🗓️ Week 09:
Unsupervised learning II: More clustering, anomaly detection and dimensionality reduction
Theme: Unsupervised learning
2023-11-24
Why should we use DBSCAN?

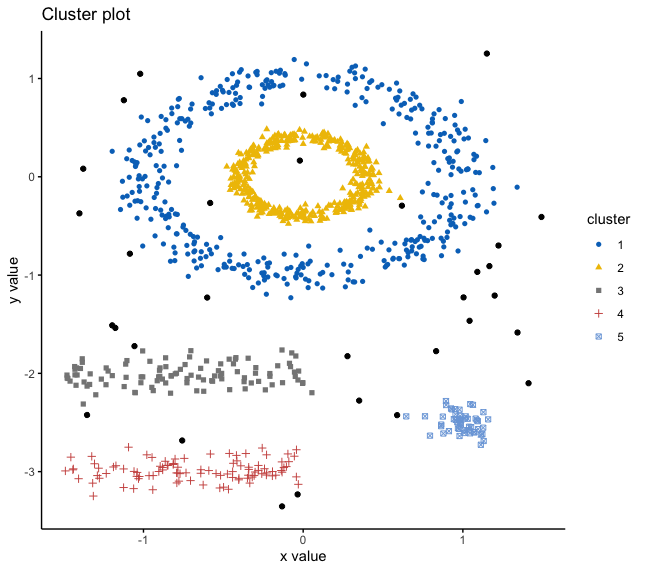
How many clusters do you see?
Why should we use DBSCAN?
Let’s see how K-Means deals with this dataset

Why should we use DBSCAN?
Now how about DBSCAN?
How does DBSCAN work?
Quick recap: \(\epsilon\)-neighbourhood 
- Given a distance \(\epsilon\), the \(\epsilon\)-neighbourhood of a point is the number of points within distance at most \(\epsilon\) of it.
- In this example, \(\epsilon\)-neighbourhood of D is 6 if \(\epsilon\) is 2.
DSBSCAN takes two parameters:
\(\epsilon\) or
eps: does that sound familiar?That’s because it is! The parameter
epsdefines the radius of the neighborhood around a pointx. This is what we called the \(\epsilon\)-neighborhood ofxearlier
minPts: it’s simply the minimum number of points within \(\epsilon\) radius
How does DBSCAN work?

A few definitions:
- Any point \(x\) in the data set, with a neighbour count greater than or equal to
MinPts, is a core point - \(x\) is a border point, if the number of its neighbors is less than
MinPts, but it belongs to the \(\epsilon\)-neighborhood of some core point \(z\). - If a point is neither a core nor a border point, then it is called a noise point or an outlier.
The figure shows the different types of points (core, border and outlier points) using MinPts = 6:
- \(x\) is a core point because \(neighbours_\epsilon(x)=6\)
- \(y\) is a border point because \(neighbours_\epsilon(y)<MinPts\), but it belongs to the \(\epsilon\)-neighborhood of the core point \(x\).
- Finally, \(z\) is a noise point.
A few more definitions:
- Direct density reachable: A point “A” is directly density reachable from another point “B” if: i) “A” is in the \(\epsilon\)-neighborhood of “B” and ii) “B” is a core point. E.g \(y\) is directly density reachable
- Density reachable: A point “A” is density reachable from “B” if there are a set of core points leading from “B” to “A.
- Density connected: Two points “A” and “B” are density connected if there are a core point “C”, such that both “A” and “B” are density reachable from “C”.
In density-based clustering, a cluster is defined as a group of density connected points.
Density-based anomaly detection : Local outlier factor (LOF)
- K-distance is the distance between a point and it’s K\(^{th}\) nearest neighbor.
- K-neighbors, denoted by \(N_k(A)\) is the set of points that lie in or on the circle of radius K-distance. K-neighbors can be greater or equal to the value of K.
Let’s see an example:

Let’s say we have four points: A, B, C, and D.
If K=2, K-neighbors of A include C, B and D and therefore \(||N_2(A)||\) = 3.
Density-based anomaly detection : Local outlier factor (LOF)
Reachability distance:
- Given two points \(x_j\) and \(x_i\), it is defined as the maximum of K-distance of \(x_j\) and the distance between \(x_i\) and \(x_j\). The distance measure is problem-specific (e.g Euclidean, Manhattan).
Written more formally, this would look like this: \(RD(x_i,x_j)=\max(\textrm{K-distance}(x_j),\textrm{distance}(x_i,x_j))\)
Said differently, if a point \(x_i\) belongs to the K-neighbors of \(x_j\) , the reachability distance will be K-distance of \(x_j\) (blue line), otherwise the reachability distance will be the distance between \(x_i\) and \(x_j\) (orange line)
- Given two points \(x_j\) and \(x_i\), it is defined as the maximum of K-distance of \(x_j\) and the distance between \(x_i\) and \(x_j\). The distance measure is problem-specific (e.g Euclidean, Manhattan).

Density-based anomaly detection: Local outlier factor (LOF)

- 4 points: A(0,0), B(1,0), C(1,1) and D(0,3) and K=2.
- We will use LOF to detect one outlier (D) among these 4 points.
- First, calculate the K-distance, distance between each pair of points, and K-neighborhood of all the points with K=2
- We will be using the Manhattan distance as a measure of distance i.e \(d(x,y)=\sum_{i=1}^n |x_i-y_i|\)
| Distance | Value |
|---|---|
| d(A,B) | 1 |
| d(A,C) | 2 |
| d(A,D) | 3 |
| d(B,C) | 1 |
| d(B,D) | 4 |
| d(C,D) | 3 |
K-distance(A): since C is the 2\(^{nd}\) nearest neighbor of A, K-distance(A)=d(A,C) =2 K-distance(B): since A, C are the 2\(^{nd}\) nearest neighbor of B, K-distance(B)=distance(B,C) OR K-distance(B)=distance(B,A) = 1 K-distance(C): since A is the 2\(^{nd}\) nearest neighbor of C –> K-distance(C)=distance(C,A) =2 K-distance(D): since A,C are the 2\(^{nd}\) nearest neighbor of D –> K-distance(D)=distance(D,A) or K-distance(D)=distance(D,C) =3
- K-neighborhood (A) = {B,C} , \(||N_2(A)|| =2\)
K-neighborhood (B) = {A,C}, \(||N_2(B)|| =2\)
K-neighborhood (C)= {B,A}, \(||N_2(C)|| =2\)
K-neighborhood (D) = {A,C}, \(||N_2(D)|| =2\)
Density-based anomaly detection: Local outlier factor (LOF)
We use the K-distance and K-neighbourhood to compute the LRD for each point
\(LRD_2(A)=\frac{1}{\frac{RD(A,B)+RD(A,C)}{||N_2(A)||}}=\frac{\frac{1}{1+2}}{2}=0.667\) \(LRD_2(B)=\frac{1}{\frac{RD(B,A)+RD(B,C)}{||N_2(B)||}}=\frac{\frac{1}{2+2}}{2}=0.50\) \(LRD_2(C)=\frac{1}{\frac{RD(C,A)+RD(C,B)}{||N_2(C)||}}=\frac{\frac{1}{1+2}}{2}=0.667\) \(LRD_2(D)=\frac{1}{\frac{RD(D,A)+RD(D,C)}{||N_2(D)||}}=\frac{\frac{1}{3+3}}{2}=0.337\)
\(LOF_2(A)=\frac{LRD_2(B)+LRD_2(C)}{||N_2(A)||}\times\frac{1}{LRD_2(A)}=\frac{0.5+0.667}{2}\times\frac{1}{0.667}=0.87\) \(LOF_2(B)=\frac{LRD_2(A)+LRD_2(C)}{||N_2(B)||}\times\frac{1}{LRD_2(B)}=\frac{0.667+0.667}{2}\times\frac{1}{0.5}=1.334\) \(LOF_2(C)=\frac{LRD_2(A)+LRD_2(B)}{||N_2(C)||}\times\frac{1}{LRD_2(C)}=\frac{0.667+0.5}{2}\times\frac{1}{0.667}=0.87\) \(LOF_2(D)=\frac{LRD_2(A)+LRD_2(C)}{||N_2(D)||}\times\frac{1}{LRD_2(D)}=\frac{0.667+0.667}{2}\times\frac{1}{0.337}=2\)
The highest LOF among the four points is LOF(D). Therefore, D is an outlier/anomaly.
Principal component analysis
Say we’re playing a guessing game and are trying to guess the height of three people.
| Person | Height (cm) |
|---|---|
| Alex | 145 |
| Ben | 160 |
| Chris | 185 |
If looking at the silhouettes below

Then, we can guess Chris is A, B is Alex and C is Ben
Principal component analysis
If we now try to figure who hides behind these silhouettes

when we have this new group of people
| Person | Height (cm) |
|---|---|
| Tabby | 171 |
| Jon | 172 |
| Alex | 173 |
this suddenly becomes tougher!
That’s because in the earlier group, the height varied substantially. In the same way, when our data has a higher variance, it holds more information. Variance is information