🗓️ Week 08
Machine Learning II
DS101 – Fundamentals of Data Science
18 Nov 2024
The Decision Tree model

The Decision Tree model applied to diabetes: the metrics
precision recall f1-score support
Negative 0.83 0.98 0.90 54
Positive 0.99 0.89 0.94 102
accuracy 0.92 156
macro avg 0.91 0.94 0.92 156
weighted avg 0.93 0.92 0.92 156
The Support Vector Machine model
Say you have a dataset with two classes of points:

The Support Vector Machine model
The goal is to find a line that separates the two classes of points:

The Support Vector Machine model
It can get more complicated than just a line:

Neural Networks

Attention

- The Transformer architecture is a deep learning model that uses attention to learn contextual relationships between words in a text.
- It has revolutionized the field of Natural Language Processing (NLP).
Density
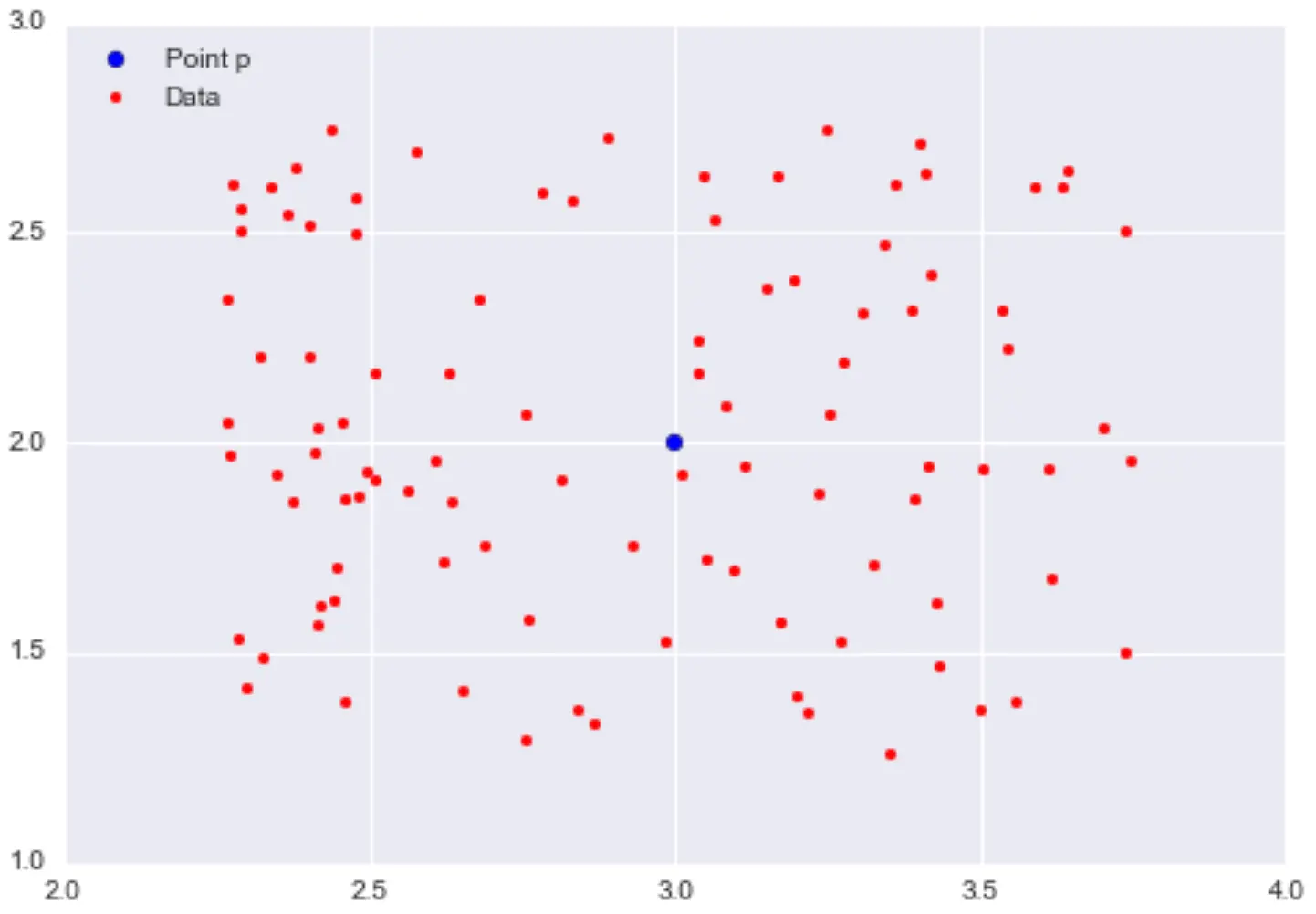
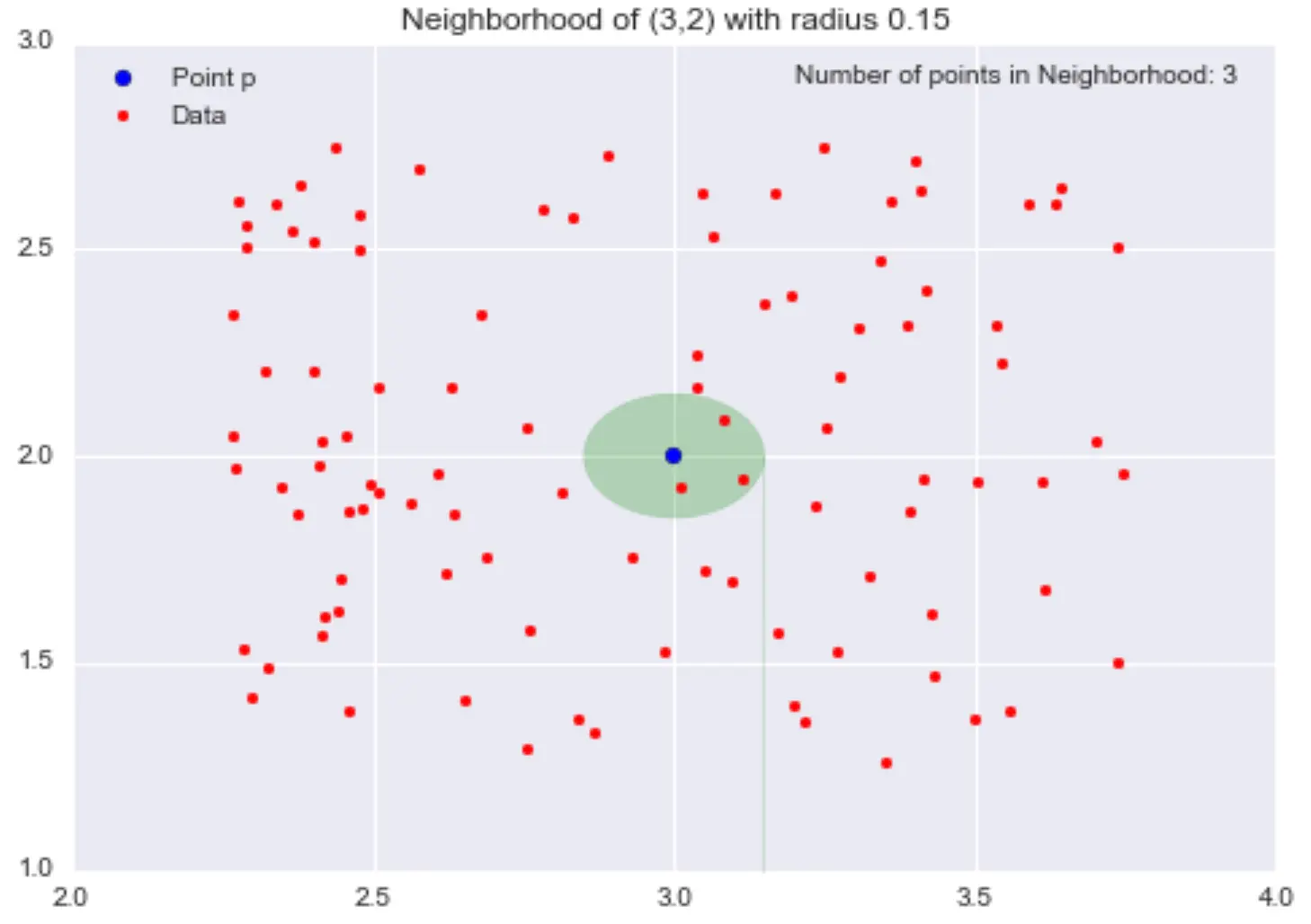
\(\epsilon\)-neighbourhoods:
- given \(\epsilon>0\) and a point \(p\), the \(\epsilon\)-neighbourhood of \(p\) is the set of points that are at distance at most \(\epsilon\) away from \(p\)
Example:
(Images source: https://domino.ai/blog/topology-and-density-based-clustering)
Density (continued)
Density:
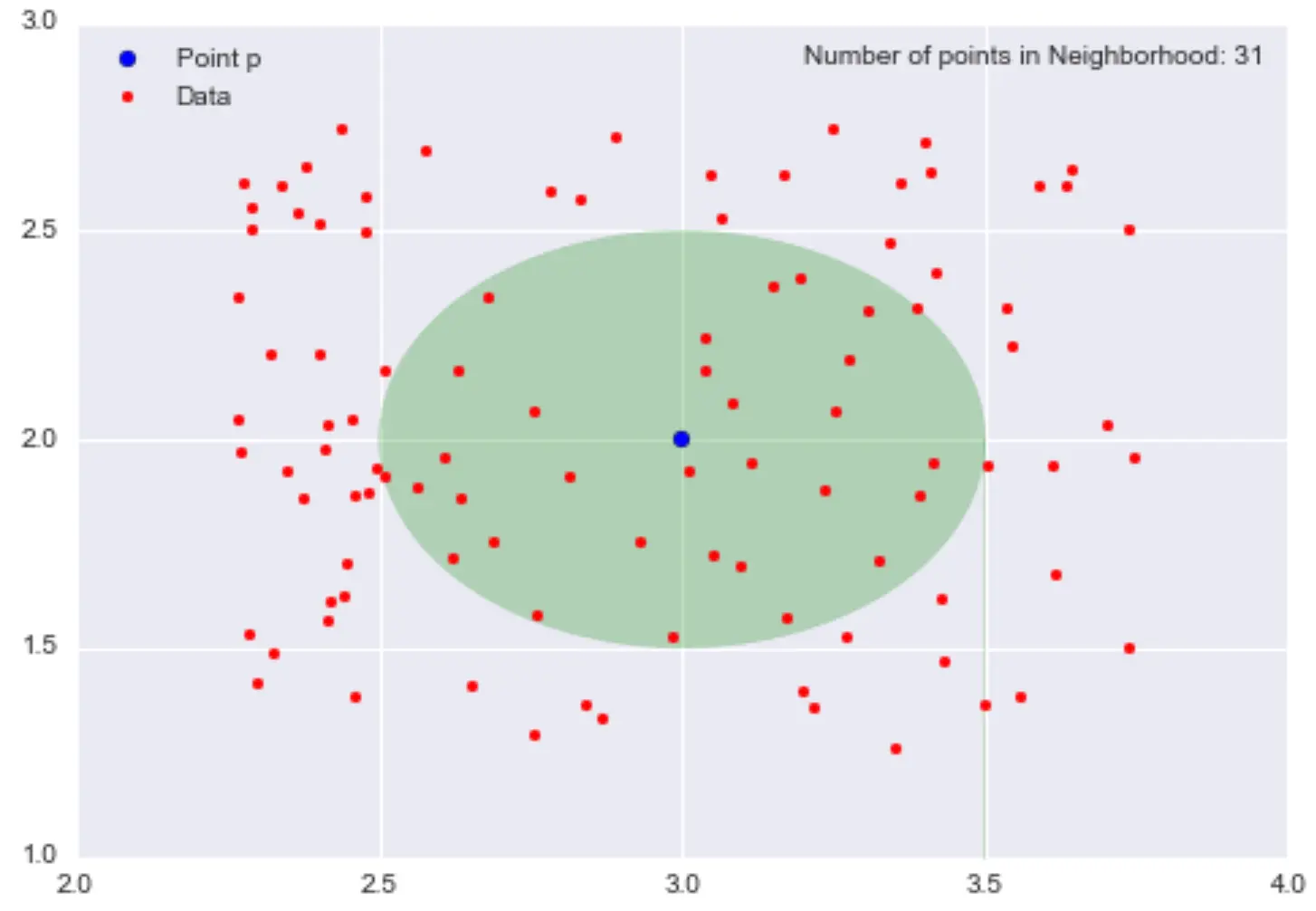
- Roughly defined, \(\textrm{density}=\frac{\textrm{"mass"}}{\textrm{"volume"}}\)
- If we go back to our previous example, the “mass” would be the number of points in an \(\epsilon\)-neighbourhood centered in \(p\) and the “volume” the area of radius \(\epsilon\) centered around \(p\)
Example:
If we take the figure above, the local density estimation at \(p=(3,2)\) is \(\frac{31}{0.25\pi} \approx 39.5\)
- Number that is meaningless on its own
- If we calculate the densities of all points in our dataset, we could say that points within the same neighbourhood and similar local densities belong to the same cluster \(\rightarrow\) General principle of density-based clustering methods e.g DBSCAN (see (Ester et al. 1996) for more details on the DBSCAN algorithm)
An example of clustering algorithm: k-means
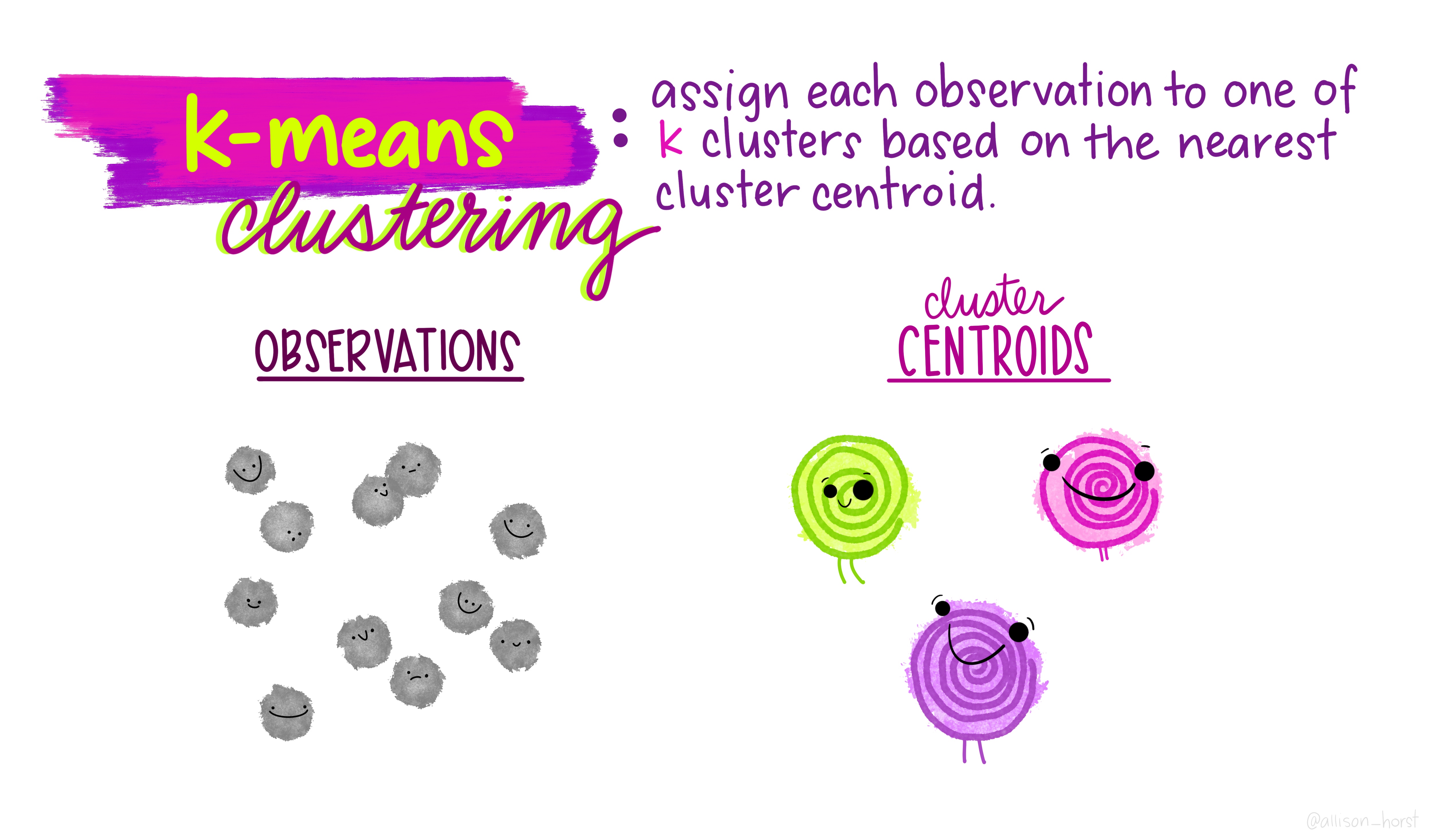
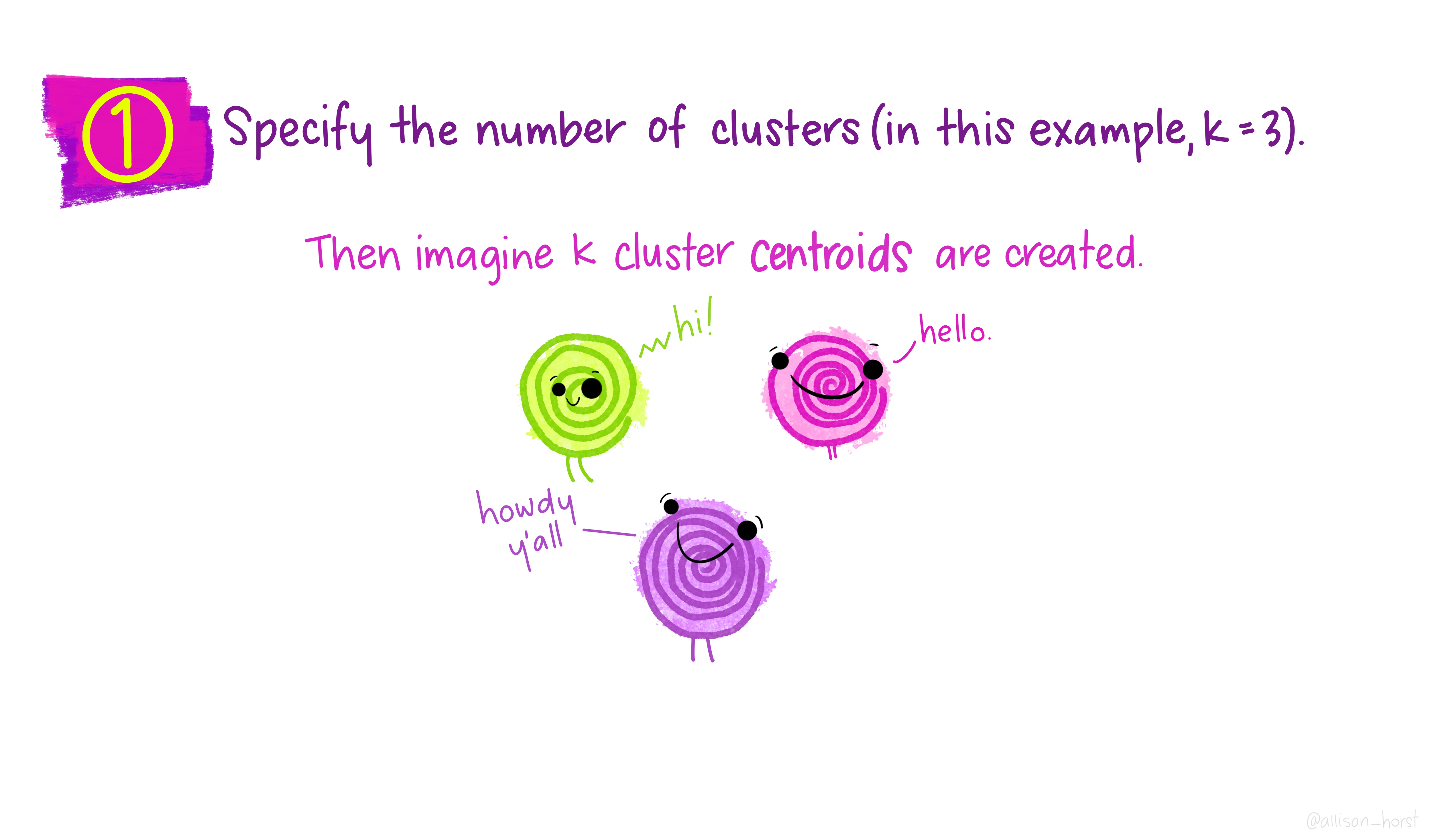

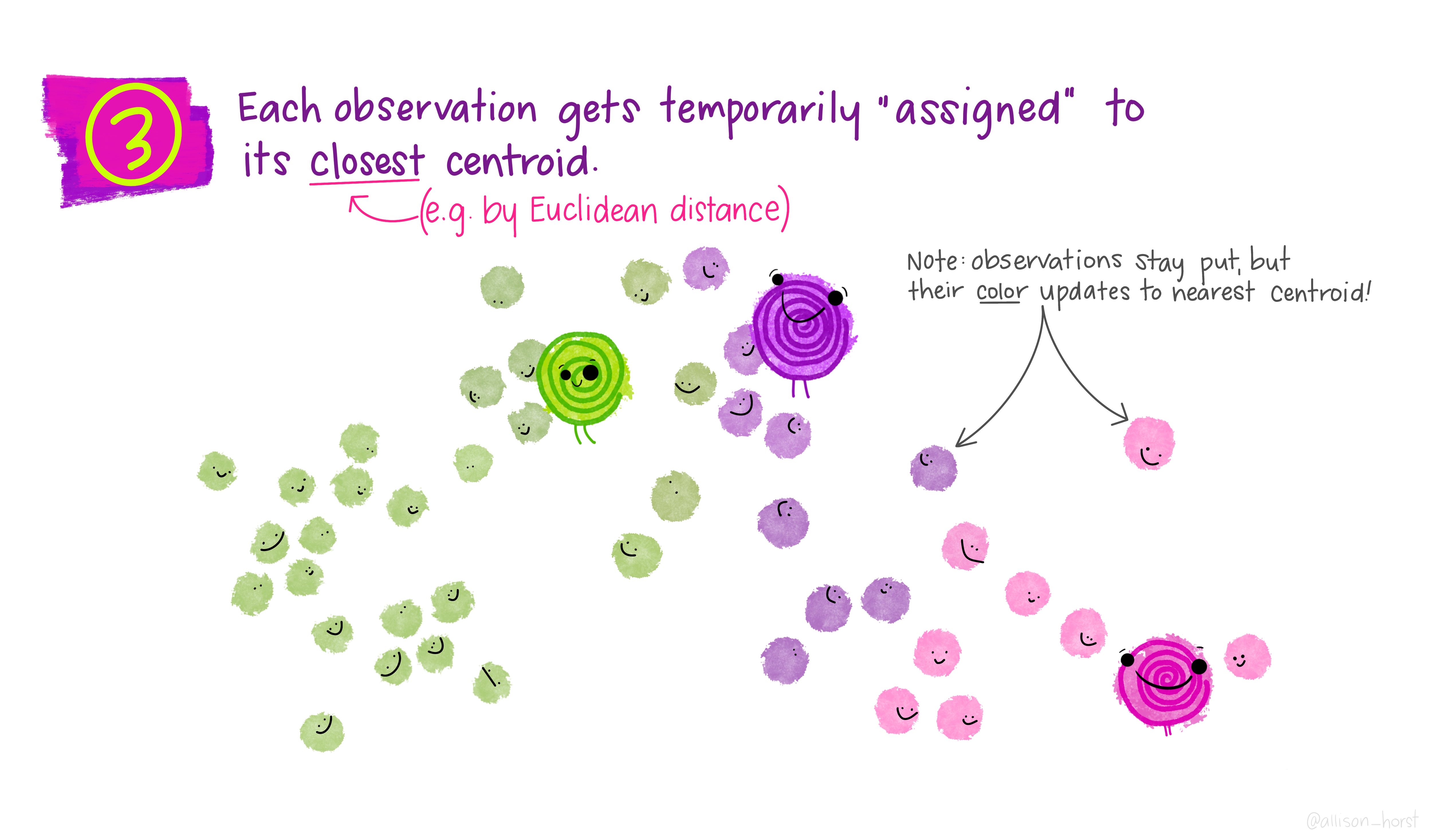
An example of clustering algorithm: k-means (continued)
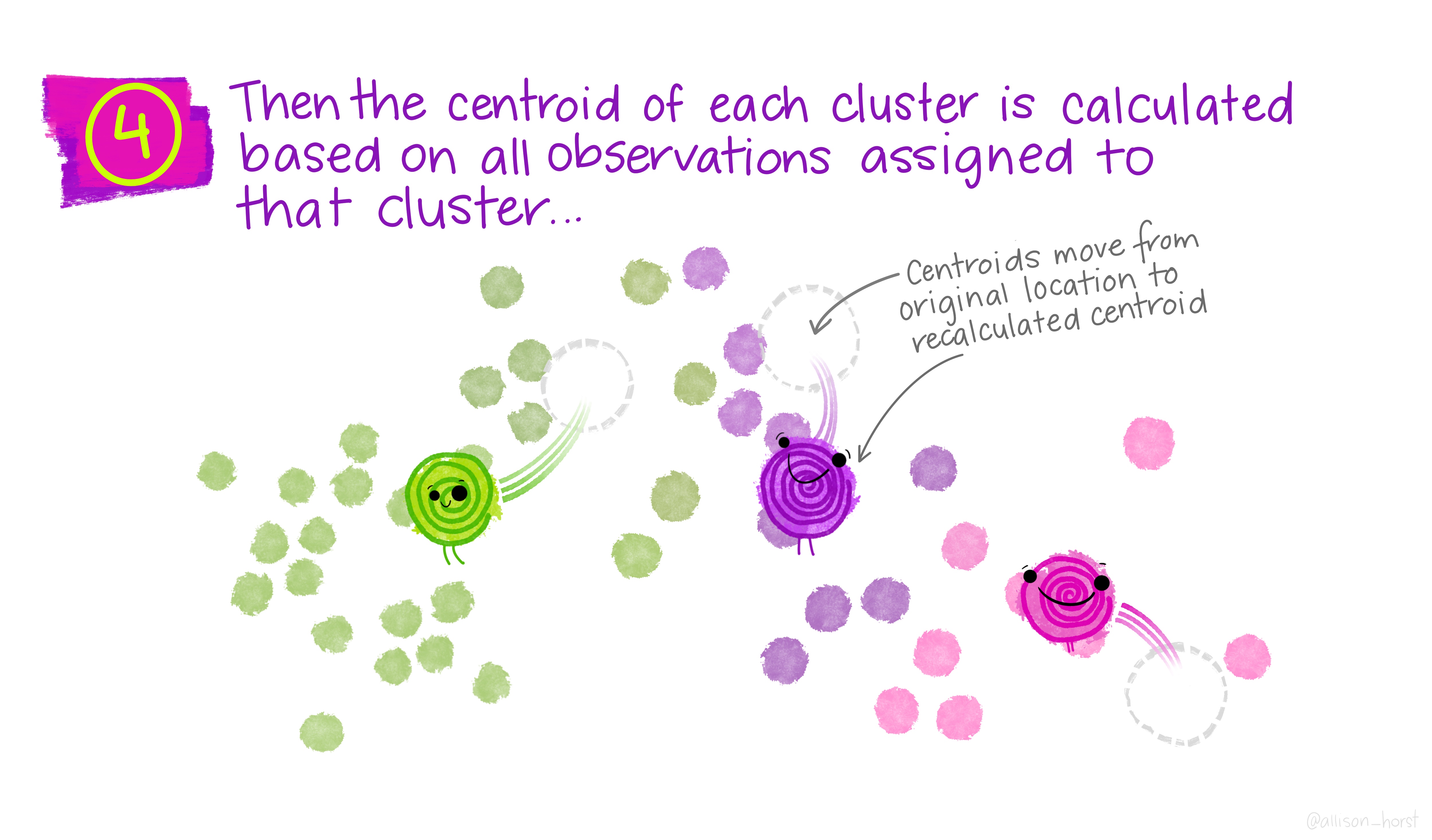
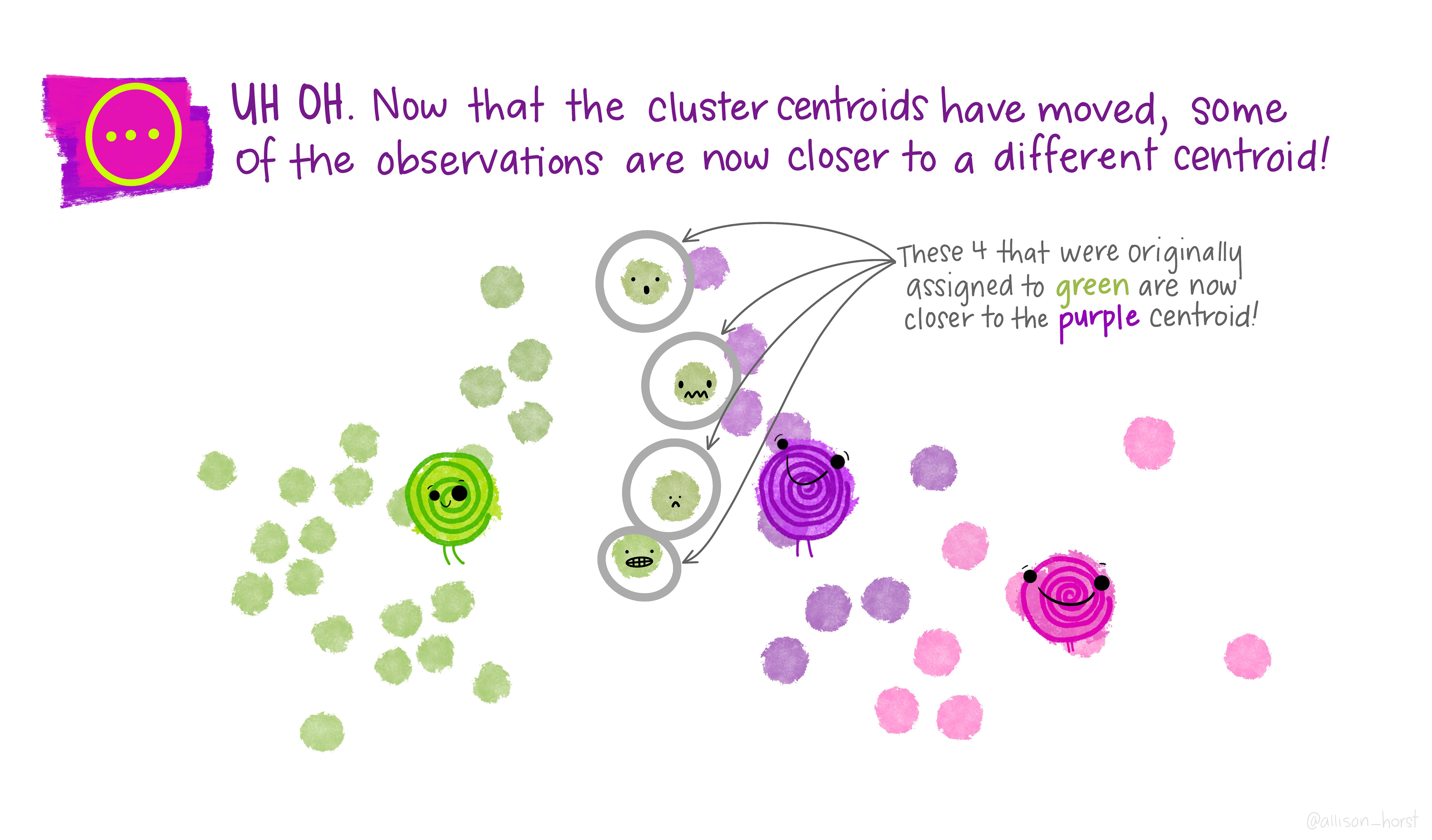
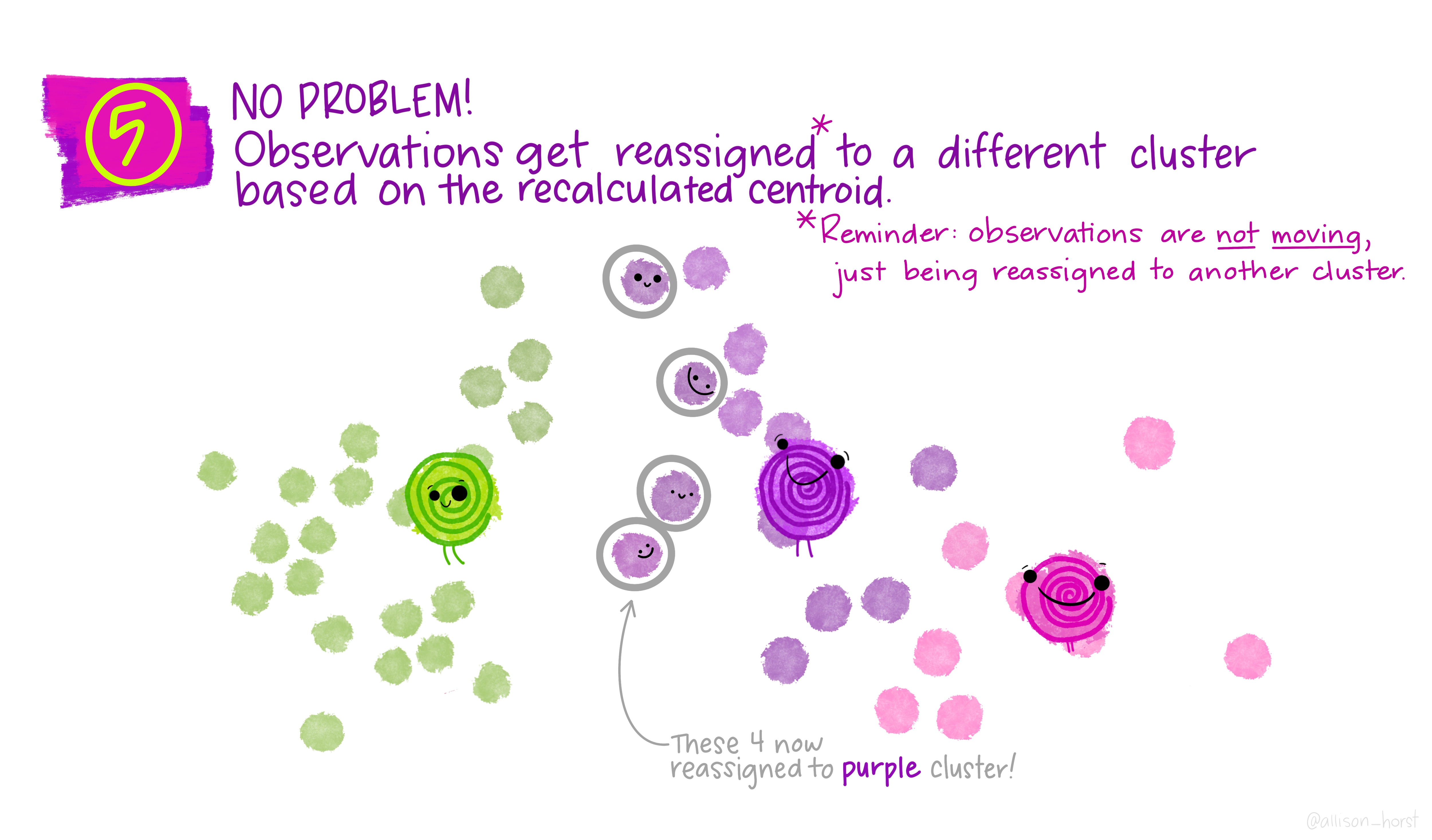

An example of clustering algorithm: k-means (continued)
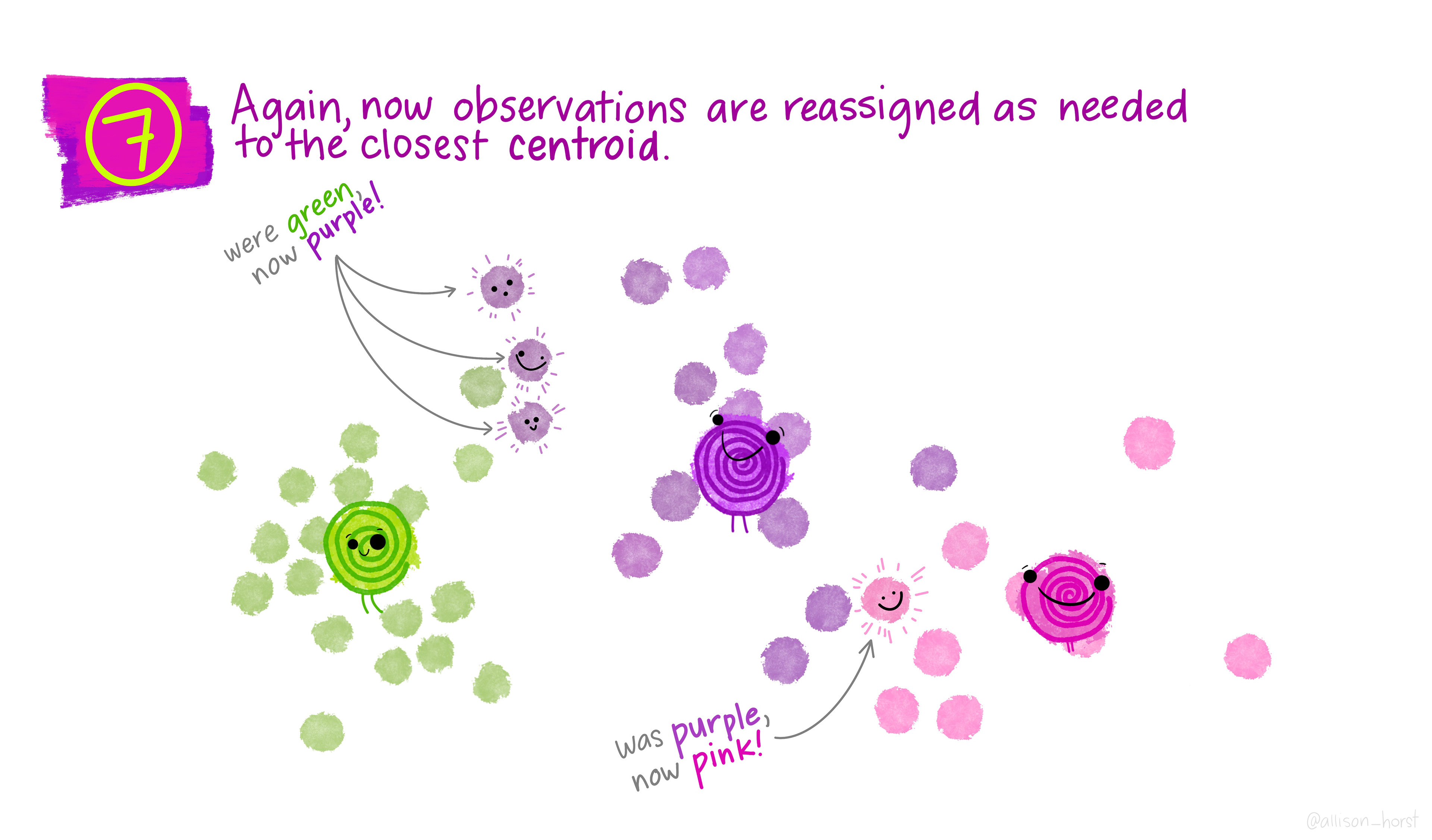
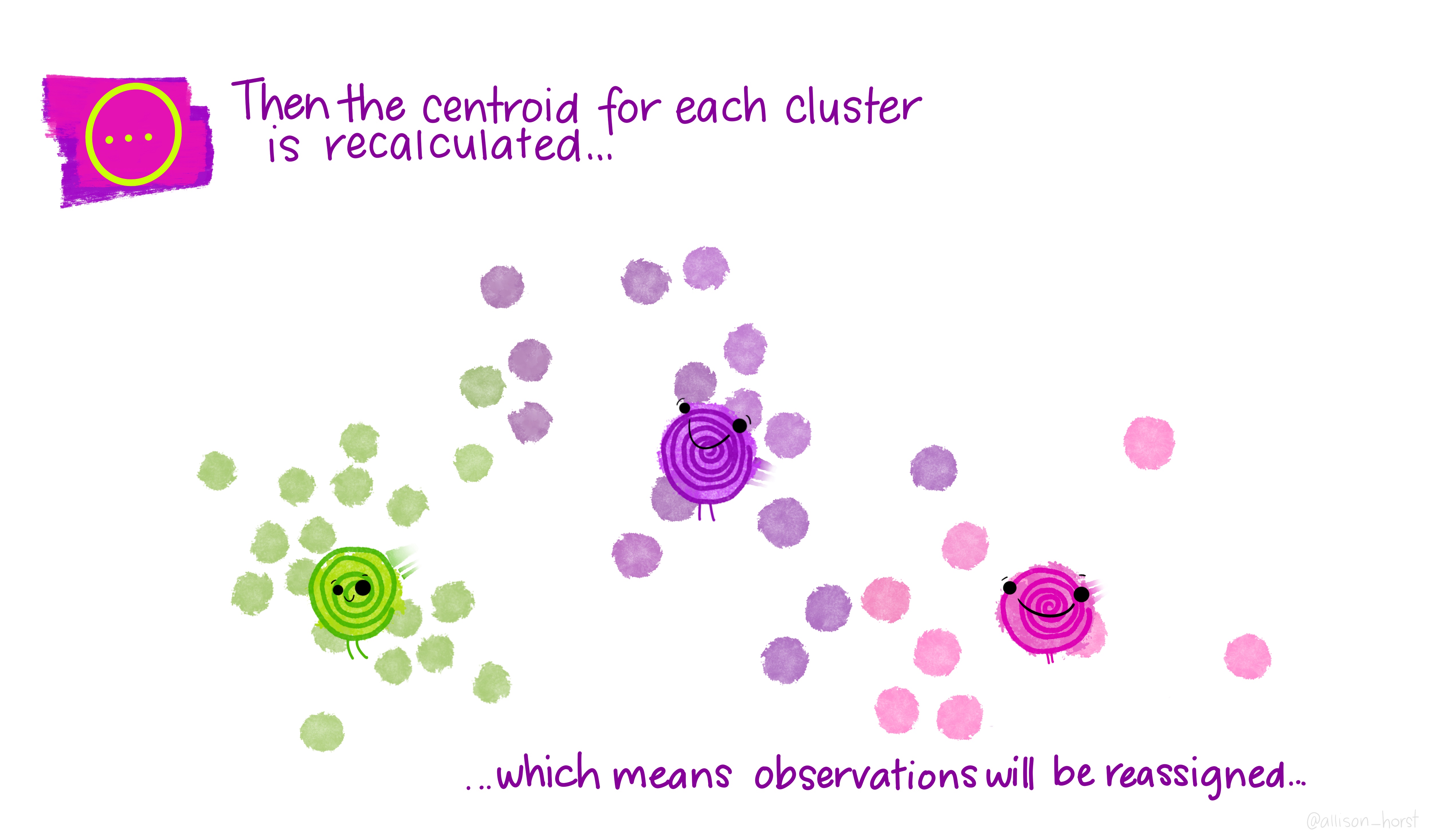
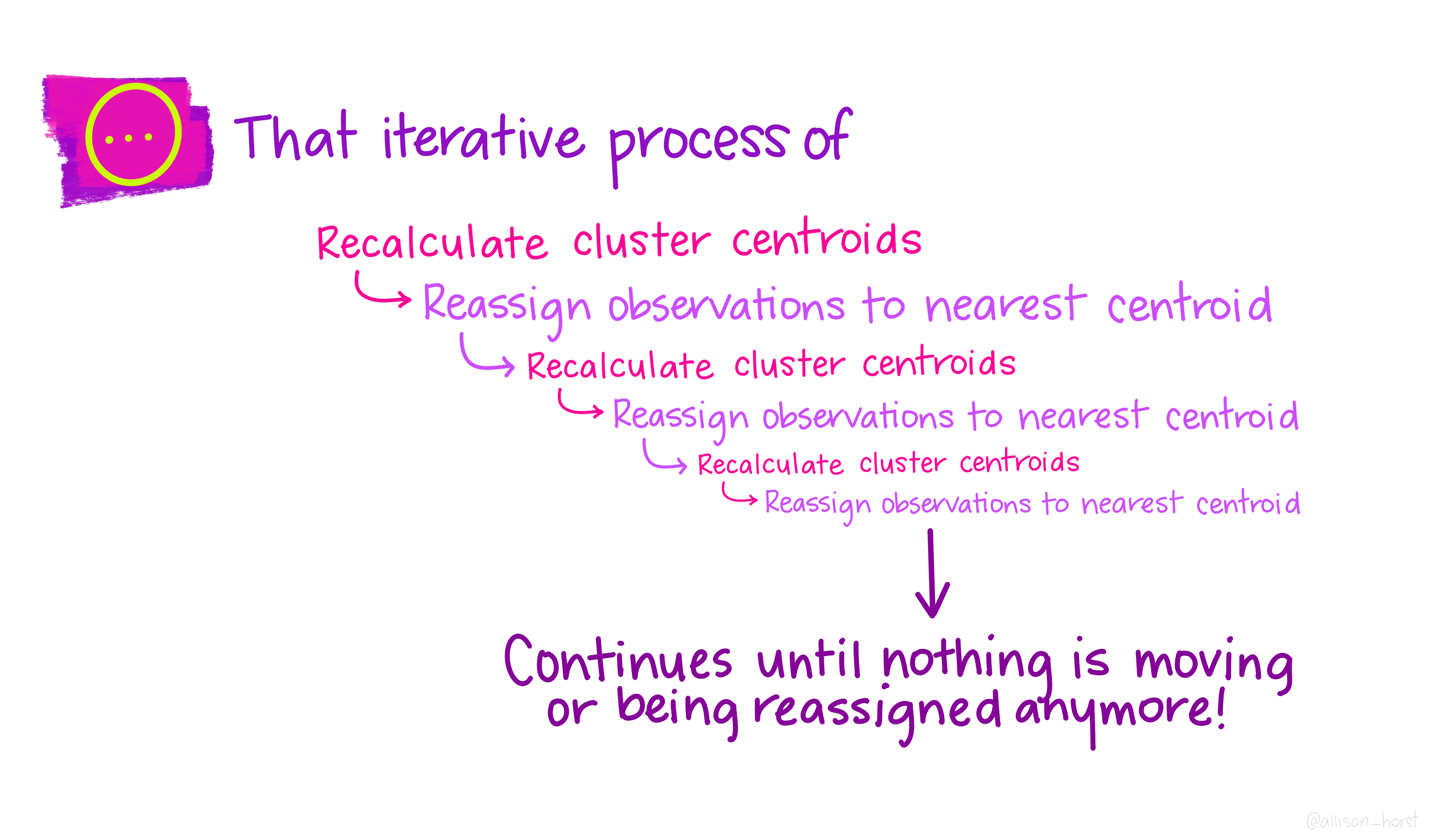
Time for a break 🍵

After the break:
- Clustering in practice
- Anomaly detection
