🗓️ Week 01
Overview of core concepts
DS202 Data Science for Social Scientists
9/30/22
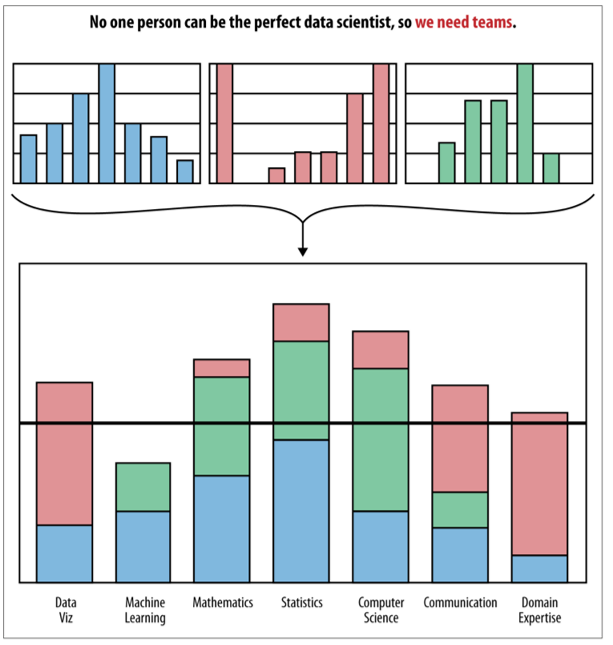
The mythical unicorn 🦄

knows everything about statistics
able to communicate insights perfectly
fully understands businesses like no one
is a fluent computer programmer
In reality…
We are all jugglers 🤹
- Everyone brings a different skill set.
- We need multi-disciplinary teams.
- Good data scientists know a bit of everything.
- Not fluent in all things
- Understands their strenghts and weaknessess
- They know when and where to interface with others
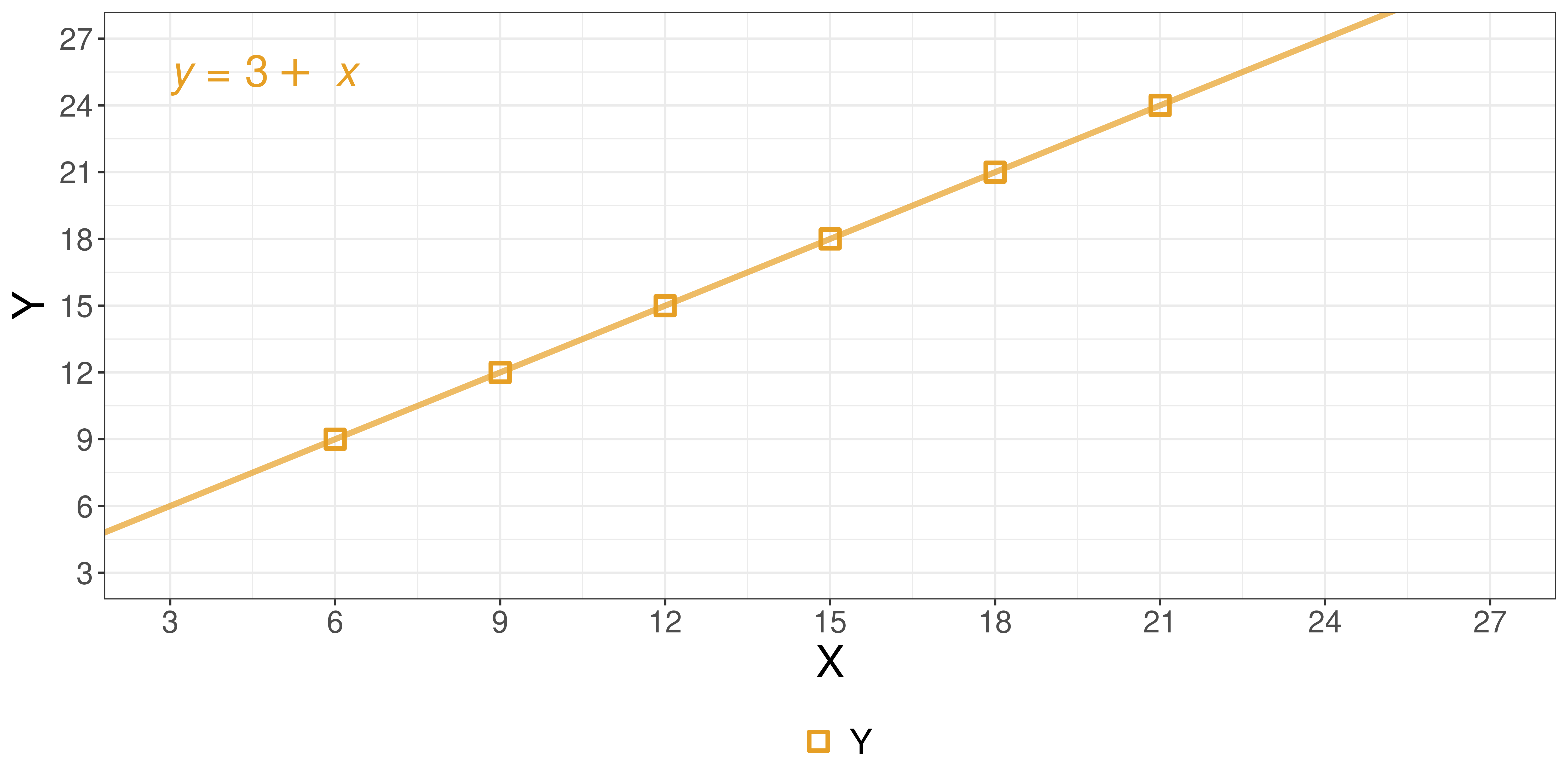
What does it mean to learn something?

Visualizing the data
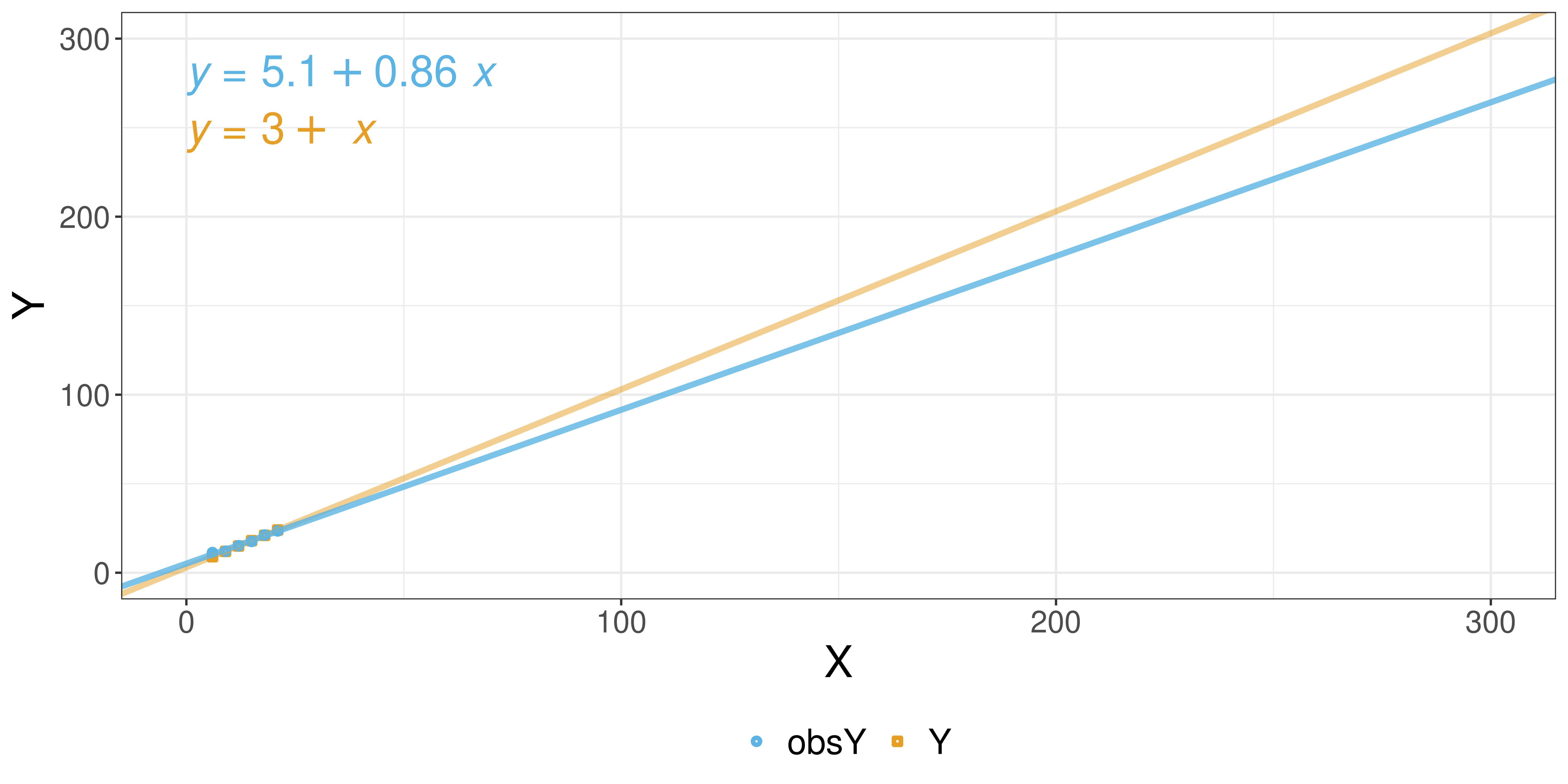
Visualizing the data (w/ noise)
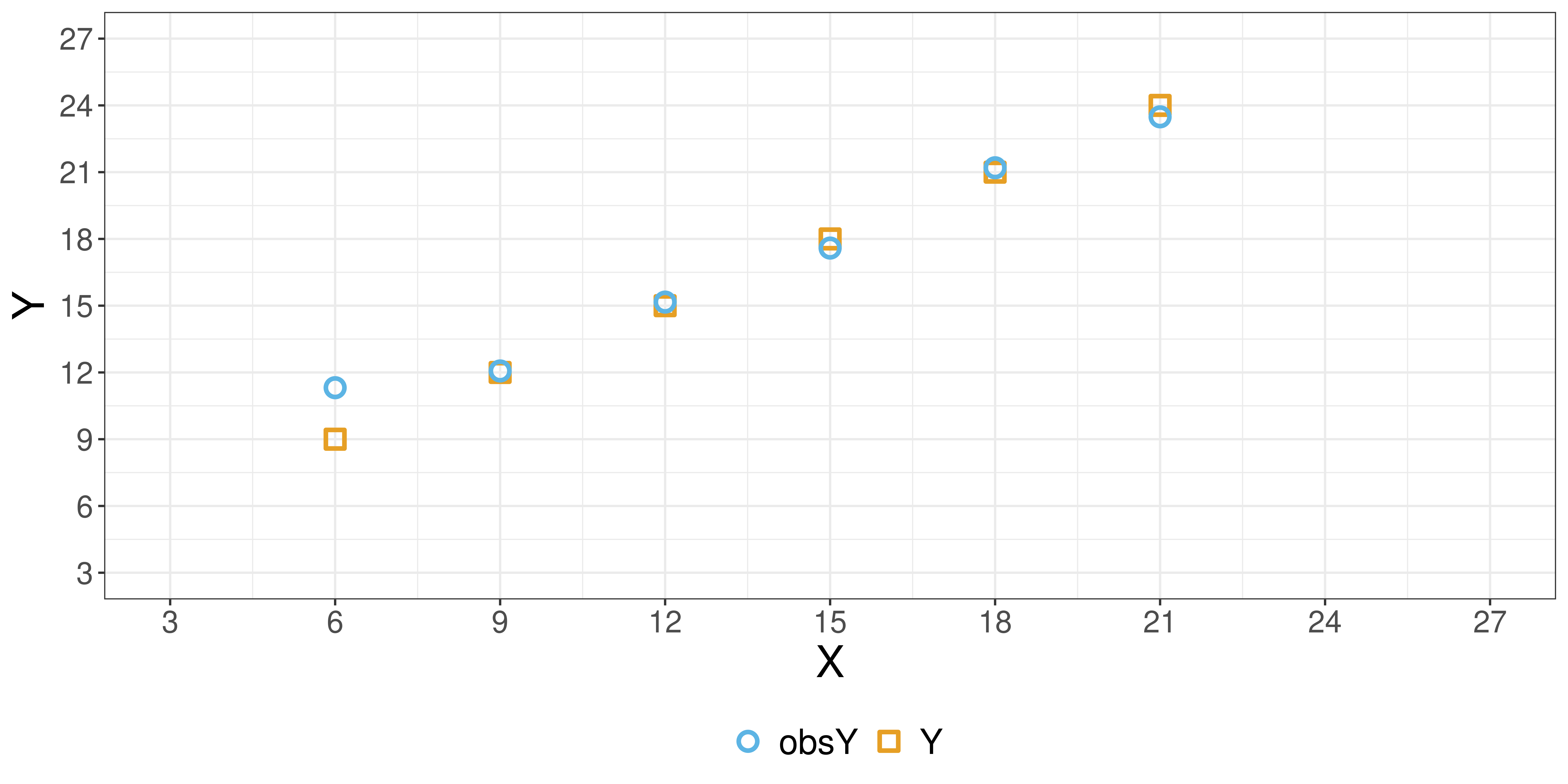
Visualizing the data (w/ noise)
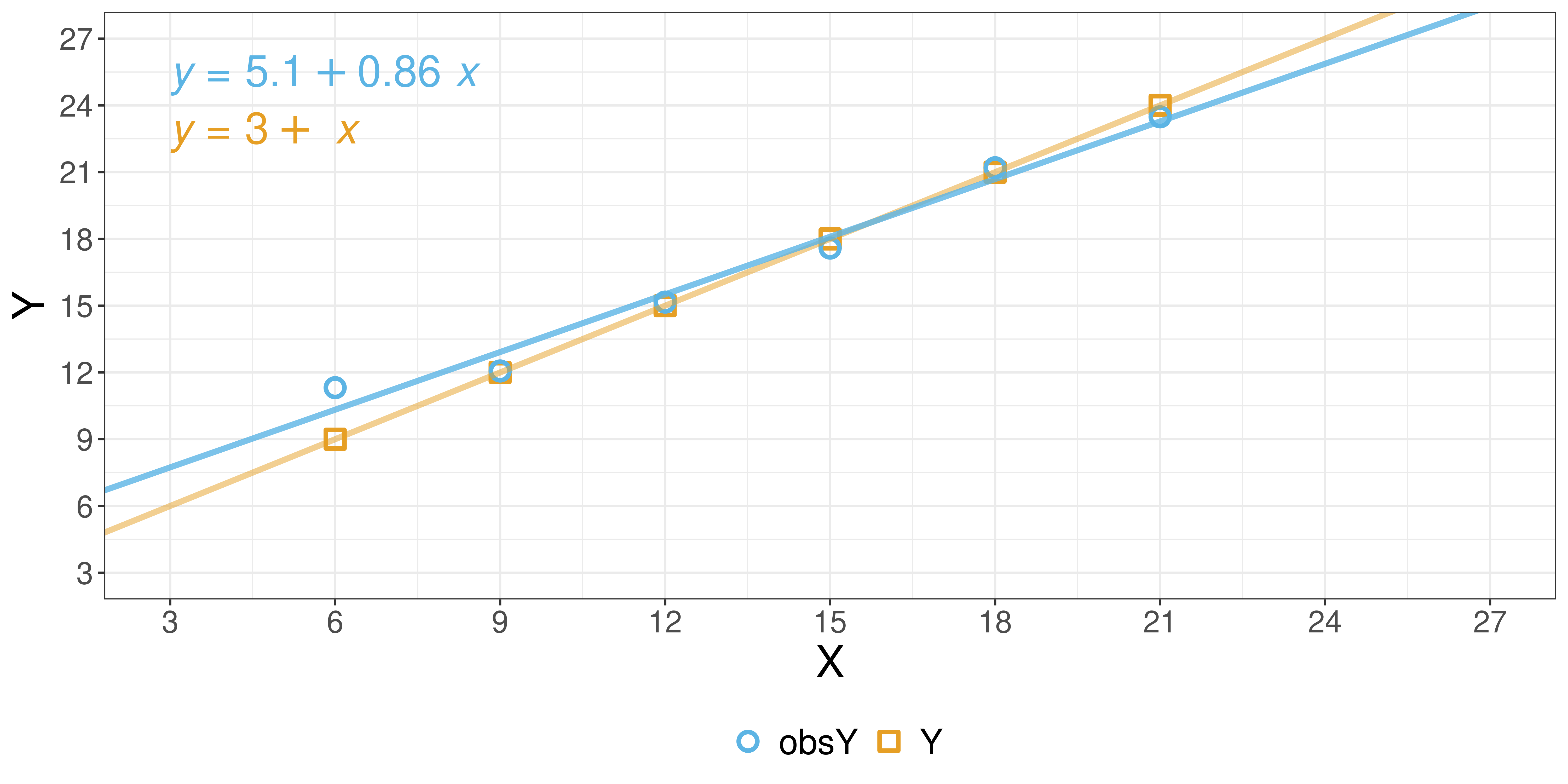
Visualizing the data (w/ noise)
What’s Next?
- We will introduce different measures of error and goodness-of-fit throughout this course.
- Next week we will cover Simple and Multiple Linear Regression
- Join our
![]() Slack group if you haven’t done so yet.
Slack group if you haven’t done so yet. - Use the time before our first lab to revisit basic R programming skills.
- Head over to the 🔖 Week 01 - Appendix page for:
- Indicative & recommended reading
- Programming Resources
References
Davenport, Thomas. 2020. “Beyond Unicorns: Educating, Classifying, and Certifying Business Data Scientists.” Harvard Data Science Review 2 (2). https://doi.org/10.1162/99608f92.55546b4a.
Schutt, Rachel, and Cathy O’Neil. 2013. Doing Data Science. First edition. Beijing ; Sebastopol: O’Reilly Media. https://ebookcentral.proquest.com/lib/londonschoolecons/detail.action?docID=1465965.
Shah, Chirag. 2020. A Hands-on Introduction to Data Science. Cambridge, United Kingdom ; New York, NY, USA: Cambridge University Press. https://librarysearch.lse.ac.uk/permalink/f/1n2k4al/TN_cdi_askewsholts_vlebooks_9781108673907.
Shmueli, Galit. 2010. “To Explain or to Predict?” Statistical Science 25 (3). https://doi.org/10.1214/10-STS330.
