🗓️ Week 07
Machine Learning I
DS101 – Fundamentals of Data Science
27 Feb 2023
⏪ The simple linear model from W05
Let’s revisit the simple linear model from W05:
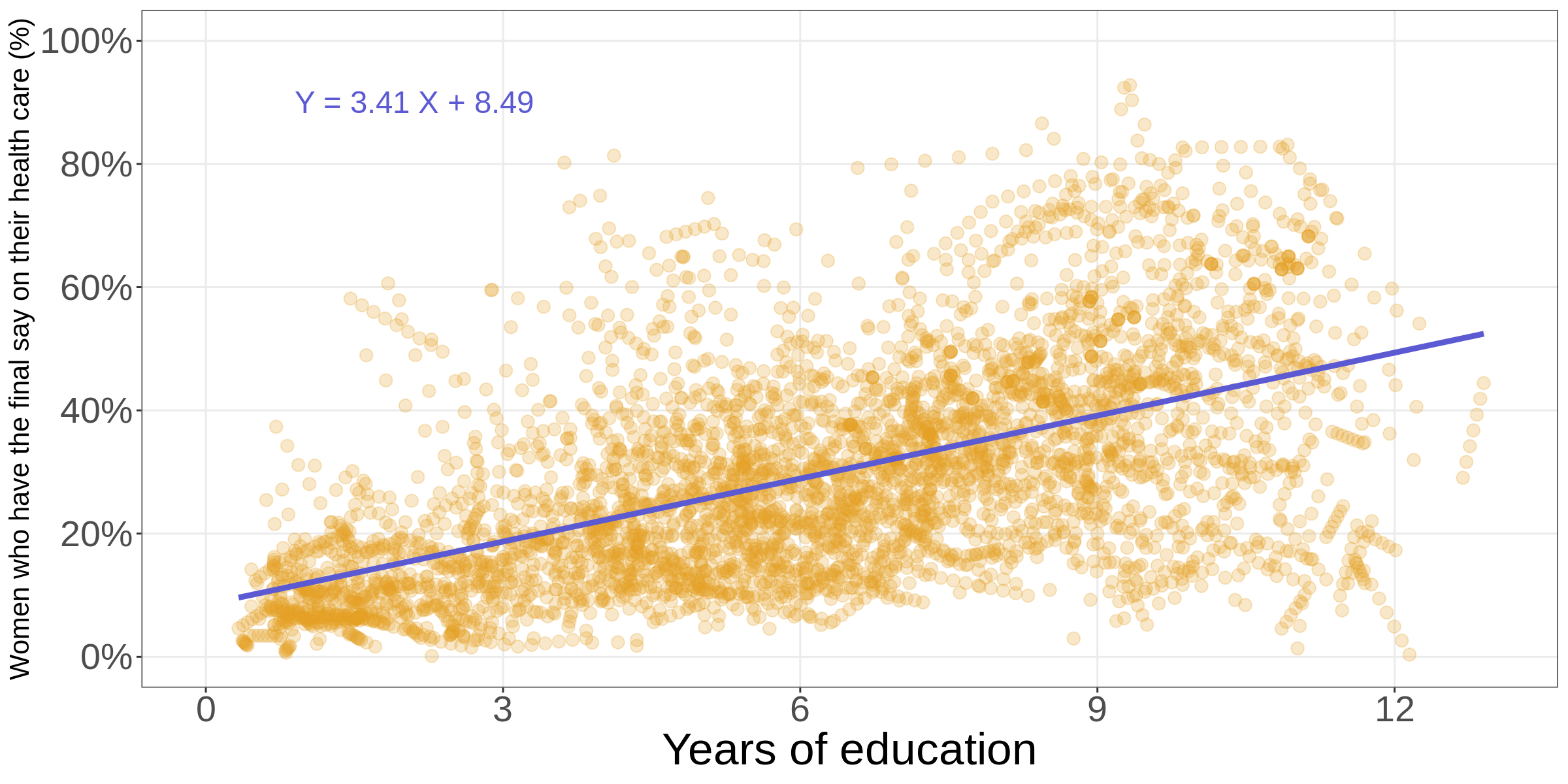
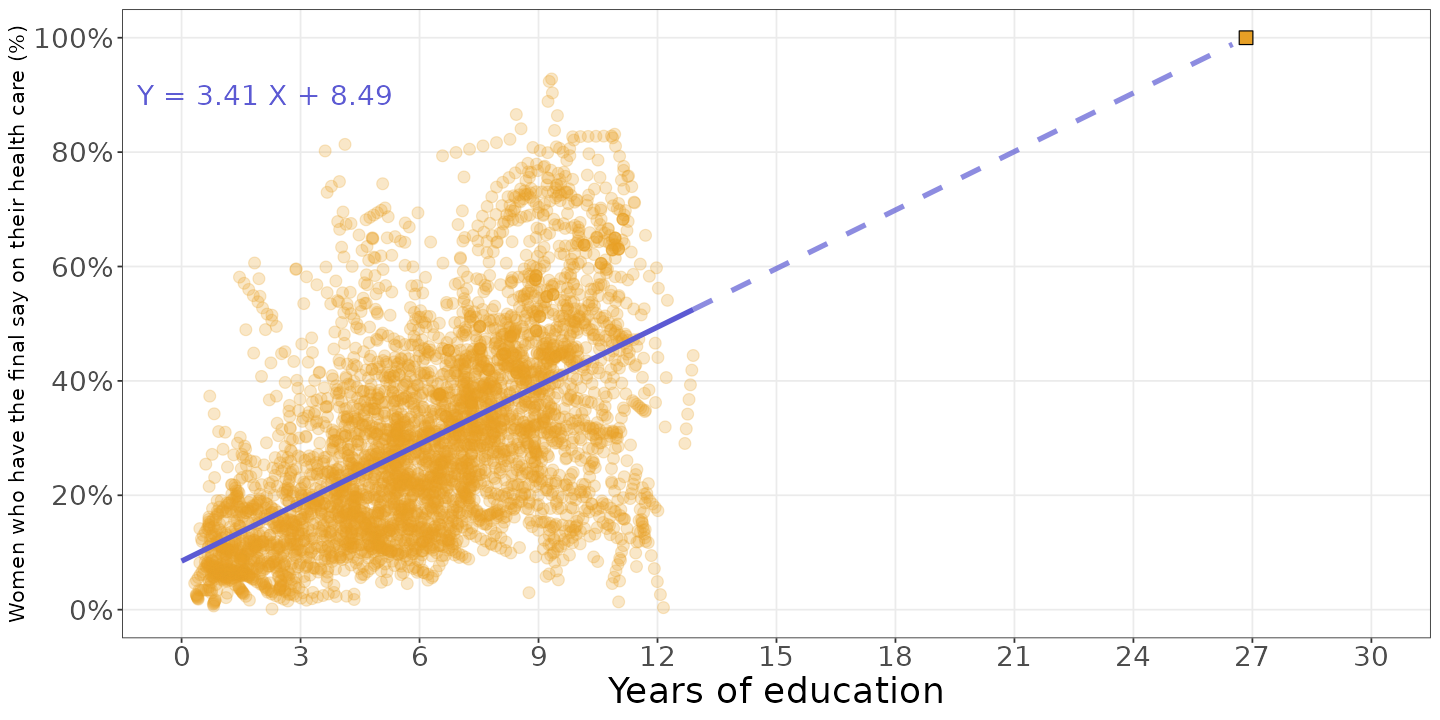
What happens when we extrapolate?
Under what conditions would this model predict a decision power of 100%?
How it works

One Practical Example
Suppose you want to be alerted when politicians spend their additional allowances unlawfully: travel costs, catering functions, stationery and postage costs, etc…


How would you approach this problem?
What is in the receipt?
- Date of the transaction
- Amount of money spent
- Description of the transaction
- Category of the transaction
- Address of the merchant
All of this information constitutes our input.
Side story
There was an open source crowdfunded project to perform exactly this, using data from the Brazilian congress.
Side story

Side story

Time for coffee ☕

After the break:
- Example of supervised learning algorithms
- Self-supervised learning
The Logistic Regression model
Consider a binary response:
\[ Y = \begin{cases} 0 \\ 1 \end{cases} \]
We model the probability that \(Y = 1\) using the logistic function (aka. sigmoid curve):
\[ Pr(Y = 1|X) = p(X) = \frac{e^{\beta_0 + \beta_1X}}{1 + e^{\beta_0 + \beta_1 X}} \]

The Decision Tree model

The Support Vector Machine model
Say you have a dataset with two classes of points:

The Support Vector Machine model
The goal is to find a line that separates the two classes of points:

The Support Vector Machine model
It can get more complicated than just a line:

Neural Networks

Attention

- The Transformer architecture is a deep learning model that uses attention to learn contextual relationships between words in a text.
- It has revolutionized the field of Natural Language Processing (NLP).
