🗓️ Week 07
Machine Learning I
DS101 – Fundamentals of Data Science
06 Nov 2023
⏪ The simple linear model from W05
Remember the simple linear model from W05?
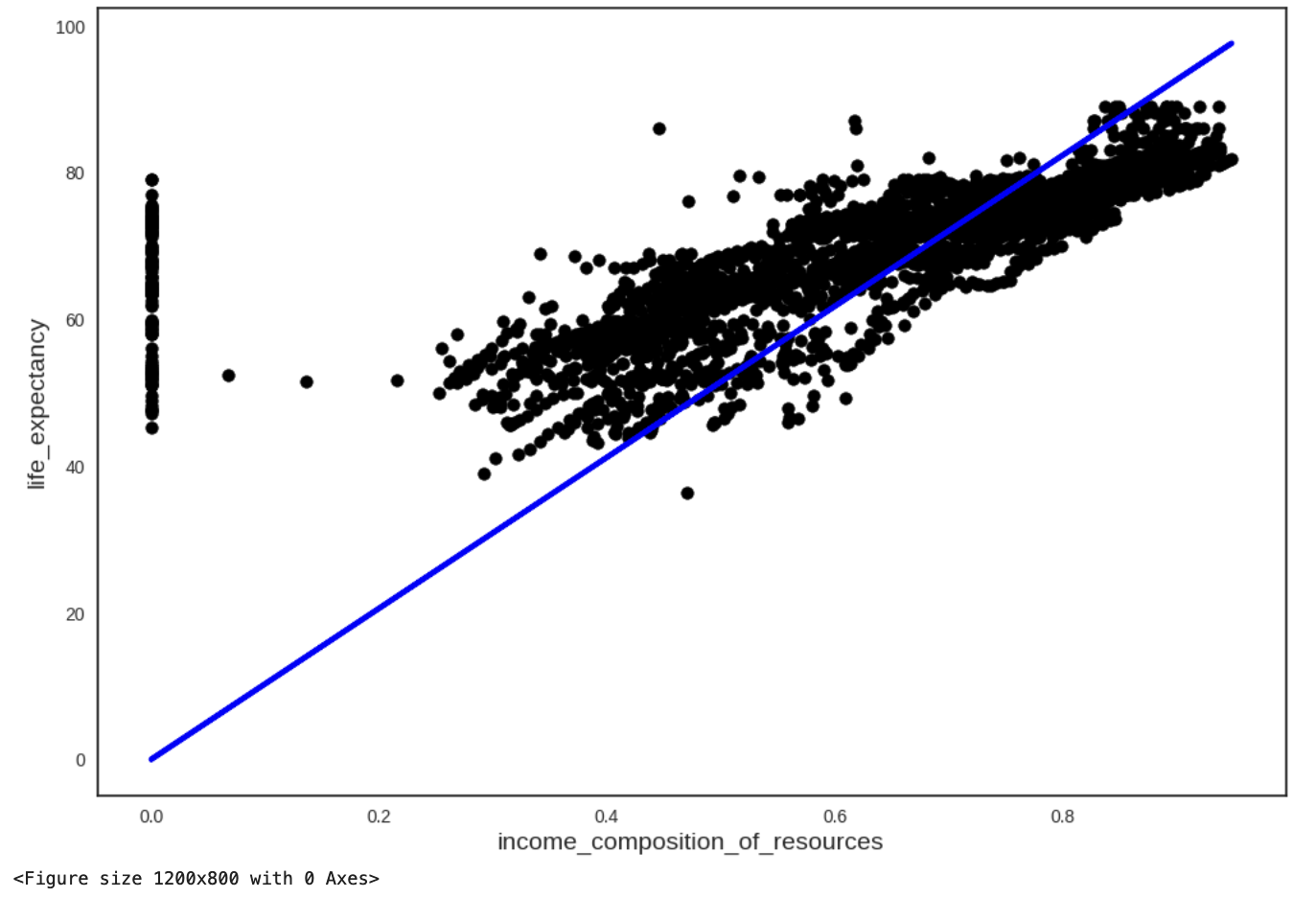
What happens when we extrapolate?
What kind of prediction would this model give if we were to set the independent variable to 1 (i.e maximum possible human development index) ?

How it works

How it works
- The process is similar to the regular algorithms (think recipes) we saw in W03.
- Only this time, the ingredients are data.
INPUT (data)
⬇️
ALGORITHM
⬇️
OUTPUT (prediction)

One Practical Example
Suppose you want to be able to tell whether a patient has breast cancer or not.

How would you approach this problem?
What is in the digitized images of biopsies?

About 30 features, among which for each cell nucleus (3), 10 features:
- radius (mean of distances from center to points on the perimeter)
- texture (standard deviation of gray-scale values)
- perimeter
- area
- smoothness (local variation in radius lengths)
- compactness (perimeter^2 / area - 1.0)
- concavity (severity of concave portions of the contour)
- concave points (number of concave portions of the contour)
- symmetry
- fractal dimension (“coastline approximation” - 1)
All of this information constitutes our input.
Structure of dataset

Side story
The data shown before actually corresponds to the Diagnostic Wisconsin Breast Cancer Database1 (Wolberg and Street 1995) that was made publicly available (in 1995!) on the UC Irvine Machine Learning Repository (or UCI Machine Learning Repository).
The UCI repository is “a collection of databases, domain theories, and data generators that are used by the machine learning community for the empirical analysis of machine learning algorithms” ((Markelle Kelly, n.d.), “About Us” page).

Time for a break 🍵

After the break:
- Examples of supervised learning algorithms
- Self-supervised learning
The Logistic Regression model
Consider a binary response:
\[ Y = \begin{cases} 0 \\ 1 \end{cases} \]
We model the probability that \(Y = 1\) using the logistic function (aka. sigmoid curve):
\[ Pr(Y = 1|X) = p(X) = \frac{e^{\beta_0 + \beta_1X}}{1 + e^{\beta_0 + \beta_1 X}} \]

The Decision Tree model

The Support Vector Machine model
Say you have a dataset with two classes of points:

The Support Vector Machine model
The goal is to find a line that separates the two classes of points:

The Support Vector Machine model
It can get more complicated than just a line:

Neural Networks

Attention

- The Transformer architecture is a deep learning model that uses attention to learn contextual relationships between words in a text.
- It has revolutionized the field of Natural Language Processing (NLP).
