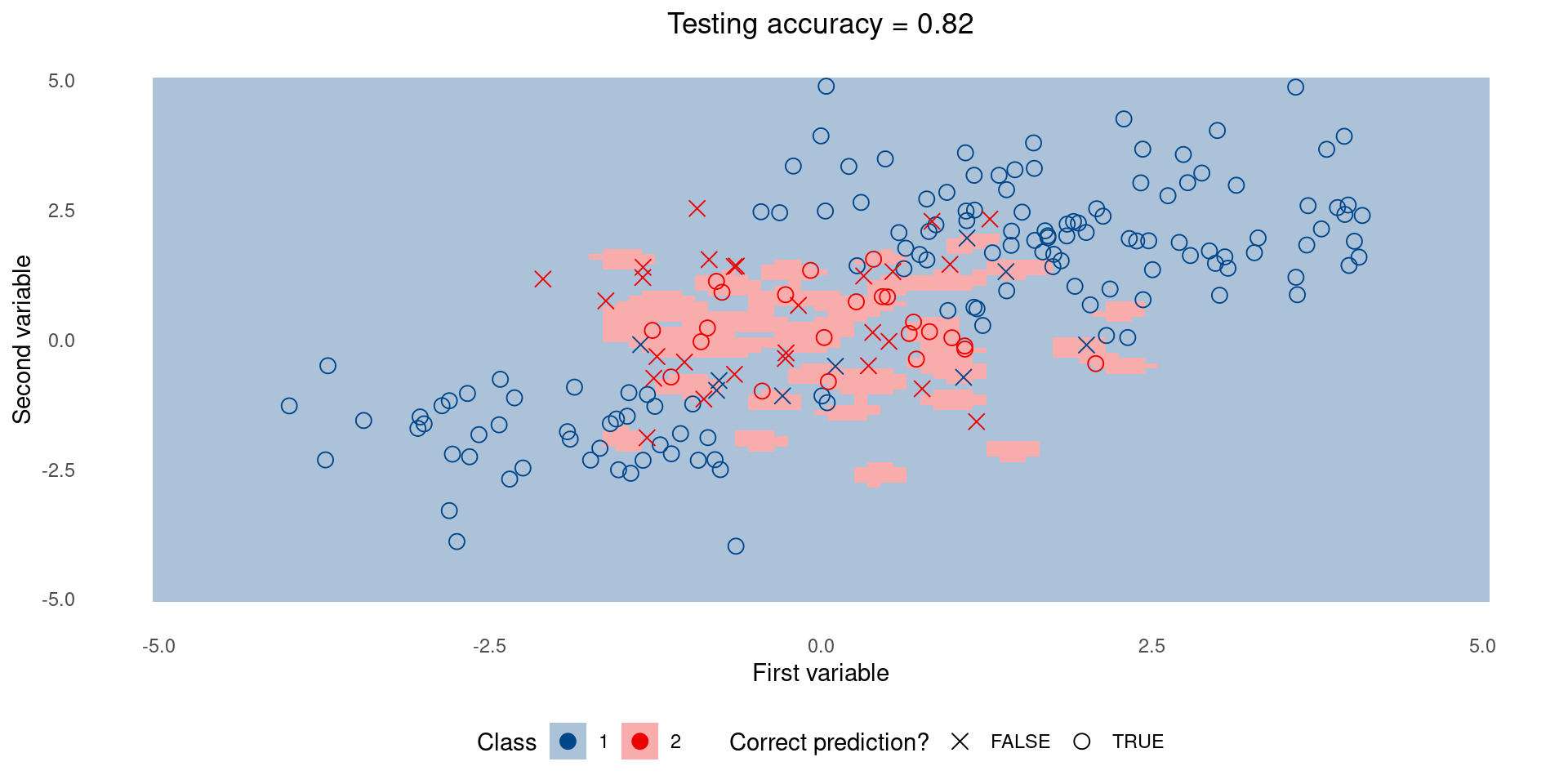
Simple model on test set

Complex model on test set
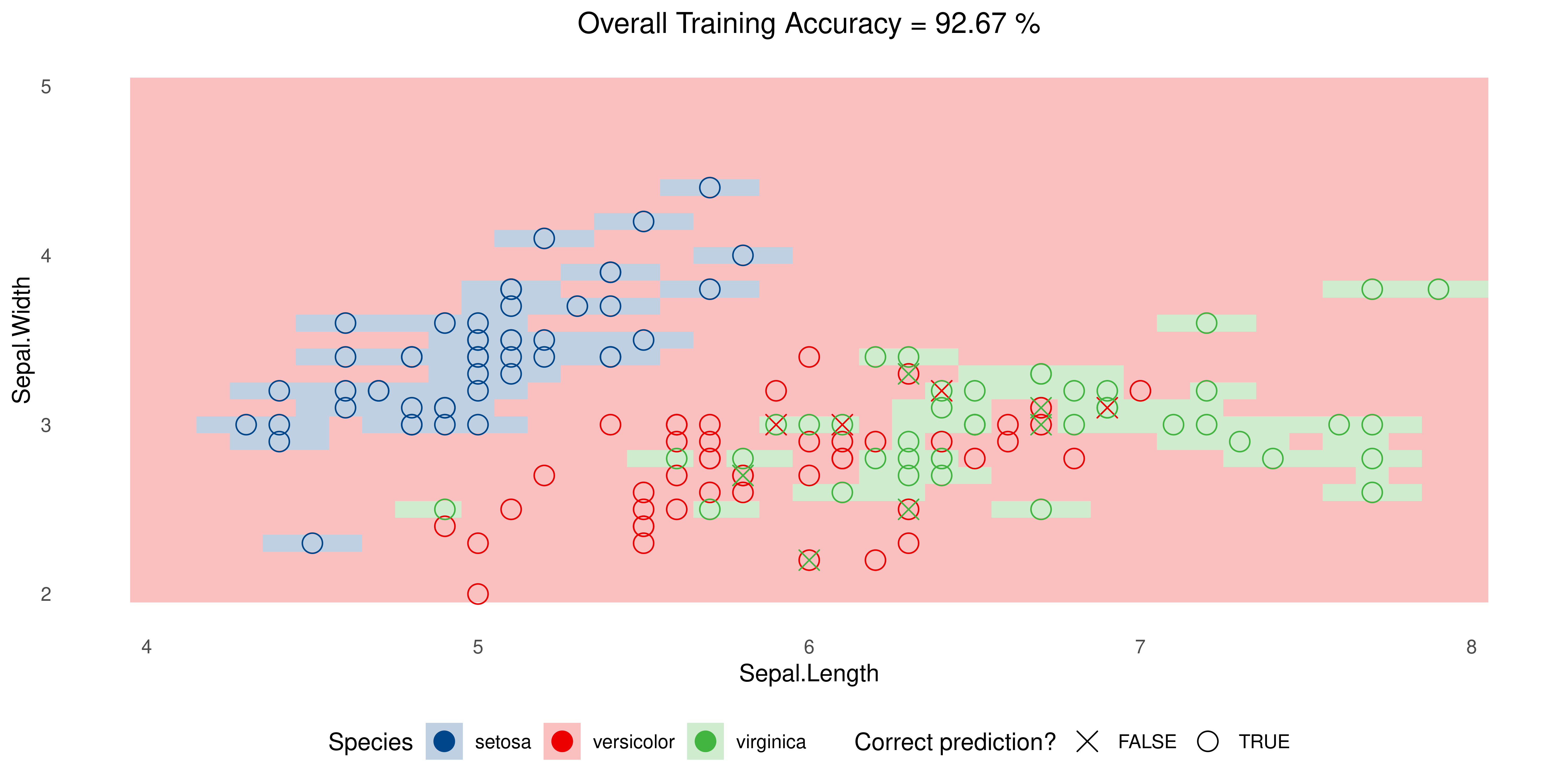
Back to iris
SVM with Radial Kernel but tweaking parameters, namely cost and gamma:
Thank you!

James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2021. An Introduction to Statistical Learning: With Applications in R. Second edition. Springer Texts in Statistics. New York NY: Springer. https://www.statlearning.com/.