🗓️ Week 07
First Steps with Unstructured Data: PDF Extraction and Word Embeddings
DS205 – Advanced Data Manipulation
03 Mar 2025
1️⃣ Key Terminology: The Data Structure Spectrum
10:03 – 10:15
The Structure Spectrum
Structured
Databases, CSV files
Semi-structured
JSON, XML, HTML
Unstructured
Text, images, audio
Interactive Sorting Activity
Sort these data sources from most structured to least structured:
SQL database
JSON API response
HTML webpage
Plain text document
Social media post
The Data Continuum: Our Journey
Weeks 1-3
Structured data
APIs
Weeks 4-5
Semi-structured data
Web scraping
This Week
Unstructured data
Text analysis
2️⃣ Guest Presentation
Terry’s lived experience with ChatLSE - A Real-World RAG System
(Proof of concept, not production ready)
10:15 – 10:50
🍵 Break
10:50 – 11:00
3️⃣ From Raw Text to NLP-Ready Data
11:00 – 11:15
Core NLP Preprocessing Steps
Tokenization
- Breaking text into meaningful units (tokens)
- Words, subwords, characters
- Handling special cases
- Preserving meaning
Normalization
- Case standardization
- Stemming word variants (e.g. “running”, “runner”, “runners”)
- Lemmatization (e.g. “running” -> “run”)
- Handling abbreviations (e.g. “EU” -> “European Union”)
Stop Word Removal
- Filtering common words
- Reducing noise
- Domain-specific filtering
- Improving signal
Text Preprocessing: Tokenization
Original Text
“The EU’s 2030 climate target requires a 55% reduction in GHG emissions.”
Text Preprocessing: Normalization
After Normalization
- Requires some domain expertise
- Converts to lowercase
- Standardizes abbreviations
- Resolves common variations
Text Preprocessing: Stop Word Removal
Original Text
“We are committed to achieving net-zero emissions by 2050 through the implementation of renewable energy solutions.”
Stop Words
Tokenization Demo
Notebook Demo: Section 1 & 2
- Different tokenization approaches
- Example with climate text
- Pros and cons of each approach
Climate Domain Challenges
Specialized Vocabulary
- “Scope 3 emissions”
- “Net-zero commitments”
- “Carbon neutrality”
- “Paris Agreement targets”
Mixed Content
- Numerical data within text
- Temporal information
- Target dates
- Commitment timelines
4️⃣ Word Embeddings: From Words to Vectors
11:15 – 11:40
Traditional Text Representations (Bag-of-Words)
Original documents:
Doc 1: "Climate change is a global challenge."Doc 2: "Climate impacts are already visible."Doc 3: "We need climate action now."- Simple word frequency counts
- Loses word order and context
- “Climate change is real” and “Real change is climate” are identical
- Misses semantic relationships between terms
Document-term matrix:
| Document | climate | change | global | challenge | impacts | action | … |
|---|---|---|---|---|---|---|---|
| Doc 1 | 1 | 1 | 1 | 1 | 0 | 0 | … |
| Doc 2 | 1 | 0 | 0 | 0 | 1 | 0 | … |
| Doc 3 | 1 | 0 | 0 | 0 | 0 | 1 | … |
Traditional Text Representations (TF-IDF)
Term Frequency-Inverse Document Frequency: Weighting Words by Importance
Same documents:
Doc 1: "Climate change is a global challenge."Doc 2: "Climate impacts are already visible."Doc 3: "We need climate action now."- Weights terms by importance
- Common words across documents get lower weight
- Unique/rare words get higher weight
- Still misses word order and semantics
TF-IDF matrix:
| Document | climate | change | global | challenge | impacts | action |
|---|---|---|---|---|---|---|
| Doc 1 | 0.1 | 0.6 | 0.6 | 0.6 | 0.0 | 0.0 |
| Doc 2 | 0.1 | 0.0 | 0.0 | 0.0 | 0.7 | 0.0 |
| Doc 3 | 0.1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.7 |
Notice:
- “climate” appears in all docs → lower weight (0.1)
- “change”, “global”, “challenge” unique to Doc 1 → higher weights (0.6)
- “impacts”, “action” unique to their docs → highest weights (0.7)
Word2Vec: Capturing Meaning in Vector Space
“You shall know a word by the company it keeps” (Firth, 1957)
CBOW: Continuous Bag of Words Architecture
CBOW Architecture: Predicting a word from its context
Adapted from the original Word2Vec paper: Mikolov et al., 2013
CBOW: Continuous Bag of Words Architecture
CBOW Architecture: Predicting “temperature” from context words
Example: “the global temperature is rising”
CBOW: Under the Hood
Real CBOW Implementation: Output is a probability distribution over entire vocabulary
The model learns to assign highest probability to the correct word (“temperature”)
Skip-gram: The Reverse of CBOW
Skip-gram Architecture: Predicting context words from the target word
Adapted from the original Word2Vec paper: Mikolov et al., 2013
Expectations around Semantic Similarity
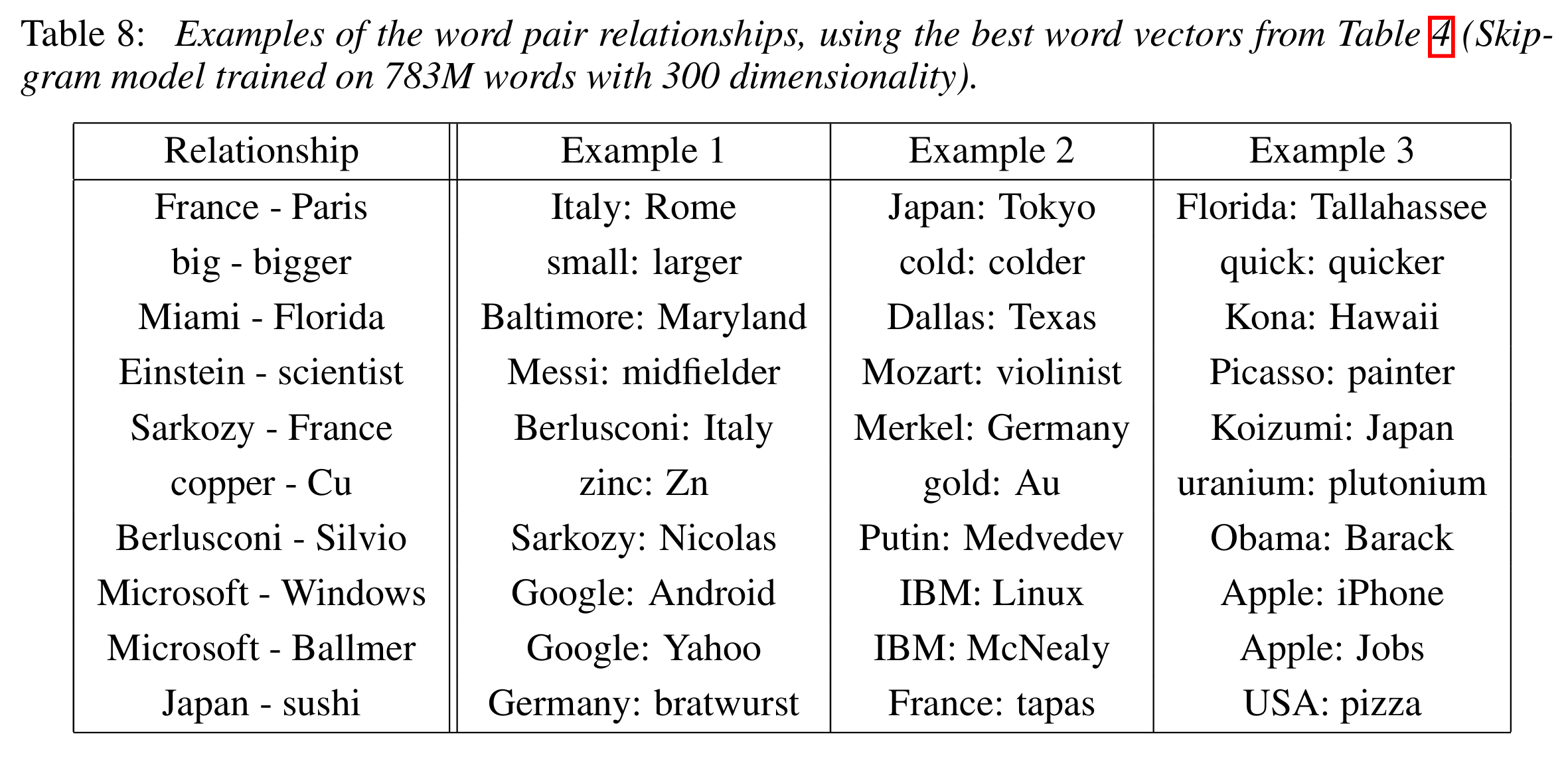
In the original Word2Vec paper, they show that word vectors trained on a corpus of text can be used to capture semantic relationships between words.
“Table 8 shows words that follow various relationships. We follow the approach described above: the relationship is defined by subtracting two word vectors, and the result is added to another word. Thus for example,
Paris- France + Italy = Rome.”
Train the Word2Vec model
Notebook Demo: Section 3
- Training the Word2Vec model
- Key parameters explanation
- Vocabulary exploration
Visualizing word relationships
Notebook Demo: Section 4 & 5
- tSNE visualization of climate terminology
- Impact of preprocessing and parameters
Similarity and Analogies
Notebook Demo: Live Exploration
- Word similarity calculations
- Word analogies in climate domain
- Impact of language filtering
Potential Applications for Climate Finance Analysis
Analysis Applications
- Finding similar commitments
- Identifying related concepts
- Building semantic search
- Tracking policy changes
TPI Use Cases
- Company commitment comparison?
- Clustering by language patterns?
5️⃣ From Words to Documents: Building Toward RAG
11:40 – 11:55
Bridging to Next Week
From Words to Documents
- Document embeddings
- Sentence/paragraph vectors
- Transformer improvements
Retrieval Foundation
Eventually we will have to cover:
- More powerful embeddings
- Vector databases
- Similarity search
- RAG pipelines
The Path Forward
Week 8
Advanced representations
Transformers & deep text processing
Weeks 9-10
Building & optimizing
RAG systems
Final Project
Production-ready
document intelligence
Thank you!
THE END
Next Steps
- Lab tomorrow: Data quality experiment
- Week 8: Transformers & advanced processing
Resources
- Notebook from today’s lecture
- Word2Vec original paper
- This silly Youtube video
- 3Blue1Brown video on word embeddings
![]()
LSE DS205 (2024/25)