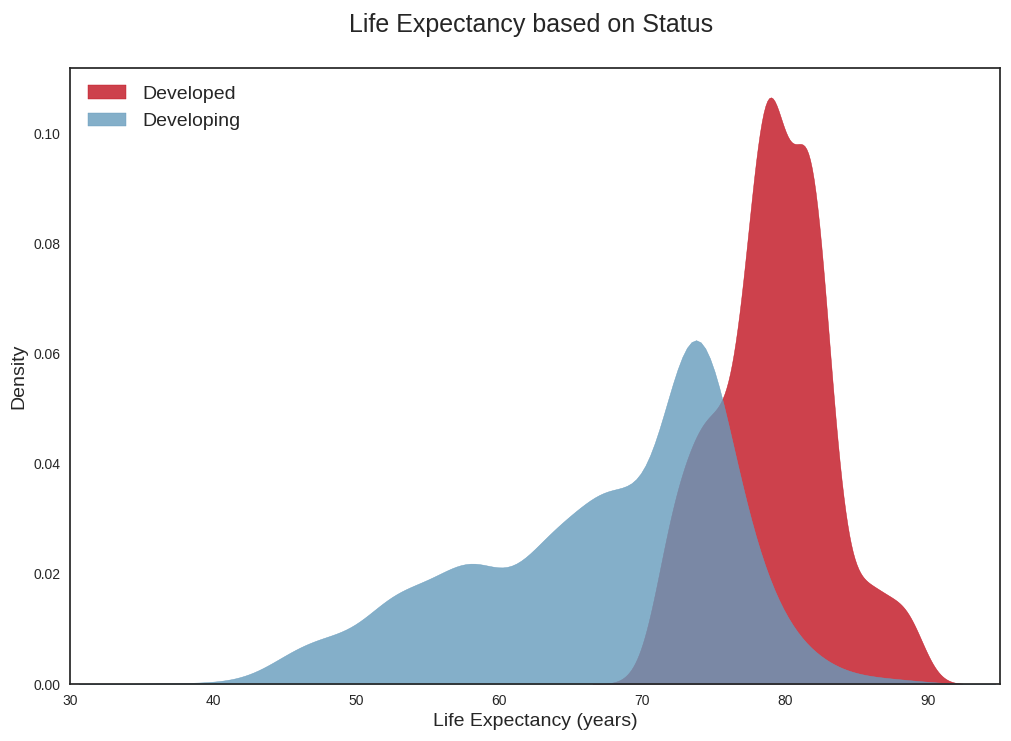
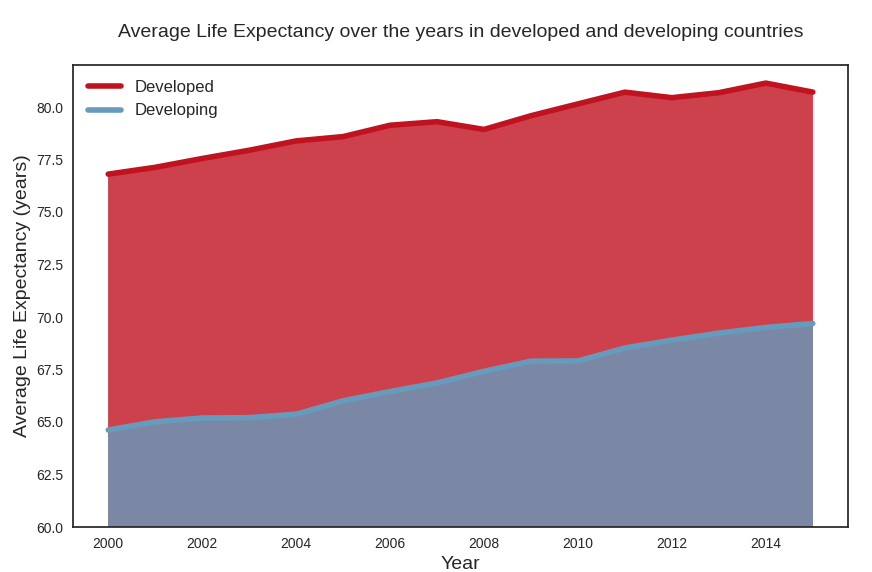
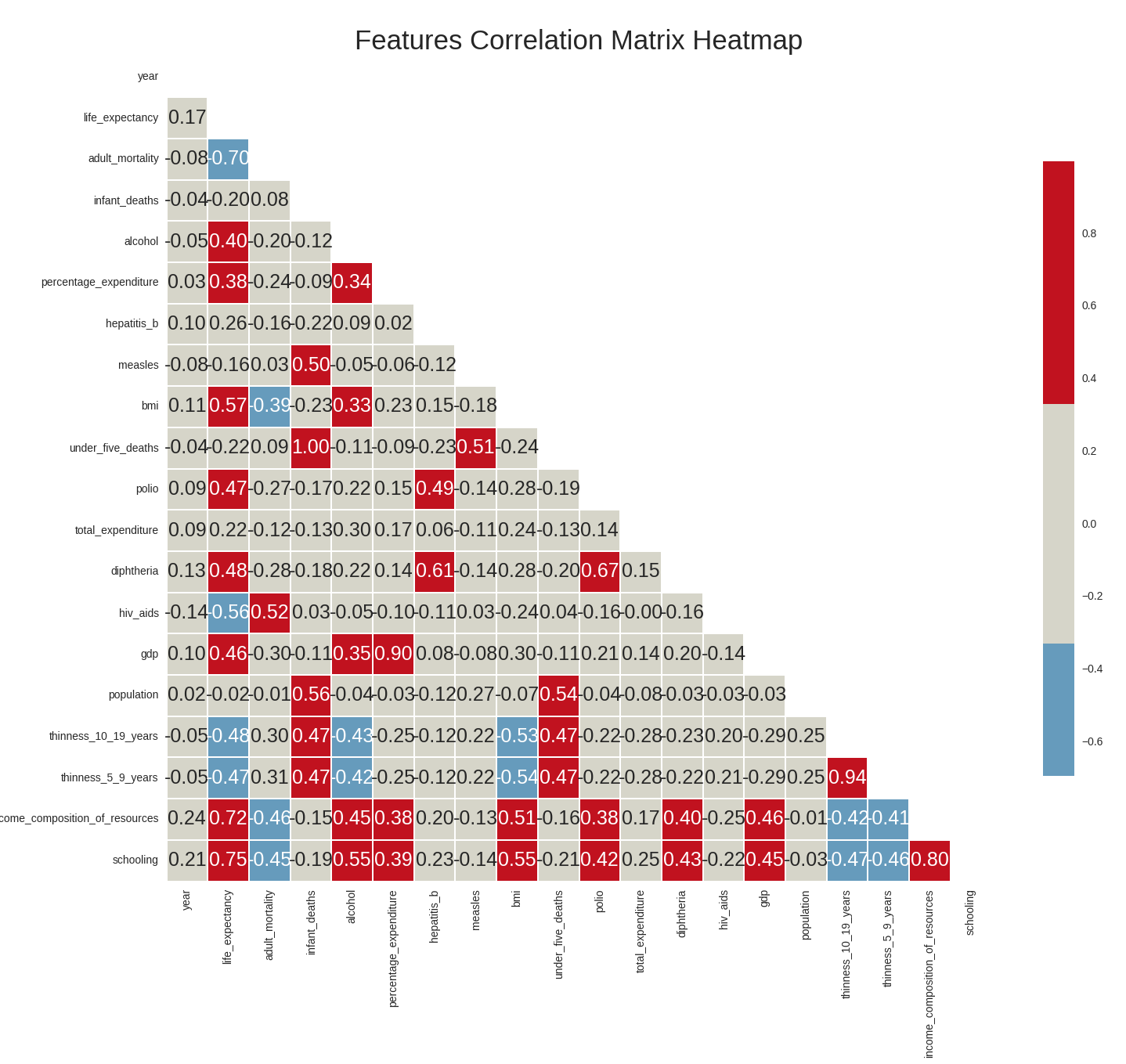
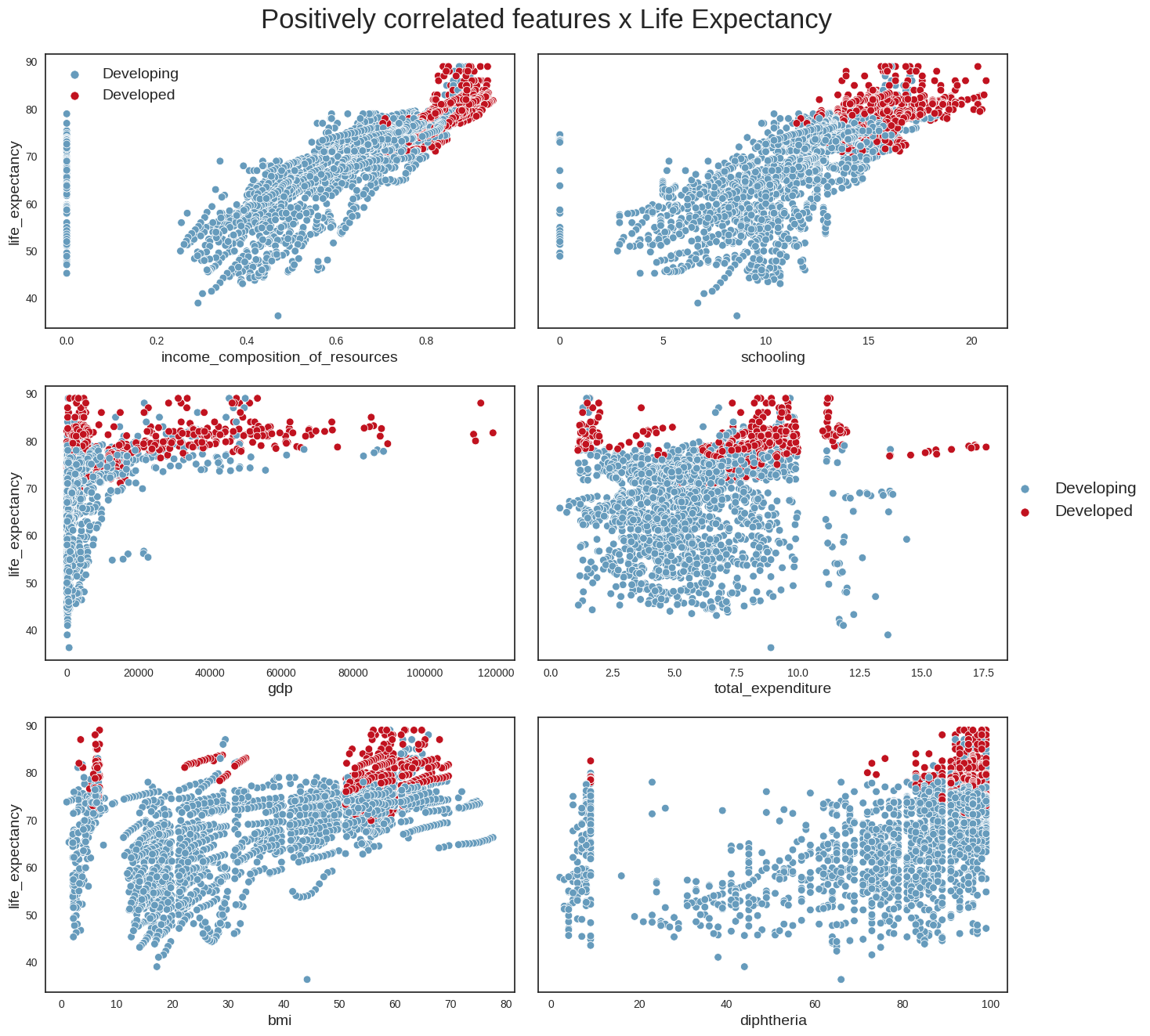
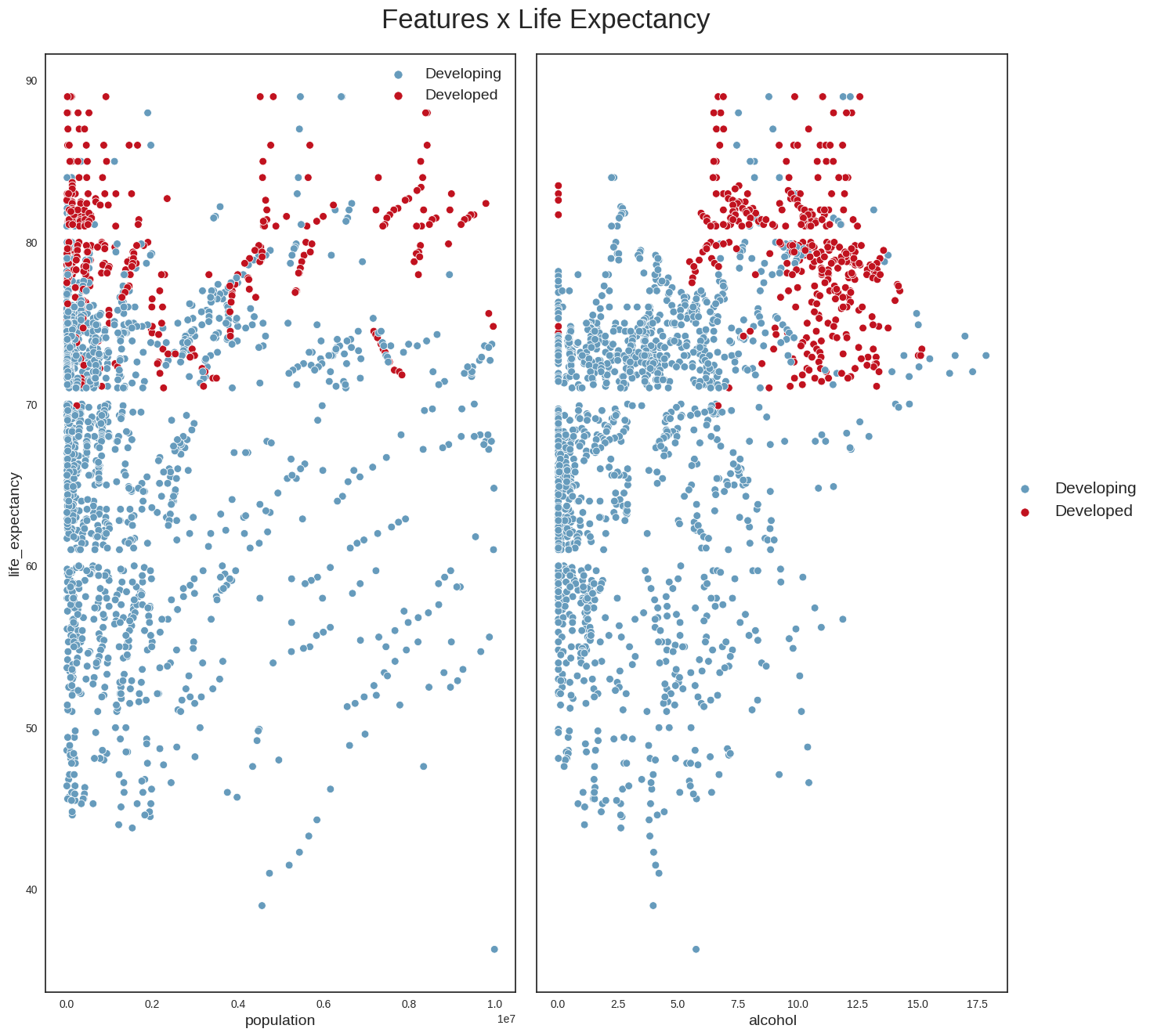
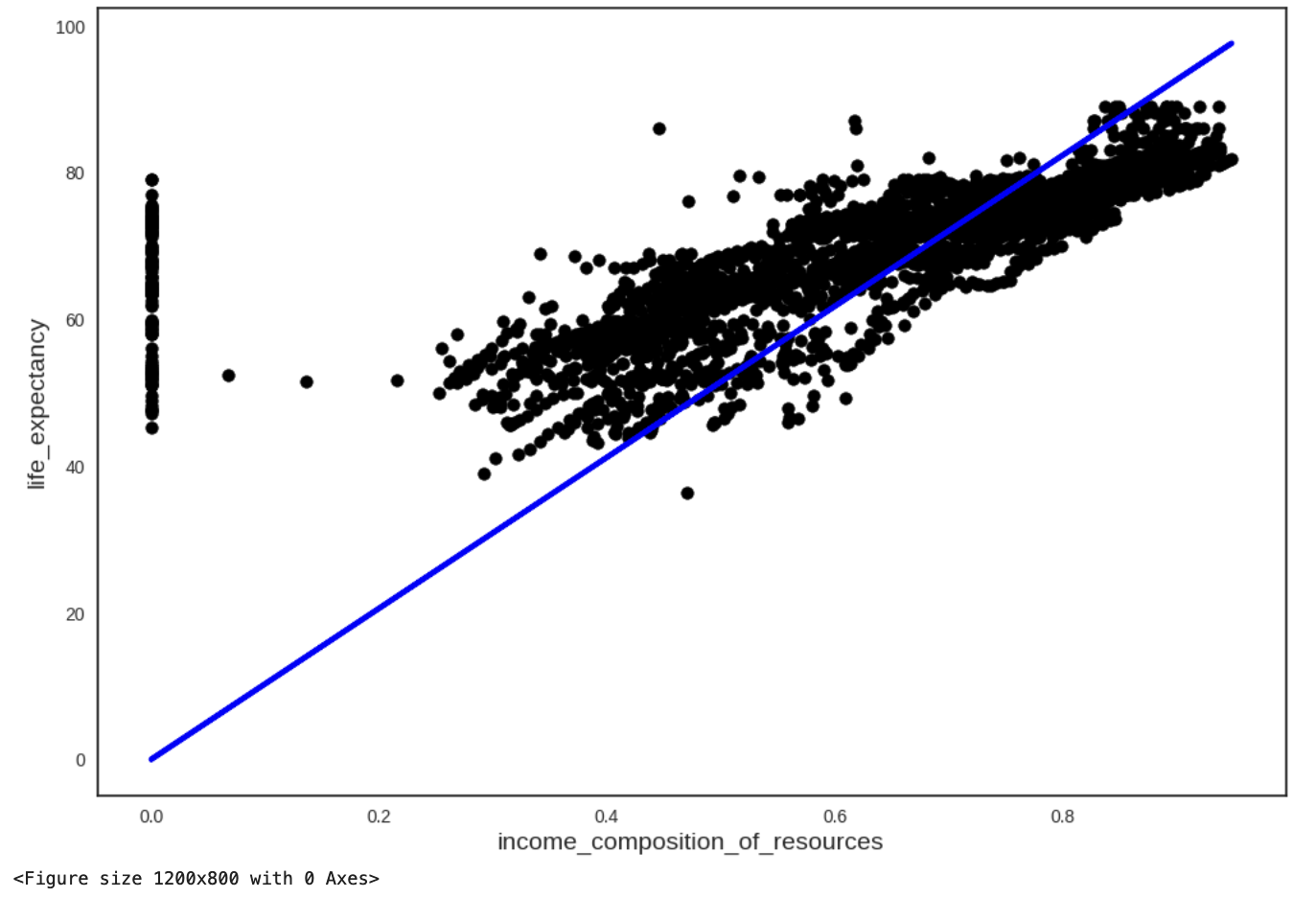
Your selected dataframe has 22 columns.
There are 14 columns that have missing values.| Missing Values | % of Total Values | |
|---|---|---|
| Population | 652 | 22.2 |
| Hepatitis B | 553 | 18.8 |
| GDP | 448 | 15.2 |
| Total expenditure | 226 | 7.7 |
| Alcohol | 194 | 6.6 |
| Income composition of resources | 167 | 5.7 |
| Schooling | 163 | 5.5 |
| BMI | 34 | 1.2 |
| thinness 1-19 years | 34 | 1.2 |
| thinness 5-9 years | 34 | 1.2 |
| Polio | 19 | 0.6 |
| Diphtheria | 19 | 0.6 |
| Life expectancy | 10 | 0.3 |
| Adult Mortality | 10 | 0.3 |