🗓️ Week 03
Classifiers - Part I
DS202 Data Science for Social Scientists
10/14/22
Why can’t I use linear regression?
What if I just coded each category as a number?
\[ Y = \begin{cases} 1 &\text{if}~\color{brown}{brown},\\ 2 &\text{if}~\color{blue}{blue},\\ 3 &\text{if}~\color{green}{green}. \end{cases} \]
What could go wrong?

How would you interpret a particular prediction if your model returned:
- \(\hat{y} = ~~1.5\) or
- \(\hat{y} = ~~0.1\) or
- \(\hat{y} = 20.0\)?
More on Classification
- Often we are more interested in estimating the probabilities that \(X\) belongs to each category in \(\mathcal{C}\).
- For example, it is sometimes more valuable to have an estimate of the probability that an insurance claim is fraudulent, than a classification fraudulent or not.

- A successful gambling strategy, for instance, requires placing bets on outcomes to which you believe the bookmakers have assigned incorrect probabilities. Knowing the most likely outcome is not enough!

Note
Statistical models for ordinal response, when sets are discrete but have an order, are outside the scope of this course. Should you need to create models for ordinal variables, consult “ordinal logistic regression”. A good reference about this is (Agresti 2019, chap. 6).
Speaking of Probabilities…
For our purposes:
- Probabilities are numbers between 0 and 1
- The sum of all possible outcomes of an event must sum to 1.
- It is useful to think of things as probabilities
Note
💡 Although there is no such thing as “a probability of \(120\%\)” or “a probability of \(-23\%\)”, you could still use this language to refer to increase or decrease in an outcome.
The Logistic Regression model
Consider a binary response:
\[ Y = \begin{cases} 0 \\ 1 \end{cases} \]
We model the probability that \(Y = 1\) using the logistic function (aka. sigmoid curve):
\[ Pr(Y = 1|X) = p(X) = \frac{e^{\beta_0 + \beta_1X}}{1 + e^{\beta_0 + \beta_1 X}} \]

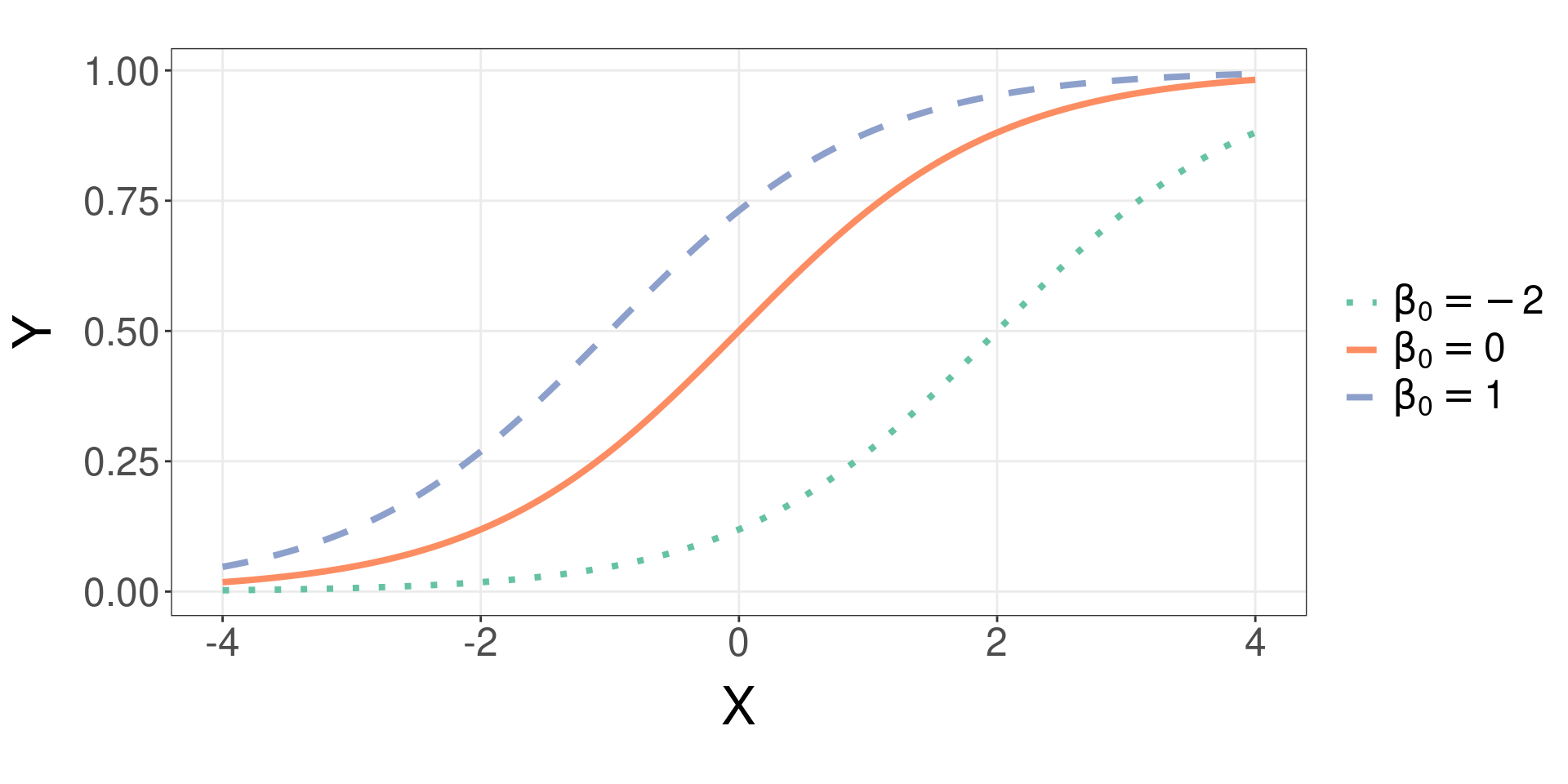
The Logistic function
- Changing \(\beta_0\) while keeping \(\beta_1 = 1\):
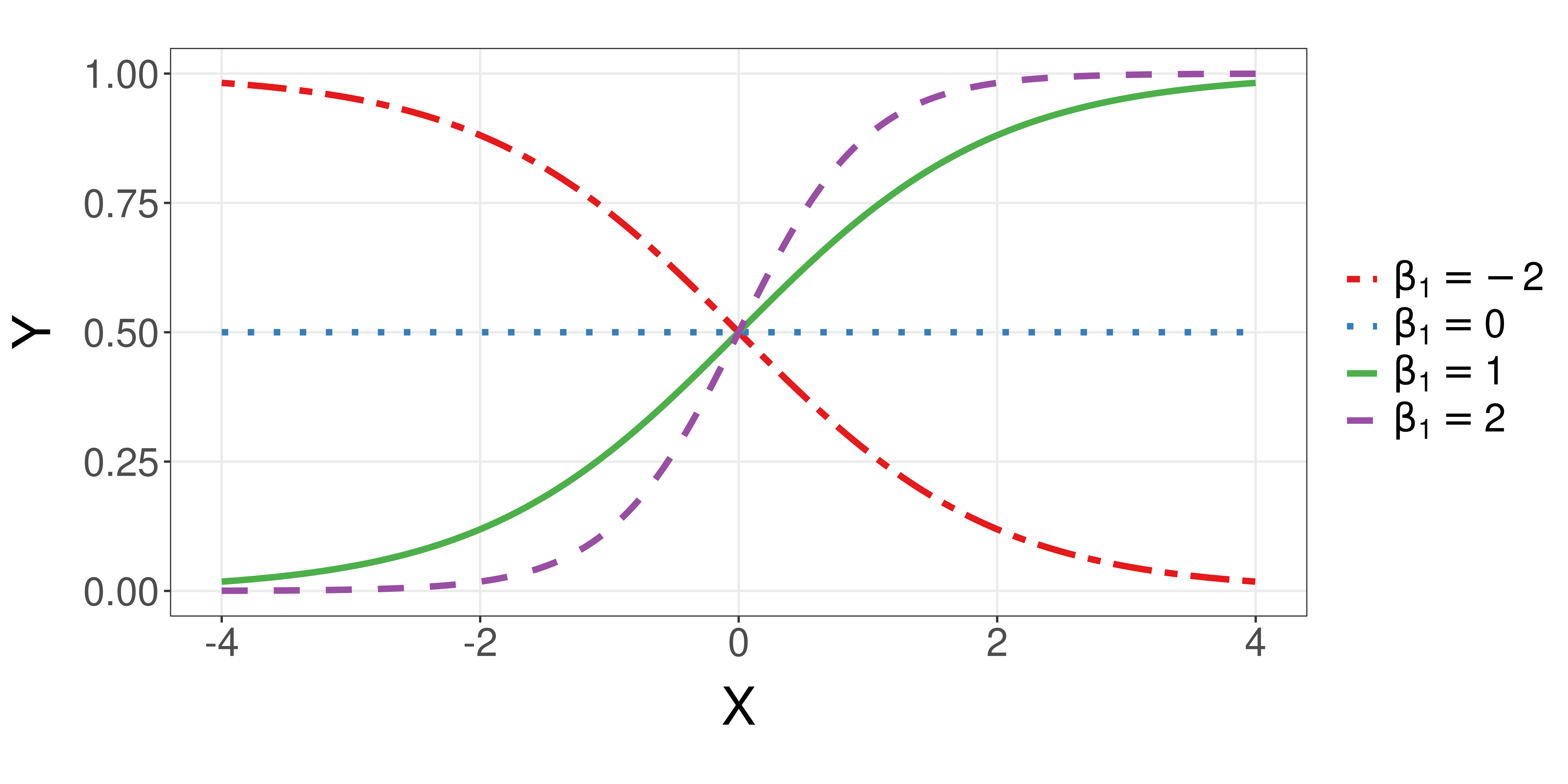
The Logistic function (cont.)
- Keep \(\beta_0 = 0\) but vary \(\beta_1\):
Solutions to MLE
- MLE is much more difficult to solve than the least squares formulations.
- Most solutions rely on a variant of the Hill Climbing algorithm

How do you find the latitude and longitude of a mountain peak if you can’t see very far?
- Start somewhere.
- Look around for the best way to go up.
- Go a small distance in that direction.
- Look around for the best way to go up.
- Go a small distance in that direction.
- \(\cdots\)
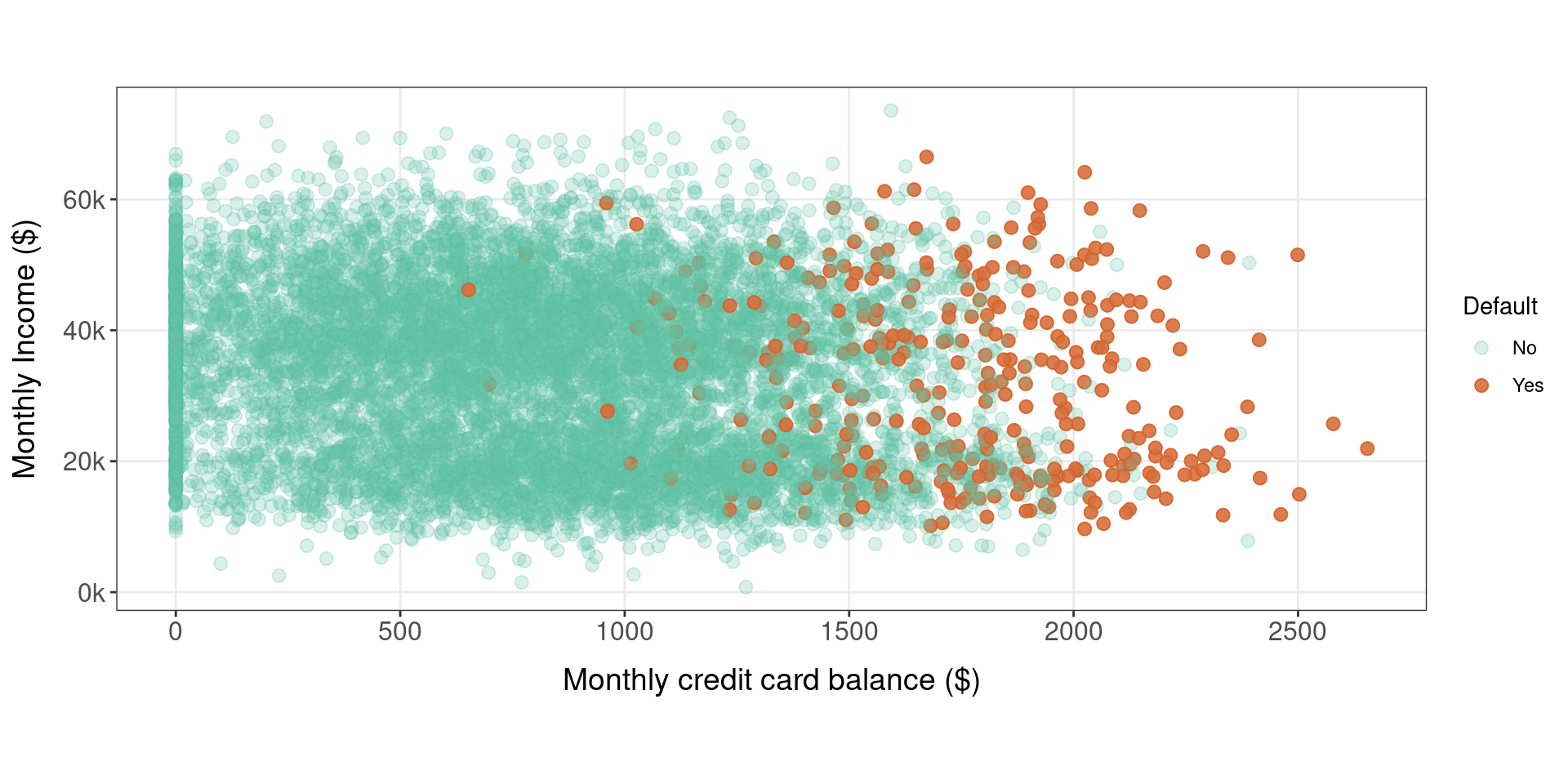
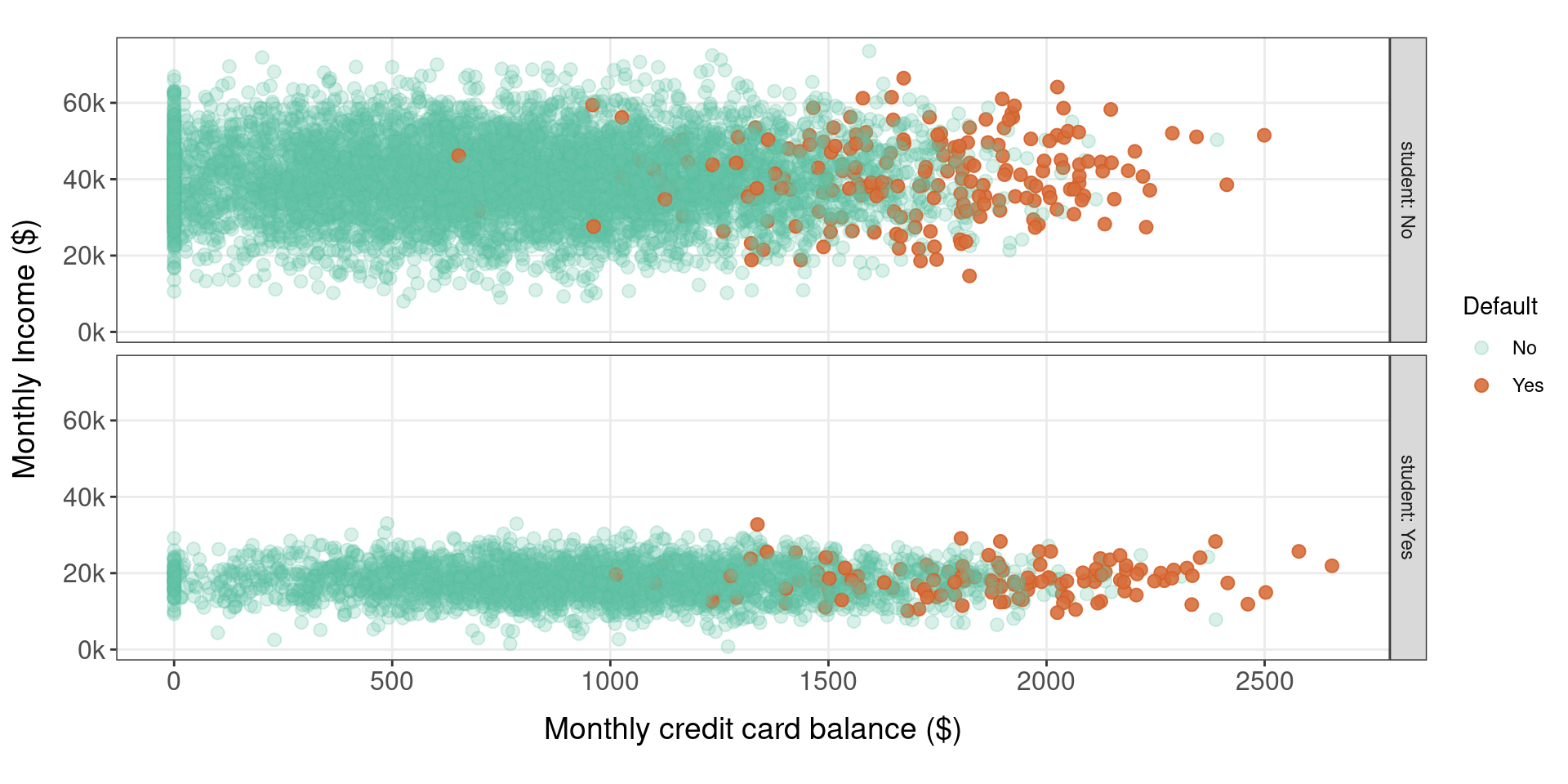
Who is more likely to default?
Does it matter if customer is a student?
References
