Week 09
📊 Exploratory Data Analysis & Data Visualisation
DS105W – Data for Data Science
🗓️ 19 Mar 2026
Why you can’t just look at the numbers
In 1973, statistician Francis Anscombe created four datasets that have nearly identical summary statistics:
| Statistic | Dataset I | Dataset II | Dataset III | Dataset IV |
|---|---|---|---|---|
| Mean of x | 9.0 | 9.0 | 9.0 | 9.0 |
| Mean of y | 7.50 | 7.50 | 7.50 | 7.50 |
| Std dev of y | 2.03 | 2.03 | 2.03 | 2.03 |
| Correlation | 0.816 | 0.816 | 0.816 | 0.816 |
All of these datasets have the same mean, same standard deviation, and same correlation. At this point, you would expect these datasets to look similar but they don’t.

The Datasaurus Dozen: same stats, very different shapes
Matejka & Fitzmaurice (2017) pushed this idea to its extreme.
All 13 datasets have the same summary statistics to two decimal places:
- x mean = 54.26
- y mean = 47.83
- x SD = 16.76
- y SD = 26.93
- Pearson’s R = −0.06
When you plot them, they look completely different.
Lesson: .describe() is where you start, not where you stop. Always visualise your data.

Today’s EDA dataset: IMDb
Let me show you one particular dataset that could help me illustrate some of these concepts.
I will use data from the Internet Movie Database (IMDb), which is a popular online database of movies, TV shows, and the people involved in making them.
The data is spread across multiple tables, just like your MP2 data is spread across TfL journey files and the ONS Postcode Directory:
| Table | What a row describes |
|---|---|
title_basics |
One title (movie, series, episode) |
title_ratings |
One title’s average rating and vote count |
title_principals |
One person’s role in one title |
name_basics |
One person (director, actor, etc.) |
2.2 How to get a visual sense of the distribution
Histogram approach:
A histogram allows you to see the full distribution of the data.
In this case, the distribution is heavily skewed.

For NB03 exploratory plots, you don’t need a polished title yet.
- When you are just exploring your data in your
NB03, it’s alright to just plot the histogram without a title for your own observations. - 💡 If you think this is worth adding to your
REPORT.md, then add a narrative title to your plot.
2.3 Second attempt at visualising the distribution
If you further process the data carefully, you can get a more informative histogram 👉
- The mean number of movies (2.66) isn’t a good measure of average when you have skewed distributions like this.
- The median number of movies (1) is a better measure of average in this case

3.1 Boxplot as a visual summary of the distribution
Once again, you can use describe():
plot_df['average_rating'].describe()Which produces:
count 12118.000000
mean 6.584832
std 1.016968
min 1.000000
25% 6.000000
50% 6.700000
75% 7.300000
max 9.300000
Name: average_rating, dtype: float64Alternatively, you can view this as a boxplot:

You can describe this as:
- Typically, popular movies have an average rating between 6.0 and 7.3.
- There are only a few movies with an exceptionally high rating (9.3)
- There is a small group (albeit a sizeable group) of movies with an average rating below 4.0
3.2 This time the histogram works
Because the distribution is not skewed, the distribution of the data is symmetric similar to a normal distribution.
When the data looks like a bell curve, the mean and the median are very similar and it makes sense to use mean and standard deviation to describe the distribution.

Using the mean and standard deviation as estimators, you can describe this as:
- Most popular movies have an average rating between 5.6 and 7.6, with an average rating of about 6.6.
☕ Coffee Break
![]()
Sin #1: The truncated axis

The same data, two very different impressions.
On the left, the y-axis starts at 44%, making a 1-percentage-point difference look enormous. On the right, the y-axis starts at 0, showing the true proportion.
Rule of thumb: bar charts should always start at zero. Line charts sometimes have legitimate reasons to zoom in, but you should annotate why.
Sin #2: Bar plots hide distributions

All four distributions produce the same bar graph (same mean, same error bar). But look at the actual data:
- One is normally distributed ✅
- One has two outliers pulling the mean ⚠️
- One is bimodal (two distinct groups!) 🚨
- One has a single extreme outlier 🚨
You saw this principle in 🖥️ W08 Lecture with the strip+box+mean plot. This is the research paper behind it.
The same lesson as the Datasaurus

FacetGrid: comparing groups systematically
When you have multiple groups (destinations, time bands, boroughs), plotting them all on one axis gets crowded.
sns.FacetGrid creates a grid of subplots, one per group, with consistent axes so comparisons are fair.
g = sns.FacetGrid(
df_all,
col="destination",
col_wrap=3,
height=3
)
g.map_dataframe(
sns.histplot,
x="duration_min",
binwidth=5
)
Each panel shows the distribution for one destination. Same x-axis, same y-axis, so you can compare shapes at a glance.
FacetGrid with hue
Add hue to compare subgroups within each panel:
g = sns.FacetGrid(
df_all,
col="destination",
hue="time_band",
col_wrap=3,
height=3,
)
g.map_dataframe(
sns.histplot,
x="duration_min",
binwidth=5,
alpha=0.5,
)
g.add_legend()
Now you can see whether peak vs off-peak distributions differ within each destination and across destinations. But the key takeaway might not be super obvious, you need to guide your reader if you produce more complex visualisations like these.
5. Correlation is not causation
Key rule: “correlation does not imply causation.”
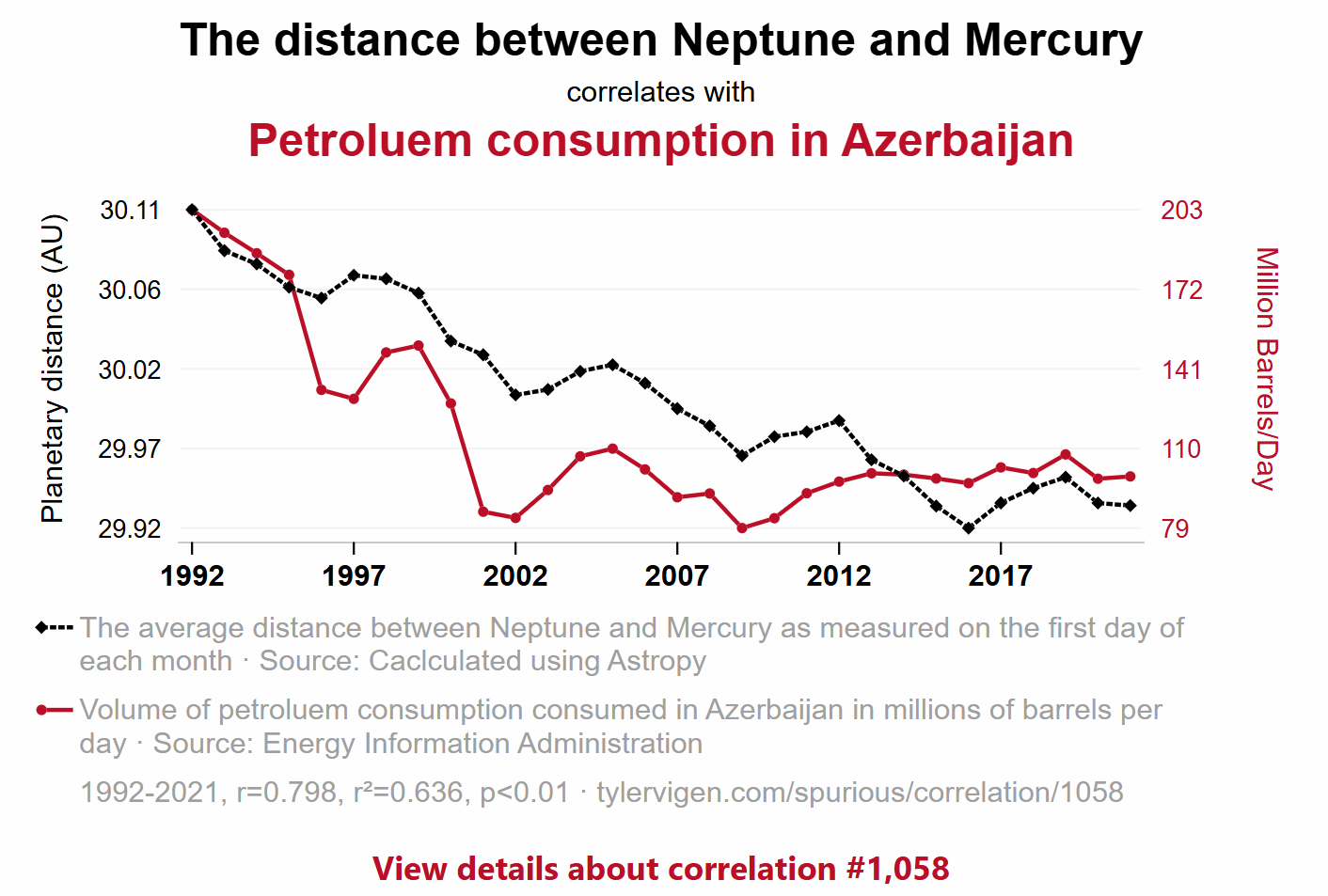
Two trends can move together because:
- Coincidence: the variables correlate in this time period
- Confounding variable: a third factor drives both
- Reverse causation: the direction is the opposite of what you assumed
- Actual causation: rare, and requires much more evidence than a chart
📖 Tyler Vigen’s Spurious Correlations: hilarious examples of correlation without causation.